








冒頭の動画は,ホーミー 読経で引用した英語版 Wikipedia "Overtone singing" にあるオーディオファイル,上から四つ目の Sygyt in tuva のソノグラムである.ソノグラムはスペクトルの時間変化を表すものだが,2本のスペクトル線が顕著で,まさにひとりデュエット.通奏低音の周波数は一定だが,それに次ぐ高音の周波数は階段を上下し,見たところはバロック音楽みたい.
このメカニズムを Keys to Overtone Singing にあるスライドに基づいて自分なりに考えてみた (このスライドにはナレーションがないので,間違った解釈かもしれない).
人声のスペクトルは複数の山を持ち,周波数の低い順に,第一フォルマント,第二フォルマント…と呼び,F1, F2と表記する.

日本人の母音 a i u e o の発声の F1, F2 を平面にプロットすると,下の図のように分布する.女声は男声より周波数が高く,また個人差があるが各母音はそれぞれ黒い太線で囲んだあたりに分布するとにかく,F1/ F2 の周波数比は母音により異なるのがミソである.

どの母音を発声するかは,口の構え・舌の位置などで決まる.自分で発生してみればわかることだが,図示すれば下のようになる (a href="http://urawaza.sogawakun.net/?eid=10">http://urawaza.sogawakun.net/?eid=10による).冒頭の動画でも,低音は o,高音は i の発音に聞こえる.
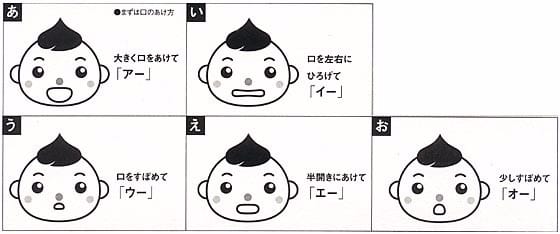
したがってホーミー をマスターしていれば,F1 を一定周波数に保って,すなわち低音部の音高を一定にして,口の構え・舌の位置を変えれば,高音部だけを変化させることができる,すなわち高音部でメロディを奏でることができる...という仮設である.
この方法では歌詞は歌えず,スキャットしかできない.先日の読経では高音部がメロディを歌うという感じはなかったが,お経という「歌詞」が決まっている以上,あまり自由度はないということだろう.