








トップダウン分析フェースで行なう打ち合わせや取り決めことのすべてがモデリングソース(情報源)となるといっても過言ではありません。
すべての情報をこの段階で得ようとすることは賢明ではないことはすでに述べました。
可能なかぎり情報を収集する努力は必要ですがたとえ結果が20点であろうと30点であろうと嘆く必要はありません。情報量が20点なら20点なりに、その段階でのデータモデルを作成していくことはできます。
間違っても、すべての情報が出揃ってからデータモデリングしようなどとは思わないでください。
エンティティ関連図の完成形を一度だけで書こうとすることは、データモデルをなぜ構築するのか、どのような効果があるのかをまったく無視した方法です。
モデル化することによって目に見えるようになるということは、たった一行の文章の解釈の結果がデータモデル上で反映されているということです。
多数のSEが必要となる大規模システムであればなおさらのこと、イメージの共有化を図ることが重要な意味を持つことになるわけで、エンティティ関連図に表現されてはじめて、認識のズレを調整することが可能になるのです。
データモデルを作成する場合のとまどいを軽減するために、いくつかのアドバイスがあります。どこから手をつけてよいのかわからない場合には、以下の方法を参考にしてください。
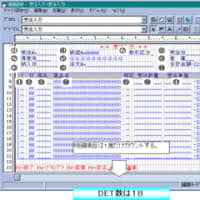
● マスターファイルになりそうなエンティティ(リソース系エンティティ)を洗い出します。
<<エンティティ候補の抽出>> <<エンティティの過不足チェック>> <<エンティティの妥当性検討>>
トップダウンモデリングの段階で、ファイルという言葉は不謹慎なようにも思えますが、最後はファイルになるのですから臆することはありません。
トップダウン分析の段階ではまだシステムの運用も検討されておらず、現状分析もそれほど出ているわけではありませんから、リソース系エンティティの抽出を整理ができればそれで十分です。
エンティティが洗い出せれば、
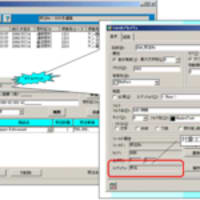
● 各エンティティ間の関連分析を行います。
<<リレーションの存在確認>> <<リレーションの分類>> <<N対Mの解消>> <<従属/参照関係の分析>>
つまり、従属の関係か参照の関係か、または関係がないのかをなどをはっきりさせていけばいいわけです。
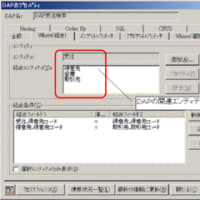
● 抽出したエンティティを順次Xupperに入力する
● 確実に必要となると判断できる項目(フィールド)も同時に登録する
<<属性の定義>>
要否が不確実な項目(フィールド)は、メモを用意して記述しておくか、Xupperに登録してもコメントを付加しておきます。ただし、この段階で属性項目を追加するのは、リソース系エンティティに対してだけです。
この時点でイベント系(トランザクション系)エンティティがエンティティ候補として浮かんだとしても、エンティティ自身の登録と他のエンティティとの関連分析にとどめ、属性項目を安易に追加してはいけません。また、リソース系エンティティに対しても、実績集計項目などのサマリー(集計)項目については、安易に追加してはいけません。 この段階ではあまり難しく考えずに、リソース系エンティティのエンティティ関連図(暫定版)が作成できれば、属性項目が埋まっていなくても合格なのだとお考え下さい。

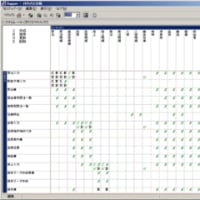
【図1】マスタ系エンティティ関連図のXupperでの定義例








※コメント投稿者のブログIDはブログ作成者のみに通知されます