








Improving health careのコンセプトを真に理解して解析するためのもっとも大事なコアの部分です。
これは、臨床研究で言えば、FINERたてて、Null hypothesisとHaを決めてDataの検定を決定するときのコアだと思っていただければと思います。
医療の質と改善の学問はかなり楽しいです。これは・・・自分のような研究者も好きで、Activitistでもあり、教育が臨床が好きな人に向いているとしか思えません。
COVID-19で辛いことが多いですが、前向きに、全ての仕事に感謝して取り組みます。
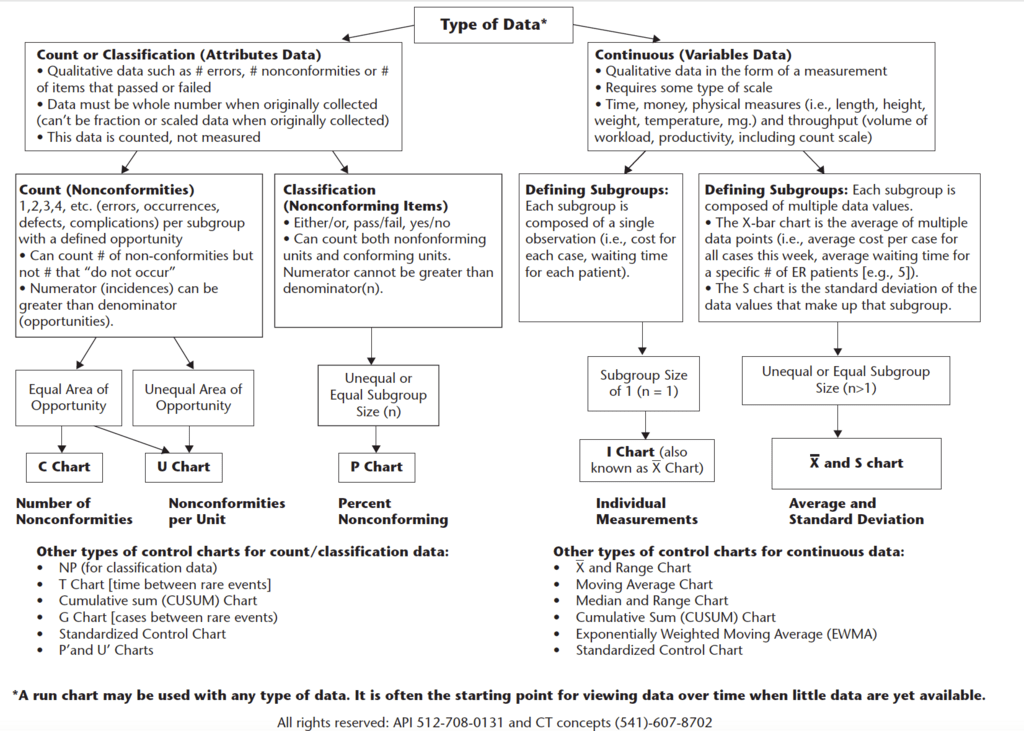
一見わかりにくいですが、ImprovingのためのDataはAtrributes data(BinaryやDichotomusやCategolical dataですね)かVariables (Continuous) dataか?を考えます。
この時に大事なことは、CountとMeasureの違いですね。前者は一個二個など数えられること、後者はメジャーで計測するイメージであれば良いかと思います。
さらに極論すればこうなります。

はじめに
まず前提として、物事がうまくいっているかどうかをみたい時に、折れ線グラフを作ってよくあらわしますよね。この折れ線グラフを走らせたものをRun chartと仰々しく名前がついております・・。(一瞬、なんのことかわかりませんでした)。その折れ線グラフの解釈をより正確に行い、介入やマネージメンに用いるためにControl chartが作られたといえます。
Control Chart
Control chartはRun chartの延長線上にあるのでRun chartがもつすべてのことを含んでいる。医療のプロセスの平均から3σの距離に上限管理限界UCLと下限管理限界LCLを追加したものである.これは,プロセスの能力を示し,プロセスが許容されるパラメータの範囲内にあるかどうかを監視するのに役立つ.
次に
評価したいOutcomeがmeasurement/VariavleかAttributeかを考えます。前者は主に連続変数、後者はいわゆるカテゴリカルデータです。
ここでは前者をまず考えます。
わかりやすくいうと、横軸に日付やイベント数を例えば書いたとして、それがサブグループであれそのサブグループの中の平均や標準偏差を見ることができますね。(その日の血液培養陽性率とか)その場合はXBar-Chartを使うことになるわけです。
XBar Chartについて
極論すると、Xbarの意味は、”sample mean”という意味ですので、その値は集団の結果であるはずです。なので連続変数で集団の値であればX-Bar chartを選択します。そして、その中でもXbar-RかXbar-Sに別れます。
・Xbar-R
ここも極論すると、Xbar-R generates a sub-chart of the Range of the values within each subgroup
Xbar-R Chartはその集団のRange(変化の幅:最大ー最小)を反映したグラフを下にもう一つつけます。なので、Xbar R (rangeのR)Chartなんですね。例:CBCの採血からの表示時間を1日3つのランダムサンプルをとるとして、1日目が72、78、84分だとする、この場合Rは84-72=12分。これを別のChart として表示していきます。Boxplotsで表示も可能でしょう。
・Xbar-S
ここもさらに極論するとXBar-S uses the StdDev of the within-group measurements for the control limits or Sigmas。
要するに、グループ内の標準偏差を用いて表示します。
そこで、はて?それでどう使い分けるのか?と気になると思います。これは慣習的に(きっと深い意味があるのかもしれませんが、P-valueと一緒です)If subgroups sizes>10, use Xbar-S、そのサブグループのサンプル数が10を超える場合はXbar-S Chartを使うということになっています。
まとめますと、X-Bar Chartsを使うときは!
1)Distribution: Normal できれば
2)Data type: MeasurementsつまりContinuous data
3)Data group type: Rational subgroups >1 observation、基本2以上。10を超えるとXbarーRからXbarーSへ変更
と極論で斬ると良いでしょう。ふぅ、やっと頭の整理がつきました。
IR-chart(I chart, Xbar chart)について
ここがまた当初混乱の元ですが、このI chartは色々な名前があります。そもそもIndividual dataに対して用います、根本原則でIndividualとはサブグループのn=1になります。(つまり、横軸は日付で縦軸は体重などの場合ですね)。が上記のようにRangeがついたらIにRがついてIRです。また、それらは単にXbar-chartと呼ばれることもあります。これらなんと全て同じ意味です。自分の名前に少し圧倒されたように初学者が陥りやすいところです。日常でよく見るものなので基本中の基本のChartなので深く考えずに上記名前は全て同じ!と理解すると良いでしょう(この辺りは、日本語の教科書もなく、ネットにも見られないので勝手に極論します)
P-chartについて
- Binary Outcome!!
- - Y軸はパーセンテージ/比率になる
- σとcontrol limitは、標準誤差に基づく。
- 二項分布
- 各ポイントにはそれぞれのCLがある
- 狭い限界≠変動性が減少
- 大規模サンプルサイズ
- CLからプロセスの予測ができない(同じものを除く
サンプルサイズ)
- 能力は全体の割合
- Maximum subgroup size: When n>1000 and p>.1%, use an IR-chart instead of a p-chart. The control limits on the p-chart will be too narrow. 母集団が大きくて1000を超えたり、p>0.01→代わりにIR-chartを使う。
- Rare events: When p <1.5% and between events or opportunities between events plotted on an IR-chart or specialized chart such as t-chart)
- P should be <50%: Customarily, we chart “non-conformities”, but if p>50%, then reverse the measure and chart conformities instead. 起こる確率は50%未満でないといけなくて、それより大きい場合は分母の対象を逆に。
1) Lloyd P. Provost、 Sandra MurrayThe Health Care Data Guide: Learning from Data for Improvement より引用
P-chart, and U-chart/C-chartの違い
ここでも極論すると、P-chartは教科書的には、Classification of items/unitsと書かれていますが簡単にいうとBinominal distributionをとるものを使います。Yes or no、Pass/ Failなどのアウトカムです。調査した数のうち何らかの属性を持つ項目の数と持たない数がはっきりとわかる場合ですね。例えば、帝王切開数/全出産数などが良い例です。
次に、UとC-chartはPoisson分布をとることが前提です。(Poisson分布については基本なので、また時間のあるときに書きます)。簡単にいうと、エラーやアクシデント、など時空間の領域または調査単位で発生した事象の数といえます。
UとC-chartは
- The incidents are counts (whole numbers) Event のカウント!
- Incidents at any one place or time are independent of incidents at other places or times:その場所や時間で発生した出来事は他の時空間(笑)とは独立している。
- The area of opportunity (region) is well defined (との機会の領域は明確になっている、その施設内や部門内などがわかりやすいかも)
- The chance of an incident at any one place or time is small(そのイベントが起きてしまう確率は低い)
- The area of opportunity (region) for each subgroup is: Constant! (そのエリアや部門が変動する場合は確率が変わるので、一定の場合は前者はC-chartに、変動する場合は後者はU-chartになる)下を参照
**勝手な覚え方、CはCONSTANT!でCOUNT!です、UはUnstableのU!!
C-chartとU-chartの違い:大事。エラーが起きる(カウントできる)もので、エラーが起きなかったものを測定できない場合は、U or C chartになる。さらに、U-chart とC-hartの違いは、測定期間中のRiskは同等であると考えられるかどうか。ほぼ同等であれば、C-chartで、unequalであればU-Chartになる。
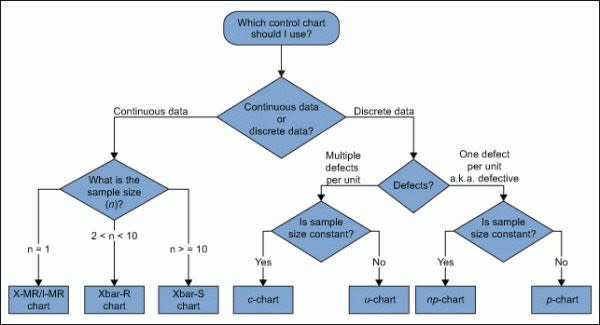
*https://sixsigmastudyguide.com/control-chart/ より
前回載せました別のフローチャートではこのようになっております。
教科書で多く見られるのは
平均+幅 Xbar+R chart
平均+σ Xbar+S chart
個々の値+Range chart はXmR chartを選択
*パーセンテージにご注意
Percentageはcontinuous measuresに見えるが、多くの場合は違う。ここポイント。
- 小数点があり、スケールが連続しているので連続データのように見えますよね。
-例えば、18.3%の患者に有害な転帰があった- アウトカムの分類は実際にはBinaryです(Bernoulliプロセス)。
- しかし、時には本当に連続していることもあり、その代表例は体脂肪率。
- サブグループが非常に大きい場合はp-チャートの管理限界が非常に狭くなるわけなので見かけ上の有意な管理外シグナル(コントロールチャート上で意味のある)を得ることができてしまいます。これは、研究における大規模な標本サイズと似ていて、小さな違いは統計的には有意であっても、臨床的には実際には全然意味がない場合を理解。
- ガイドライン的には サブグループ(分母)が1000以上の場合、IR-チャート変更すべき
Donald Wheeler says when in doubt, you can use the IR chart for any type of data: counts, rates, events, measurements, etc.
Wheeler先生はおっしゃったわけです、迷ったら、数、割合、イベント、計測数あらゆるものを試してとりあえず表してみろ。と。




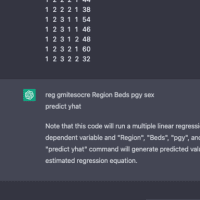
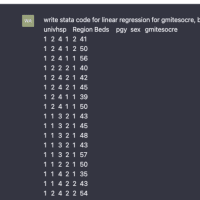
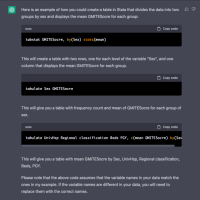
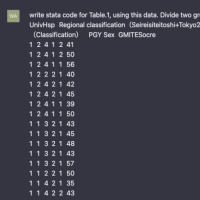
※コメント投稿者のブログIDはブログ作成者のみに通知されます