








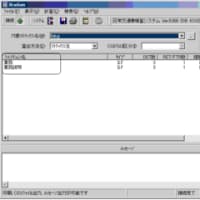
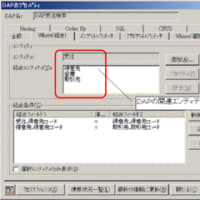
XupperⅡAdvancedにデータ管理者支援機能(DAassist)というものが存在します。この機能は登録されているフィールド名(やフィールド正式名、フィールド物理名)が命名規約どおりに命名されているかどうかをチェックする機能です。
データ整理の第1回「全社レベルのデータ整備 第1歩は項目名称の統一から」で、こんな機能を提供していますというご紹介だけはしていましたが、具体的な内容については言及しませんでした。
ここで、簡単に機能を説明していきたいと思います。
まず、このデータ管理者支援機能の目的ですが、データ項目の標準化を行い、異音同義語や同音異義語の発生を抑止することを目的としています。
また、命名体系に従って、フィールド名が付与されているかをチェックすることにより、フィールド名の標準化を推進していくことを目的としています。
フィールドの命名体系については、「修飾語」+「主要語」+「修飾語」+「区分語」という体系を前提としています。
・修飾語とは、データ項目の意味を区分する言葉で、任意で複数指定可能とします。
・主用語とは、管理する対象を表す言葉で、必須で単数指定とします。
・区分語とは、値の種類を表す言葉で、必須で単数指定とします。
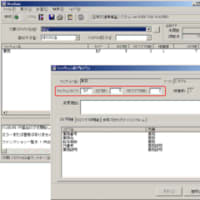
処理の前提として、フィールド名に使用可能な用語(単語)を用語マスタに登録する必要があります。
用語とは、上記「修飾語」、「主要語」、「区分語」の各語でどのような言葉をとるかを予め登録したものをいいます。
一つの用語が、「修飾語」でもあり「主要語」でも使われるという場合もあります。
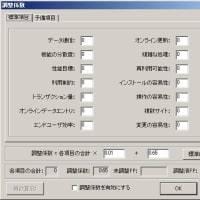
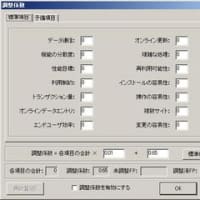
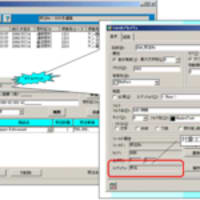
チェック方法ですが、まず、前提となる命名体系どおりになっているかどうかをチェックします。その際、用語として登録されている「修飾語」「主要語」「区分語」かどうかを合わせてチェックします。
チェックの手順は以下の通りです。
①用語マスタに登録されている区分語が使用されているか?
フィールド名の後方向から、区分語に合致しているかどうかチェックします。
②用語マスタに登録されている修飾語が使用されているか?
区分語に合致している文字列を除いたフィールド名の後方向から、修飾語に合致しているかどうかチェックします。
合致した修飾語がある場合は、再度修飾語に合致する文字列があるかチェックします。
③用語マスタに登録されている主要語が使用されているか?
区分語に合致している文字列及び修飾語に合致した文字列を除いたフィールド名の後方向から、主要語に合致しているかどうかチェックします。
④用語マスタに登録されている修飾語が使用されているか?
区分語、区分語の修飾語、主要語に合致している文字列を除いたフィールド名の後方向から、修飾語に合致しているかどうかチェックします。
合致した修飾語がある場合は、再度修飾語に合致する文字列があるかチェックします。
データ整理の第1回「全社レベルのデータ整備 第1歩は項目名称の統一から」で、こんな機能を提供していますというご紹介だけはしていましたが、具体的な内容については言及しませんでした。
ここで、簡単に機能を説明していきたいと思います。
まず、このデータ管理者支援機能の目的ですが、データ項目の標準化を行い、異音同義語や同音異義語の発生を抑止することを目的としています。
また、命名体系に従って、フィールド名が付与されているかをチェックすることにより、フィールド名の標準化を推進していくことを目的としています。
フィールドの命名体系については、「修飾語」+「主要語」+「修飾語」+「区分語」という体系を前提としています。
・修飾語とは、データ項目の意味を区分する言葉で、任意で複数指定可能とします。
・主用語とは、管理する対象を表す言葉で、必須で単数指定とします。
・区分語とは、値の種類を表す言葉で、必須で単数指定とします。
処理の前提として、フィールド名に使用可能な用語(単語)を用語マスタに登録する必要があります。
用語とは、上記「修飾語」、「主要語」、「区分語」の各語でどのような言葉をとるかを予め登録したものをいいます。
一つの用語が、「修飾語」でもあり「主要語」でも使われるという場合もあります。
チェック方法ですが、まず、前提となる命名体系どおりになっているかどうかをチェックします。その際、用語として登録されている「修飾語」「主要語」「区分語」かどうかを合わせてチェックします。
チェックの手順は以下の通りです。
①用語マスタに登録されている区分語が使用されているか?
フィールド名の後方向から、区分語に合致しているかどうかチェックします。
②用語マスタに登録されている修飾語が使用されているか?
区分語に合致している文字列を除いたフィールド名の後方向から、修飾語に合致しているかどうかチェックします。
合致した修飾語がある場合は、再度修飾語に合致する文字列があるかチェックします。
③用語マスタに登録されている主要語が使用されているか?
区分語に合致している文字列及び修飾語に合致した文字列を除いたフィールド名の後方向から、主要語に合致しているかどうかチェックします。
④用語マスタに登録されている修飾語が使用されているか?
区分語、区分語の修飾語、主要語に合致している文字列を除いたフィールド名の後方向から、修飾語に合致しているかどうかチェックします。
合致した修飾語がある場合は、再度修飾語に合致する文字列があるかチェックします。







※コメント投稿者のブログIDはブログ作成者のみに通知されます