








(前回)
現在の著作権では、著作権は公表後70年間(国によって多少差がある)なので、1911年版の Britannica 11thは著作権が切れている。それで、Web上では複数のサイトで公開されている。
1.Britannica の 1st から 12th Versionまでの説明
http://onlinebooks.library.upenn.edu/webbin/work?id=olbp16644
2. Wikisource は図も入っているバージョン
https://en.wikisource.org/wiki/1911_Encyclop%C3%A6dia_Britannica
それ以外にも次のようなサイトが見つかる。
https://www.theodora.com/encyclopedia
https://onlinebooks.library.upenn.edu/webbin/metabook?id=britannica11
この中では、2.のWikisourceが図入りであり、テキスト文もかなりしっかりと Verfifiedされているようなので、主にこれを使うことにした。ところが、このサイトは検索するには、何度もクリックしなければならず、かなり不便だ。例えば、Plato を検索するには3度クリックする必要があり、その都度、該当する項目はどこかを探す必要がある。この時、現在のWYSIWYG(What You See Is What You Get)とマウスという標準のMan-Machine インターフェスが足枷になって、操作性が悪くなっている。(この点については、追々批判するが、WYSIWYGベースのツールだけで仕事をするのは、生産性が極めて低い、という事だけは覚えておいて欲しい。)
さて、目的の単語を検索して表示しようとする時、ひたすら手作業でマウスをクリックすることになるが、そういった作業を仕事や研究のためには止むをえないと考えている人がほとんどだが、私はこのような単純作業は人手を介さずに行うべきだ考える。そうは言っても、プログラミングができないとどうすればそのようなことが実現できるか想像がつかないことだろう。
いづれ述べるが、私はかつて SEとしてC言語で数十万行レベルのシステムを幾つか設計しただけでなく、自分でも合計で数十万行ものC言語のコード書いた経験があるので、ソフト的にはどうすればよいのか、たいていの事なら分かる。今回のようなケースでは、手始めにクリック毎にサイトがどのキーワードを使って遷移するのかをチェックすることから始める。そうすると、例えば Plato の場合、最終的に下記のようなサイト(URL)の情報を表示していることが分かる。
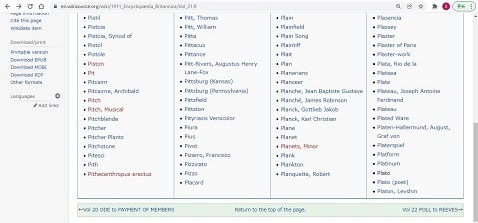
この情報の元になっているのが、上の図に挙げたような項目名とそのURLが明記されているページである。この中身を知るためには、このページをダウンロードして見ればよい。例えば、Plato の場合次の2項目が Plato という名でURLが分かる。
Plato
Plato (poet)
ここまで分かればあとは、至って簡単で次のようにすれば検索システムができる。
1.アルファベット順に項目名が記載されたページを最初から最後までをダウンロードする。
2.ダウンロードされたファイルから項目名とそれに該当するURLをの対比表のテーブルを作成する。
3.検索の操作としては対比表の項目名を探し出し、該当するURLにアクセスすることになる。
このようにどのようにすればいいかという概略のプロセスだけ書けば、あっという間に検索システムが出来上がるように思われるかもしれないが、実際にはいろいろと問題がある。その一つは、ウェbページの文字コードだ。私が使っているWindows 10 システムでは DOSの時代からのソフト資産継承のため、表面上はASCII、Shift-JIS の文字コードが使われている。つまり、英語の場合、ASCII文字以外の文字コード、例えばUTFコード、はそのままでは表面的には扱えないことになる。もっとも内部的にはUTFに移行しているので、システム的には UTFコードも取り扱うことができる。現在のWebの世界では多くの文字コードが使えるが、それでも基本的にはHTMLファイルは ASCIIで記述されている。それ故、項目ページでもASCII文字以外は、漢字も含め、"%"を使って意味不明の文字のように表記される。たとえば、私の近刊書タイトル「中国四千年の策略大全」はUTF-8のタイトルとして次のように表される。
%E4%B8%AD%E5%9B%BD%E5%9B%9B%E5%8D%83%E5%B9%B4%E3%81%AE%E7%AD%96%E7%95%A5%E5%A4%A7%E5%85%A8
Britannica 11th の場合でいえば、例えば、 Aの最初あたりのページに Abu Hanifa という人名がでてくるが、その項目は次の表記となる。
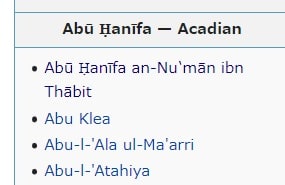
この項目を調べようとした時、マウスでクリックする場合は全く問題ではないが、検索システムで入力しないといけないとなると厄介だ。というのは、通常のキーボードではローマ字以外の文字をエントリーできないからだ。今回作成した検索システムでは Abu Hanifa と入力して検索できるようにしないといけないが、その為には、UTF-8をASCII(つまりShift-JIS)に変換する時にUをUと同等にみなせばよいことになる。
Abū Ḥanīfa an-Nu‛mān ibn Thābit
このような方針で作成したのが Britannica 11th の検索システムである。このシステムは Windows 10のコマンドプロンプト画面で動く。(通常コマンドプロンプト画面は黒地に白抜きの文字だが、この配色は眼にきついので、私はこのように背景を緑系にして白抜きの文字にして使っている。)例えば、Plato を検索した時は画面で [ xga plato ] と打ち込めば次のように表示される。いちいち大文字と小文字を区別するのが手間なので、内部的にはすべて小文字に変換してから検索するので、入力は大文字小文字関係ない。

結果、Platoという項目は合計で7ヶ見つかる。表示したいのはこの内3番目であるので、続けて、[ xga 3 ] と打ち込むことで自動的に Chromeで該当ページが表示される。

当初はここで満足していたのだが、何度か使っている内に、このシステムに不便さを感じた。それは、文字が小さいことだ。若い方には分からないかもしれないが、老年になると小さい文字を長時間読むのが苦痛となる。それで、大きな文字で読みたいのだが、都度Chromeの画面で文字の大きさをいじるのが面倒だ。それで、本検索システムを改造することでそのニーズに対応することにした。このように、プログラミングができると「わがままで、自己中の要望」がいとも簡単に実現できる。
(続く。。。)
現在の著作権では、著作権は公表後70年間(国によって多少差がある)なので、1911年版の Britannica 11thは著作権が切れている。それで、Web上では複数のサイトで公開されている。
1.Britannica の 1st から 12th Versionまでの説明
http://onlinebooks.library.upenn.edu/webbin/work?id=olbp16644
2. Wikisource は図も入っているバージョン
https://en.wikisource.org/wiki/1911_Encyclop%C3%A6dia_Britannica
それ以外にも次のようなサイトが見つかる。
https://www.theodora.com/encyclopedia
https://onlinebooks.library.upenn.edu/webbin/metabook?id=britannica11
この中では、2.のWikisourceが図入りであり、テキスト文もかなりしっかりと Verfifiedされているようなので、主にこれを使うことにした。ところが、このサイトは検索するには、何度もクリックしなければならず、かなり不便だ。例えば、Plato を検索するには3度クリックする必要があり、その都度、該当する項目はどこかを探す必要がある。この時、現在のWYSIWYG(What You See Is What You Get)とマウスという標準のMan-Machine インターフェスが足枷になって、操作性が悪くなっている。(この点については、追々批判するが、WYSIWYGベースのツールだけで仕事をするのは、生産性が極めて低い、という事だけは覚えておいて欲しい。)
さて、目的の単語を検索して表示しようとする時、ひたすら手作業でマウスをクリックすることになるが、そういった作業を仕事や研究のためには止むをえないと考えている人がほとんどだが、私はこのような単純作業は人手を介さずに行うべきだ考える。そうは言っても、プログラミングができないとどうすればそのようなことが実現できるか想像がつかないことだろう。
いづれ述べるが、私はかつて SEとしてC言語で数十万行レベルのシステムを幾つか設計しただけでなく、自分でも合計で数十万行ものC言語のコード書いた経験があるので、ソフト的にはどうすればよいのか、たいていの事なら分かる。今回のようなケースでは、手始めにクリック毎にサイトがどのキーワードを使って遷移するのかをチェックすることから始める。そうすると、例えば Plato の場合、最終的に下記のようなサイト(URL)の情報を表示していることが分かる。
この情報の元になっているのが、上の図に挙げたような項目名とそのURLが明記されているページである。この中身を知るためには、このページをダウンロードして見ればよい。例えば、Plato の場合次の2項目が Plato という名でURLが分かる。
ここまで分かればあとは、至って簡単で次のようにすれば検索システムができる。
1.アルファベット順に項目名が記載されたページを最初から最後までをダウンロードする。
2.ダウンロードされたファイルから項目名とそれに該当するURLをの対比表のテーブルを作成する。
3.検索の操作としては対比表の項目名を探し出し、該当するURLにアクセスすることになる。
このようにどのようにすればいいかという概略のプロセスだけ書けば、あっという間に検索システムが出来上がるように思われるかもしれないが、実際にはいろいろと問題がある。その一つは、ウェbページの文字コードだ。私が使っているWindows 10 システムでは DOSの時代からのソフト資産継承のため、表面上はASCII、Shift-JIS の文字コードが使われている。つまり、英語の場合、ASCII文字以外の文字コード、例えばUTFコード、はそのままでは表面的には扱えないことになる。もっとも内部的にはUTFに移行しているので、システム的には UTFコードも取り扱うことができる。現在のWebの世界では多くの文字コードが使えるが、それでも基本的にはHTMLファイルは ASCIIで記述されている。それ故、項目ページでもASCII文字以外は、漢字も含め、"%"を使って意味不明の文字のように表記される。たとえば、私の近刊書タイトル「中国四千年の策略大全」はUTF-8のタイトルとして次のように表される。
%E4%B8%AD%E5%9B%BD%E5%9B%9B%E5%8D%83%E5%B9%B4%E3%81%AE%E7%AD%96%E7%95%A5%E5%A4%A7%E5%85%A8
Britannica 11th の場合でいえば、例えば、 Aの最初あたりのページに Abu Hanifa という人名がでてくるが、その項目は次の表記となる。
この項目を調べようとした時、マウスでクリックする場合は全く問題ではないが、検索システムで入力しないといけないとなると厄介だ。というのは、通常のキーボードではローマ字以外の文字をエントリーできないからだ。今回作成した検索システムでは Abu Hanifa と入力して検索できるようにしないといけないが、その為には、UTF-8をASCII(つまりShift-JIS)に変換する時にUをUと同等にみなせばよいことになる。
このような方針で作成したのが Britannica 11th の検索システムである。このシステムは Windows 10のコマンドプロンプト画面で動く。(通常コマンドプロンプト画面は黒地に白抜きの文字だが、この配色は眼にきついので、私はこのように背景を緑系にして白抜きの文字にして使っている。)例えば、Plato を検索した時は画面で [ xga plato ] と打ち込めば次のように表示される。いちいち大文字と小文字を区別するのが手間なので、内部的にはすべて小文字に変換してから検索するので、入力は大文字小文字関係ない。
結果、Platoという項目は合計で7ヶ見つかる。表示したいのはこの内3番目であるので、続けて、[ xga 3 ] と打ち込むことで自動的に Chromeで該当ページが表示される。
当初はここで満足していたのだが、何度か使っている内に、このシステムに不便さを感じた。それは、文字が小さいことだ。若い方には分からないかもしれないが、老年になると小さい文字を長時間読むのが苦痛となる。それで、大きな文字で読みたいのだが、都度Chromeの画面で文字の大きさをいじるのが面倒だ。それで、本検索システムを改造することでそのニーズに対応することにした。このように、プログラミングができると「わがままで、自己中の要望」がいとも簡単に実現できる。
(続く。。。)

















※コメント投稿者のブログIDはブログ作成者のみに通知されます