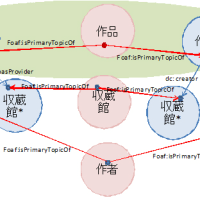
3.Webにおける意味、参照、アイデンティティ
それではWebにおける、定義、参照、参照されるエンティティとはなんであろうか。
WebにおいてあるURIが何を指しているか?一見自明な質問である。そこにアクセスして得られるWebページが指している内容であるという訳である。
初期のWebでは正しい答えであるが、現在では必ずしもそうとはいえない。例えば、
http://mixi.jp/show_friend.pl?id=12345
というURIが仮にあったときにこれはそこに指しているWebページを指している訳ではない。むしろ、その先にあるサービス(この場合はあるIDのmixiのコンテンツをみるというサービス)を指している。この場合は、このURIはまさにIdentifierとして機能を果たしているのであって、そのときにアクセスできたコンテンツを指している訳ではない。
URLがURIとして拡張された意図はまさにこのIdentifierとしての機能を果たすということであった。しかし、URIが意味することが2重になり混乱を生じている。
そこで次のような区別が必要となる。URIが指すものはリソースと総称されるが、そこでこのリソースを2種類に分けて考える。情報リソース(information resource)と非情報リソース(non-information resource)に分ける。前者はそこにあるWebページそのものがコンテンツであるようなものである。後者はWeb上にはそのコンテンツ自体は表現されないリソースである。
情報リソースの場合は、URIはそのリソースのidentifierでありかつそのURIでアクセスできる情報がそのコンテンツである。このリソースの意味はこのアクセスされたコンテンツということになる。前章の言葉使いでいえば、このエンティティは内包的に定義されるといえる。
非情報リソースの場合は、URIはそのリソースのidentifierでしかない。ではそのURIの意味はどうやって知るのだろうか?
一つの方法はそのURIがアイデンティティの確立された外部世界のエンティティを参照することである。ISBN(International Standard Book Number)やデジタルオブジェクト識別子DOI(Digital Object Identifier)がそれに当たる。ISBNは出版物につけられるコードであるが、出版する主体がアイデンティティを決定している 。しかし、その世界でアイデンティティが担保されていれば問題ない。
URN(Uniform Resource Name)がそういったエンティティを表現する仕組みとして用意されている[URI01]。例えばISSN(International Standard Serial Number、国際標準逐次刊行物番号)はIANA(Internet Assigned Numbers Authority)に登録されたISSN-URN Namespaceで規定されるURNである。URNで指し示されるものはWebにおいてもアイデンティティを持つといえる。
外部世界においてはアイデンティティがあるものであれば、URNとして登録しなくてもWebにおけるアイデンティティを持たすことができる。PURLプロジェクト ではそれぞれの持つidentifierをURIに変換するサービスを行っており、簡単にURIとしてのアイデンティティを得ることができる。DOIも同様な方法でURI化されている 。ただし、これらの方法の問題は、Webにおいてエンティティの意味を(一部でも)直接知ることができないということである。
外部世界を参照しているが、そのような一意なidentifierをもっていないエンティティはどうすればよいだろうか。なんらかの内包的定義にあたるものが必要となる。ただし、先の情報リソースと異なり、原理的にも完全に定義することができずあくまで部分的な記述となる 。この点で情報リソースとは本質的に異なる。それゆえ、情報リソースであるか非情報リソースであることが判別できることも必要である。
このような非情報リソースにはリソースそのものではないが、その説明にあたる情報(descriptive information)が付加されていることが望まれる。実はこのことは外部世界にアイデンティティを持つ非情報リソースにも当てはまる。たとえ外部世界でアイデンティティが保証されているといえども、Webからそれがなんであるかが知ることができなければ、結局同じだからである。
4.現在のWebにおける実現
上記の問題は現在のhttpプロトコルやや(x)htmlでは直接的な解決方法は用意されていない。まず情報リソースと非情報リソースの明示的な違いが表現されない。またURIに関する記述情報を付加するプロトコルがないということである。
そこで現在のWebではURIを用いたアイデンティティは次のように実現することが推奨されている[Ayers08]。
① 情報リソースを指すURIにアクセスするときにhttpプロトコルのcontent negotiationを用いて次のように振る舞う。http clientが(x)htmlを必要するときは(x)htmlで記述された情報がURLを、RDFを必要するときはRDFで書かれた情報があるURLを指し示す。
② 非情報リソースを指すURIを参照(dereference)したときはhttpdサーバは200 responseではなく、説明情報のあるURI とともに303 response を返す。303 responseは 3xx response (redirection)の一つで、see otherの意味である 。
まず①により、URIのidentifierとしての機能と指し示すコンテンツを分離している。またコンテンツとして人間向きとコンピュータ向き(RDF)に分けている。非情報リソースを指すURIの場合はそのURIそのものがidentifierの機能だけであるが、説明情報がredirectionとして関係づけられる。説明情報は情報リソースなので①の方式でコンテンツを得る。
(続く)
それではWebにおける、定義、参照、参照されるエンティティとはなんであろうか。
WebにおいてあるURIが何を指しているか?一見自明な質問である。そこにアクセスして得られるWebページが指している内容であるという訳である。
初期のWebでは正しい答えであるが、現在では必ずしもそうとはいえない。例えば、
http://mixi.jp/show_friend.pl?id=12345
というURIが仮にあったときにこれはそこに指しているWebページを指している訳ではない。むしろ、その先にあるサービス(この場合はあるIDのmixiのコンテンツをみるというサービス)を指している。この場合は、このURIはまさにIdentifierとして機能を果たしているのであって、そのときにアクセスできたコンテンツを指している訳ではない。
URLがURIとして拡張された意図はまさにこのIdentifierとしての機能を果たすということであった。しかし、URIが意味することが2重になり混乱を生じている。
そこで次のような区別が必要となる。URIが指すものはリソースと総称されるが、そこでこのリソースを2種類に分けて考える。情報リソース(information resource)と非情報リソース(non-information resource)に分ける。前者はそこにあるWebページそのものがコンテンツであるようなものである。後者はWeb上にはそのコンテンツ自体は表現されないリソースである。
情報リソースの場合は、URIはそのリソースのidentifierでありかつそのURIでアクセスできる情報がそのコンテンツである。このリソースの意味はこのアクセスされたコンテンツということになる。前章の言葉使いでいえば、このエンティティは内包的に定義されるといえる。
非情報リソースの場合は、URIはそのリソースのidentifierでしかない。ではそのURIの意味はどうやって知るのだろうか?
一つの方法はそのURIがアイデンティティの確立された外部世界のエンティティを参照することである。ISBN(International Standard Book Number)やデジタルオブジェクト識別子DOI(Digital Object Identifier)がそれに当たる。ISBNは出版物につけられるコードであるが、出版する主体がアイデンティティを決定している 。しかし、その世界でアイデンティティが担保されていれば問題ない。
URN(Uniform Resource Name)がそういったエンティティを表現する仕組みとして用意されている[URI01]。例えばISSN(International Standard Serial Number、国際標準逐次刊行物番号)はIANA(Internet Assigned Numbers Authority)に登録されたISSN-URN Namespaceで規定されるURNである。URNで指し示されるものはWebにおいてもアイデンティティを持つといえる。
外部世界においてはアイデンティティがあるものであれば、URNとして登録しなくてもWebにおけるアイデンティティを持たすことができる。PURLプロジェクト ではそれぞれの持つidentifierをURIに変換するサービスを行っており、簡単にURIとしてのアイデンティティを得ることができる。DOIも同様な方法でURI化されている 。ただし、これらの方法の問題は、Webにおいてエンティティの意味を(一部でも)直接知ることができないということである。
外部世界を参照しているが、そのような一意なidentifierをもっていないエンティティはどうすればよいだろうか。なんらかの内包的定義にあたるものが必要となる。ただし、先の情報リソースと異なり、原理的にも完全に定義することができずあくまで部分的な記述となる 。この点で情報リソースとは本質的に異なる。それゆえ、情報リソースであるか非情報リソースであることが判別できることも必要である。
このような非情報リソースにはリソースそのものではないが、その説明にあたる情報(descriptive information)が付加されていることが望まれる。実はこのことは外部世界にアイデンティティを持つ非情報リソースにも当てはまる。たとえ外部世界でアイデンティティが保証されているといえども、Webからそれがなんであるかが知ることができなければ、結局同じだからである。
4.現在のWebにおける実現
上記の問題は現在のhttpプロトコルやや(x)htmlでは直接的な解決方法は用意されていない。まず情報リソースと非情報リソースの明示的な違いが表現されない。またURIに関する記述情報を付加するプロトコルがないということである。
そこで現在のWebではURIを用いたアイデンティティは次のように実現することが推奨されている[Ayers08]。
① 情報リソースを指すURIにアクセスするときにhttpプロトコルのcontent negotiationを用いて次のように振る舞う。http clientが(x)htmlを必要するときは(x)htmlで記述された情報がURLを、RDFを必要するときはRDFで書かれた情報があるURLを指し示す。
② 非情報リソースを指すURIを参照(dereference)したときはhttpdサーバは200 responseではなく、説明情報のあるURI とともに303 response を返す。303 responseは 3xx response (redirection)の一つで、see otherの意味である 。
まず①により、URIのidentifierとしての機能と指し示すコンテンツを分離している。またコンテンツとして人間向きとコンピュータ向き(RDF)に分けている。非情報リソースを指すURIの場合はそのURIそのものがidentifierの機能だけであるが、説明情報がredirectionとして関係づけられる。説明情報は情報リソースなので①の方式でコンテンツを得る。
(続く)