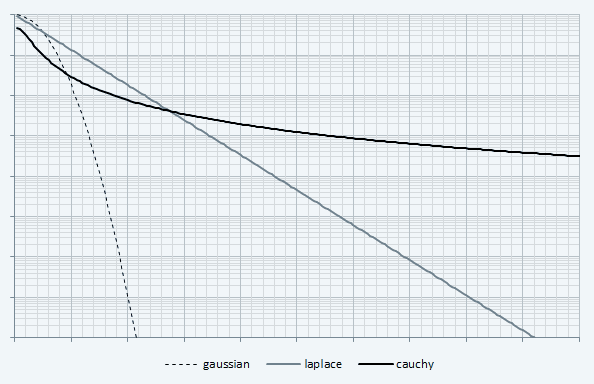
このシリーズで広義のt分布(以下tdwsと略す)と言ってるのは大雑把に言うと確率密度関数fが次のような形で、

(確率密度関数だから)全区間Rで積分すると1になる(超)関数のことである。

こういうのを一般に何と呼ぶのかは、たぶん本職の物理屋とか数学屋の人が知ってるはずである。わたしは本職ではないし、本職でなければ名前なんぞ本当はどうだっていいし(笑)、Google先生に訊いても要領を得ないし、今となっては身近に訊ける人もいない、というわけで単に直観的なわかりやすさからtdwsと呼んでおく。
通常のt分布(以下tdns)はベキのpが(1+k)/2である。正の整数kが自由度と呼ばれる。k=1のときがCauchy分布である。tdnsでは他のパラメータもk(と積分1の条件)に依存して定まるので、kは0以下にはならない(k→0でδ超関数になる)。つまりp=1/2以下ではtdnsは定義されない。手持ちのデータから読み取ってみる限りだと変動分布の裾はpが1/2未満なので(てことはCauchy分布よりさらに裾が厚いのである)、上式のようなtdwsを考える必要があるというわけである。
そんなエエカゲンなことでいいのかといって、今の場合t分布の統計学的な意味は本質的ではない。単に両側べき乗分布と呼べるものを作りたいだけである。むろんパラメータεの値によって、中心(x=0)付近の形が、したがって各種統計量も変わってしまうわけだが、変動分布の場合中心付近は、標本の大多数を占めるLaplace分布の標本で覆い隠されてしまうので、どっちみち概形はわからないし、わかったところで大勢に影響はない。肝心なのは裾の方がベキ乗で落ちてくれることで、中心付近はいい塩梅にぐにゃっててくれればいいのである(笑)──とはいえ最終的にはパラメタ・フィッティングが必要である。パラメータεの値によって標本全体に占めるtdwsの比率が変わってくるからである。
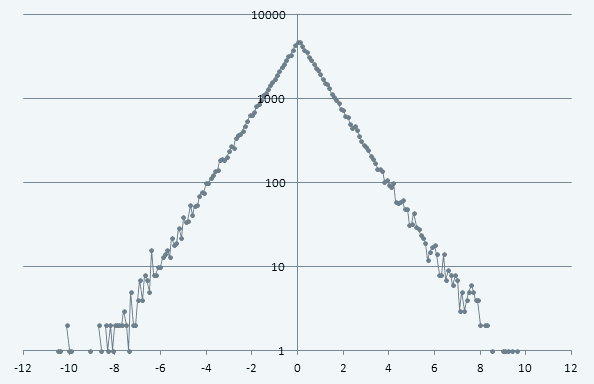
まあ何にせよ(2)の順位-変動グラフに、目分量で(笑)フィットさせたtdwsのサンプルを重ね合わせてみると、以下のようにバッチリ合う。tdwsでないとこうは合わないのである。

実を言うとこのグラフはtdwsの計算(正確に言うとtdwsにしたがう乱数の計算)がちょっと間違ってて、それで一番端の値がちょっと大きくなってしまっているのだが、概形としてはこの通りだし、グラフ作り直すのがめんどくさい(笑)ので、このまま出してしまう。
(確率密度関数だから)全区間Rで積分すると1になる(超)関数のことである。
こういうのを一般に何と呼ぶのかは、たぶん本職の物理屋とか数学屋の人が知ってるはずである。わたしは本職ではないし、本職でなければ名前なんぞ本当はどうだっていいし(笑)、Google先生に訊いても要領を得ないし、今となっては身近に訊ける人もいない、というわけで単に直観的なわかりやすさからtdwsと呼んでおく。
通常のt分布(以下tdns)はベキのpが(1+k)/2である。正の整数kが自由度と呼ばれる。k=1のときがCauchy分布である。tdnsでは他のパラメータもk(と積分1の条件)に依存して定まるので、kは0以下にはならない(k→0でδ超関数になる)。つまりp=1/2以下ではtdnsは定義されない。手持ちのデータから読み取ってみる限りだと変動分布の裾はpが1/2未満なので(てことはCauchy分布よりさらに裾が厚いのである)、上式のようなtdwsを考える必要があるというわけである。
そんなエエカゲンなことでいいのかといって、今の場合t分布の統計学的な意味は本質的ではない。単に両側べき乗分布と呼べるものを作りたいだけである。むろんパラメータεの値によって、中心(x=0)付近の形が、したがって各種統計量も変わってしまうわけだが、変動分布の場合中心付近は、標本の大多数を占めるLaplace分布の標本で覆い隠されてしまうので、どっちみち概形はわからないし、わかったところで大勢に影響はない。肝心なのは裾の方がベキ乗で落ちてくれることで、中心付近はいい塩梅にぐにゃっててくれればいいのである(笑)──とはいえ最終的にはパラメタ・フィッティングが必要である。パラメータεの値によって標本全体に占めるtdwsの比率が変わってくるからである。
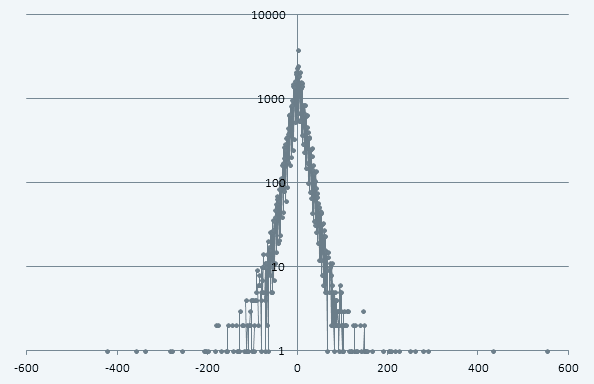
まあ何にせよ(2)の順位-変動グラフに、目分量で(笑)フィットさせたtdwsのサンプルを重ね合わせてみると、以下のようにバッチリ合う。tdwsでないとこうは合わないのである。
実を言うとこのグラフはtdwsの計算(正確に言うとtdwsにしたがう乱数の計算)がちょっと間違ってて、それで一番端の値がちょっと大きくなってしまっているのだが、概形としてはこの通りだし、グラフ作り直すのがめんどくさい(笑)ので、このまま出してしまう。