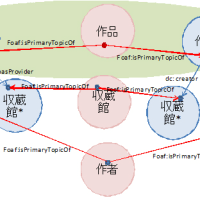
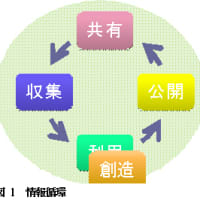
3.日本におけるLinked Data化の課題
LOD活動はヨーロッパおよびアメリカにおいて盛んであり、単に情報研究者の活動の域を超えて、個々の分野の専門家や政府などの組織を巻き込む活動になっている。
残念ながら日本ではさほど活動的であるとはいえない。それはなぜなのか、その解決はあるのかというのは本節で述べる。ここで「日本」と呼んでいるのは、日本国内の活動and/or日本語での活動をさしている。もちろんLODは本質的にグローバルであり、こんな区分は本質的でないが、現状を把握するためにはあえて分けて考えてみる。
3.1.情報公開・共有の文化
日本の社会、ことに組織においては前節で説明したような情報公開・共有の重要性は十分に理解されているとはいえない。情報循環は情報の公共性を維持することであり、情報公開・共有はその情報循環を実現する要素として重要であるということが理解されていなければ、情報公開・共有はリスクだけが強調され、実際に自らの情報を公開・共有することができない。ことに公共セクターである組織のほうがより消極的なことが多いのは残念である。
これは日本の社会の文化的背景によるのか断言はできないが、いずれにしろこの点から変えないと継続的・持続的な情報共有は実現できない。これはLinked Data実現以前の問題であるが、とくにLinked Dataにおいては大規模なデータを持つ組織および公共セクターの能動的な参画が重要であるので、Web化よりこの点が効いてくる。
なお、政府系でも必ずしもどこも消極的というわけではない。国民への情報提供を主たる業務とするような組織は情報公開をより効果的にする手段として利用しつつある。第5章で触れた国土地理院は実質的に制限をつけずに情報の再利用を許しているし、4節で述べる国立国会図書館や国立情報学研究所も新しい公開手段として利用しつつある。
なお、政府系に関しては第4章で述べたようにオープンガバメントの動きが出ているので、より積極的に変わるチャンスがあると期待している。
3.2 コミュニティの未成熟
Linked Data実現には単に情報のネットワークだけではなく、人のネットワークも必要である。
Linked Dataはその性質からして異なる情報源からの情報が相互につながってこそ価値が出る。またデータそのものは各領域にあるので、単に情報研究者・技術者だけでなく領域の研究者・専門家の参画する必要がある。Linked Dataはまだ発展途上であり未解決な問題が多々あるので、このような人々が適宜インフォーマルにコミュニケーションをとって解決していかないといけない。
欧米を中心とするコミュニティではメーリングリストで小さい問題から大きな問題まで盛んに話し合われている。また分野ごとのコミュニティも形成しつつある。残念ながら国内ではこのようなコミュニティはまだ未形成である。これは筆者を含む本領域の研究者・専門家の宿題ではある。
なお、4節で触れるバイオサイエンス系はデータの性質上国内というよりは国際的な関係が重要であり、国際的コミュニティに加わることでLinked Data化が推進されている。
国内ではまだ大きな動きとはいえないが、google groupにはLinkedData.jpというものが作られ、少しづつ状況は変化している。4節で説明するLod.acプロジェクトでは美術館・博物館情報のLinked Data化を進める中で、地域のNPOとの連携も始まっている。
3.3 中心的データの欠如
LOD クラウドをみて明らかなのはDbpediaがLOD クラウドの中心になっていると言うことである。LODにおいては様々な情報源同士が相互にリンクしあえるのであるが、そうはいってもデファクト的につなげることができるサイトがあれば、自身の情報のLinked Data化するときの目標を定めやすい。いわば“参入障壁”を低くすることができる。それがDbpediaである。Dbpediaはオンライン百科事典WikipediaをLinked Data化したものであるので、極めて広範な領域をカバーしている。たいていの分野で何らかの関係性をみいだすことができる。LODにおいてDbpediaは極めて重要で、現在のLOD活動はこのDbpediaの公開に始まると言っても過言ではない。
このDbpediaは日本語リソースとして使うには問題がある。Dbpediaは英語版Wikipediaを使っている。Wikipediaの各ページに相当する資源にはWikipediaの言語リンクを利用して多言語のラベルがつけられているので、日本語のラベルは存在する。しかし、Wikipediaは各国語版で大きく構成が異なるので、日本語のLinked Dataには適切とはいえない。
これに関してはlod.acプロジェクトでは、日本語のリソースを増やすために多様な種類の辞典・事典から用語を抜き出してリソース化した「ことばぶ」というものを開発している(4節参照)。
3.4 日本語のリソースの記法
より技術的な課題としては、資源のURIに日本語を使うどうかという問題がある。クラス名やプロパティ名に日本語を使うか、あるいはそれに相当する英語名を使うかということである。URIの場合アスキー文字のみであるが、IRI(国際化URI, Internationalized Resource Identifier)[RFC3987]に基づけばunicodeで書いた日本語文字列を含めることができるので技術的には可能である。しかし、それだけで問題が解決するわけではない。
まずリソース名に日本語を混ぜることのメリットしては、
(1) 既存のデータ構造を流用できる
(2) 了解性(少なくとも日本人には)
(3) 同一性(翻訳による揺らぎがない)
ということが挙げられる。逆にデメリットは
(1) 関係システムが技術的に処理可能か不明(IRIに対応できていない)
(2) 日本人以外には意味不明
(3) 国際的なスキーマと合わせると英語・日本語が混交して不自然
ということが挙げられる。一方、元々日本語を使ったデータ構造を英語化して記述するとなると、メリットしてはこの反対であり、
(1) 技術的に安心(すべてのシステムが処理可能)
(2) 了解性
(3) 他の国際的なスキーマとスムーズに結合
ということになる。一方のデメリットしては
(1) 翻訳の必要、同一性の担保が難しい
ということがある。
Linked Dataは国際的に流通するものであるという点においては、英語化したほうが適切だといえる。しかし、Linked Data化されるものが常に国際的に流通を意図しているというのもおかしな話である。日本国内で流通することに意味があるものもある。そうであれば必ずしも英語化にこだわる必要はない。むしろ英語化がLinked Data化の障害になるようならば、元々のデータで使われている日本語そのままでLinked Data化で十分である。例えば4節で取り上げるもののうち、バイオサイエンスにおいては前者であり、日本語Dbpediaでは後者である。
中間的方式としては、英語化したリソースに日本語のラベルを張るという方法 や英語と日本語で2重にリソースを記述するなどの方法も考えられる。
現状では、データの性質を鑑み、方法を定めるということになろう。
なお、もうひとつの日本語特有の問題は「読み」であるが、これは4節で取り上げる。
LOD活動はヨーロッパおよびアメリカにおいて盛んであり、単に情報研究者の活動の域を超えて、個々の分野の専門家や政府などの組織を巻き込む活動になっている。
残念ながら日本ではさほど活動的であるとはいえない。それはなぜなのか、その解決はあるのかというのは本節で述べる。ここで「日本」と呼んでいるのは、日本国内の活動and/or日本語での活動をさしている。もちろんLODは本質的にグローバルであり、こんな区分は本質的でないが、現状を把握するためにはあえて分けて考えてみる。
3.1.情報公開・共有の文化
日本の社会、ことに組織においては前節で説明したような情報公開・共有の重要性は十分に理解されているとはいえない。情報循環は情報の公共性を維持することであり、情報公開・共有はその情報循環を実現する要素として重要であるということが理解されていなければ、情報公開・共有はリスクだけが強調され、実際に自らの情報を公開・共有することができない。ことに公共セクターである組織のほうがより消極的なことが多いのは残念である。
これは日本の社会の文化的背景によるのか断言はできないが、いずれにしろこの点から変えないと継続的・持続的な情報共有は実現できない。これはLinked Data実現以前の問題であるが、とくにLinked Dataにおいては大規模なデータを持つ組織および公共セクターの能動的な参画が重要であるので、Web化よりこの点が効いてくる。
なお、政府系でも必ずしもどこも消極的というわけではない。国民への情報提供を主たる業務とするような組織は情報公開をより効果的にする手段として利用しつつある。第5章で触れた国土地理院は実質的に制限をつけずに情報の再利用を許しているし、4節で述べる国立国会図書館や国立情報学研究所も新しい公開手段として利用しつつある。
なお、政府系に関しては第4章で述べたようにオープンガバメントの動きが出ているので、より積極的に変わるチャンスがあると期待している。
3.2 コミュニティの未成熟
Linked Data実現には単に情報のネットワークだけではなく、人のネットワークも必要である。
Linked Dataはその性質からして異なる情報源からの情報が相互につながってこそ価値が出る。またデータそのものは各領域にあるので、単に情報研究者・技術者だけでなく領域の研究者・専門家の参画する必要がある。Linked Dataはまだ発展途上であり未解決な問題が多々あるので、このような人々が適宜インフォーマルにコミュニケーションをとって解決していかないといけない。
欧米を中心とするコミュニティではメーリングリストで小さい問題から大きな問題まで盛んに話し合われている。また分野ごとのコミュニティも形成しつつある。残念ながら国内ではこのようなコミュニティはまだ未形成である。これは筆者を含む本領域の研究者・専門家の宿題ではある。
なお、4節で触れるバイオサイエンス系はデータの性質上国内というよりは国際的な関係が重要であり、国際的コミュニティに加わることでLinked Data化が推進されている。
国内ではまだ大きな動きとはいえないが、google groupにはLinkedData.jpというものが作られ、少しづつ状況は変化している。4節で説明するLod.acプロジェクトでは美術館・博物館情報のLinked Data化を進める中で、地域のNPOとの連携も始まっている。
3.3 中心的データの欠如
LOD クラウドをみて明らかなのはDbpediaがLOD クラウドの中心になっていると言うことである。LODにおいては様々な情報源同士が相互にリンクしあえるのであるが、そうはいってもデファクト的につなげることができるサイトがあれば、自身の情報のLinked Data化するときの目標を定めやすい。いわば“参入障壁”を低くすることができる。それがDbpediaである。Dbpediaはオンライン百科事典WikipediaをLinked Data化したものであるので、極めて広範な領域をカバーしている。たいていの分野で何らかの関係性をみいだすことができる。LODにおいてDbpediaは極めて重要で、現在のLOD活動はこのDbpediaの公開に始まると言っても過言ではない。
このDbpediaは日本語リソースとして使うには問題がある。Dbpediaは英語版Wikipediaを使っている。Wikipediaの各ページに相当する資源にはWikipediaの言語リンクを利用して多言語のラベルがつけられているので、日本語のラベルは存在する。しかし、Wikipediaは各国語版で大きく構成が異なるので、日本語のLinked Dataには適切とはいえない。
これに関してはlod.acプロジェクトでは、日本語のリソースを増やすために多様な種類の辞典・事典から用語を抜き出してリソース化した「ことばぶ」というものを開発している(4節参照)。
3.4 日本語のリソースの記法
より技術的な課題としては、資源のURIに日本語を使うどうかという問題がある。クラス名やプロパティ名に日本語を使うか、あるいはそれに相当する英語名を使うかということである。URIの場合アスキー文字のみであるが、IRI(国際化URI, Internationalized Resource Identifier)[RFC3987]に基づけばunicodeで書いた日本語文字列を含めることができるので技術的には可能である。しかし、それだけで問題が解決するわけではない。
まずリソース名に日本語を混ぜることのメリットしては、
(1) 既存のデータ構造を流用できる
(2) 了解性(少なくとも日本人には)
(3) 同一性(翻訳による揺らぎがない)
ということが挙げられる。逆にデメリットは
(1) 関係システムが技術的に処理可能か不明(IRIに対応できていない)
(2) 日本人以外には意味不明
(3) 国際的なスキーマと合わせると英語・日本語が混交して不自然
ということが挙げられる。一方、元々日本語を使ったデータ構造を英語化して記述するとなると、メリットしてはこの反対であり、
(1) 技術的に安心(すべてのシステムが処理可能)
(2) 了解性
(3) 他の国際的なスキーマとスムーズに結合
ということになる。一方のデメリットしては
(1) 翻訳の必要、同一性の担保が難しい
ということがある。
Linked Dataは国際的に流通するものであるという点においては、英語化したほうが適切だといえる。しかし、Linked Data化されるものが常に国際的に流通を意図しているというのもおかしな話である。日本国内で流通することに意味があるものもある。そうであれば必ずしも英語化にこだわる必要はない。むしろ英語化がLinked Data化の障害になるようならば、元々のデータで使われている日本語そのままでLinked Data化で十分である。例えば4節で取り上げるもののうち、バイオサイエンスにおいては前者であり、日本語Dbpediaでは後者である。
中間的方式としては、英語化したリソースに日本語のラベルを張るという方法 や英語と日本語で2重にリソースを記述するなどの方法も考えられる。
現状では、データの性質を鑑み、方法を定めるということになろう。
なお、もうひとつの日本語特有の問題は「読み」であるが、これは4節で取り上げる。