テキストマイニング分析ソフトの使用経験(その4)
「KH coder」の使用説明書の通りに、下記URLから、
http://kstat.sakura.ne.jp/dbase/dbase.html
ダウンロードした、
「DoctorQuestion.txt 」で試していただければ良いと思います。ここでは、「コーディングルール」について簡単に述べておきます。
筆者は、
上記URLの画面に表示されている「ダウンロード(医師・患者アンケート)」からダウンロードした「Enquate.xls (sheet名:医師自由文)」の内容を、次の様にまとめコーディングルールとして「themeDoctor.txt」名で保存しました。
-----------------------------------------------------------------------------------------------------------
*患者
患者 or 来院 or 症状 or 悪化 or 説明 or 理解 or 紹介 or 病院 or 病気
*薬剤
ステロイド or 薬 or 副作用 or 漢方薬 or 強い or 薬剤
*診断(治療)
診療 or 診断 or 疾患 or 適切 or 診療 or 丁寧 or 方法 or 原因 or 診察 or 検査
*医師
前 or 医師 or 専門医 or レベル or 報酬 or 病状
-----------------------------------------------------------------------------------------------------------
(上記をコピーし「メモ帳」にペーストし「themeDoctor.txt」名で保存して使用する)
「KH coder」の操作:
「ツール」→「コーディング」→「章・節・段落ごとの集計」→
図6 コード出現率の集計手順
① コーディングルール・ファイル : 「参照」をクリック
② コーディング単位 : 「段落」を選択
③ セル内容 : 「度数とパ^セント」を選択
④ 「集計」をクリック
出力結果は下記の図6の様になります(編集しています)。
図6 コード出現率の編集結果
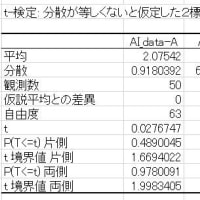
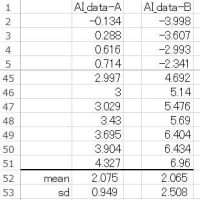
カイ二乗値(Chi-squared)のp値は、例えば、
下記の分割表(2×3)から求められます。
--------------------------------------------------
病院規模 患者 対照
小規模病院 40 72-40=32
中規模病院 11 17-11= 6
大規模病院 8 17- 8= 9
---------------------------------------------------
「KH coder」の使用方法については、このくらいにして、次回からは、「KH coder」に用意されている対応分析、多次元尺度構成法、階層的クラスター分析、共起ネットワークについて考えたいと思います。
次回に続く!