Alberto Bertoni and Giorgio Valentini
Model order selection for bio-molecular data clustering
BMC Bioinformatics 2007, 8(Suppl 2):S7
[
PDF][
Web Site]
・マイクロアレイデータのクラス分け法として、MOSRAM (Model Order Selection by RAndomized Maps) を提案する。
・データ
1. Synthetic data, 1000-dimensional synthetic multivariate gaussian data set (sample1) with relatively low cardinality (60 examples), characterized by a two-level hierarchical structure.
2. Leukemia [Golub]
3. Lymphoma [Alizadeh]
・比較したクラス分け法
1. Class. risk [Lange et al 2004]
2. Gap statistic [Tibshirani et al 2001]
3. Clest [Dudoit and Fridlyand 2002]
4. Figure of Merit [Levine and Domany 2001]
5. Model Explorer [BenHur et al 2002]
・生物学的知識によるクラス分けを正解とし、これにいかに近い最適クラス数をはじき出すかで評価する。
・MOSRAM は mosclust R package で実行可能。
・問題点「
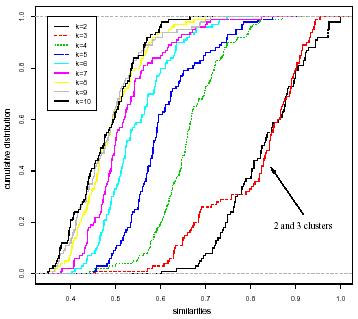
A drawback of most clustering algorithms is that they cannot automatically detect the "natural" number of clusters underlying the data, and in many cases we have no enough "a priori" biological knowledge to evaluate both the number of clusters as well as their validity.」
・方法「
We propose a stability method based on randomized maps that exploits the high-dimensionality and relatively low cardinality that characterize bio-molecular data, by selecting subsets of randomized linear combinations of the input variables, and by using stability indices based on the overall distribution of similarity measures between multiple pairs of clusterings performed on the randomly projected data.」
・概要「
In this paper we extend the Smolkin and Gosh approach to more general randomized maps from higher to lower-dimensional subspaces, in order to reduce the distortion induced by random projections. Moreover, we introduce a principled method based on the Johnson and Lindenstrauss lemma [19] to properly choose the dimension of the projected subspace.」
・アルゴリズムに "random" の要素が入るところがミソらしいが……なんだかよくわからず。