第Ⅲ部:第8章 要約統計量(Summary)による効果量の計算
ここでは、”Free Online Calculator”を利用し、”summary data”から効果量(ES:Effect Size)を求める方法を紹介しています。最近の学術誌などでは、要約統計量にESの記載が多く見られるようになり、また、査読者からESの記載を求められることが多くなってきています。そこで、
知りえた要約統計量からESを求める方法を具体的な例題でやってみたいと思います。
既に、
「第Ⅲ部:第6章-1 独立2標本の t-検定の方法」では、下記の”Free Online Calculator”でその方法を紹介しています。
***
# 「Psychometrica の事例」
https://www.psychometrica.de/effect_size.html
このサイトでは、2群間の t検定によるESの計算を下記により計算します、
・ サンプルサイズが同じとき(Cohen’s d and Glass Δ)→[1] を選択
・ サンプルサイズが異なるとき (Cohen's d, Hedges' g)→[2] を選択
上記[1] の場合(2 つのグループの n が同じである場合);
そのESは、「Cohenのd」 と呼ばれ、共通の標準偏差に関するグループ間の差を表します。
上記[2] の場合(2 つのグループの n が異なる場合);
サンプルサイズの重みで調整することにより、標準偏差の正のバイアスを修正した「Cohenのd」 と全体的に同じで、修正された測定値であることを示しています。
上記[1][2]での、CLES(McGraw & Wong, 1992) はノンパラメトリックな効果サイズです。
第8章-1:要約統計量(Summary)による効果量(1)
この章では、下記の"Free Online Calculator"を紹介しますので、下記サイトにアクセスして下さい。
# 「Psychometrica の事例」
https://www.psychometrica.de/effect_size.html
上記サイトから、下記の「3」を選択して下さい。
# 3. Effect size for mean differences of groups with unequal sample size within a pre-post-control
上記[3]の場合、実験グループと対照グループの平均差のESを求めます。
例えば、介入研究で、2 つのグループ (例えば、実験グループと対照グループ) を比較するときなどに提案されている方法です(retest-postest-Control design)。
この様な場合、両方のグループの効果サイズを計算することが考えられますが、”Carlson & Smith, 1999”によると、Pre-Postの平均の差を重み付けすることを主張しています。
次の簡単な例題で試してみましょう。
図1 PreTest - PosTest Data

本例でのsample size は同じですが、異なるときは自動的に修正されます。
図2 入力と出力の画面

ESは、Morris (2008)=2.002 と Klauer(2001)=2.661 と出力され、共にHedge の g の差を表します。
ここで、単純な統計的検定として、2つのグループの前後差(diff.=Post-Pre)に注目するなら、図3のようになります。
図3 2つの前後差(diff.=Post-Pre)の比較

すなわち、効果量 ES_d=2.697 となります。
一方、
2つの前後差(diff.=Post-Pre)を独立2群のt検定を行うと次のようになりました。
図4 独立2群のt検定(前後差 diff.=Post-Pre)の結果
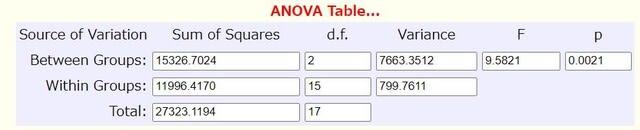
2群の「diff」(図1)から、その独立2群のt検定の結果は次の通りでした。
...diff......Treat Group......Control
..mean..........65...............-3.8
...sd............22.5.............28.2
....n...............5.................5
df=8
t value=4.2493
p value=0.0028
よって、effect r は次式のより求めることができます。
√t^2/t^2+df =0.8324
この計算を、”Free Online Calculator”で確かめたいなら、下記Web site を試してみて下さい。
UCCS:
https://lbecker.uccs.edu/
このサイトでは、下記の要約統計量で計算できます。
(1) means and standard deviations
(2) independent groups t test values and df
図5 上記(1)の場合

図6 上記(2)の場合
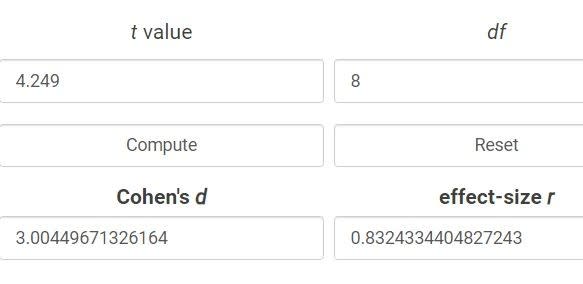
要約統計量の丸めにより多少の違いがあります。
その他として、次のようなsite があります。
# Practical Meta-Analysis Effect Size Calculator
https://www.campbellcollaboration.org/escalc/html/EffectSizeCalculator-R3.php
# Effect size converter
https://www.escal.site/
次回に続く!
文責:ISL assistant staff, KUMI