4.現在の日本/日本語のLinked Data
ここでは日本において大規模にLODあるいはRDFを公開している例をいくつか取り上げる。
4.1 理化学研究所のDB
理化学研究所が運営している公開DBサービスであるサイネス(SciNetS.org)においてはすべてのデータがOWL/RDFとして利用可能である。バイオ系を中心に現在100個以上のデータベースが登録されている。全インスタンス数は約900万件、データサイズは約11TBである。また、サイネスを使って国際的なデータ連携のプロジェクトが行われている(例:マウス表現型データの国際共有化/InterPhenome )。
サイネスではバイオ研究者が求める検索を実現するために通常のSPARQLエンジンではなく、統計処理機能を拡張した独自開発の検索エンジン(GRASE)を採用している。また、RDFのままではウェブブラウザやJavaScriptが直接処理しにくいという欠点を補うために、簡易な方式でも同じデータにアクセスできるようSemantic-JSONというインタフェースを提供している 。Semantic-JSON APIではすべての情報にIDがつけられ、データ取得の指示(命令)とこのIDを含んだURIをサーバに投げることでデータを取得する。このAPIは各種言語(Ruby, Perl他)のライブラリとして用意されており、さらにはこのサイト上でスクリプトを書いて実行する環境も用意している。
4.2 ライフサイエンス統合データベースプロジェクト
大学共同利用機関法人 情報・システム研究機構ライフサイエンス統合データベースセンター(DBCLS)では様々なアプローチでバイオデータのセマンティックWeb化を進めている。例えば各種ライフサイエンス系のWebサービスの標準的な方法でアクセス可能にするTogoWS では出力をRDFとして得られるようにしている。DDBJ-PDBj-KEGG RDF化プロジェクトではタンパク質データベースPDBjのRDF化などを行っている。他にも小規模用データベースシステムTogoDBではRDF出力をサポートする予定である。
またDBCLSではバイオ系におけるプログラミング技術の向上と知識共有のために、合宿形式で行うDBCLS BioHackathonを主催している。そこではバイオ系のデータに対するセマンティックWeb技術を適用したプログラミングも行われている。
4.3 国立国会図書館のNDLSH
図書館の世界ではいま世界的に急速にLinked Data化が進んでいる。LOD クラウドの右上にpublication関係が集まっているが、そのなかでも図書館に関係するLODはLCSHを中心にまとまっている。LCSHはアメリカ議会図書館の件名標目表(subject heading)のことである。件名標目とは図書を分類するときの統制語彙で、多くは階層的な構造をもっている。各国の中央図書館は自らの管理する件名標目や著者名典拠や書誌をLinked Data化して公開をはじめている。
日本では国立国会図書館が自らが管理する国立国会図書館件名標目表(NDLSH)をLinked Data化して公開をはじめている 。規模としては約130万tripleである。またSPARQL endpointも用意されており、おそらく日本で最初の実用的なSPARQL endpointである。図3にSPARQLでのquery例を示す。
データ構造は単純で基本はdctermsとSKOSを使ったもの樽。SKOSは元々図書館系の情報構造に基づいているので相性はいい。対応するLCSHがある場合は rdfs:seeAlsoでつなげている。
日本語特有の問題としては「読み」がある。読みというのは他の言語には存在しない。しかし日本語のデータにおいては重要な要素である。NDLSHにおいては独自のtranscriptionというタグを定義してそれをタイトルの下部構造として埋め込んでいる。これはタイトルに限らず他のリソースでも読みが存在しうるので、統一的構造としてはわかりやすい。反面、ブランクノードを含む構造になり利用側では注意が必要である。
4.4 国立情報学研究所のCiNiiおよびKaken
国立情報学研究所が提供するデータベースサービスでは通常のHTMLによるデータ提供に加えてRDFによるデータ提供もはじめている。
CiNii は国内論文の書誌および本文検索サービスであり、現在、1300万件以上のデータを提供しており、月間6億以上のアクセスのあるサイトである。CiNiiにおける主要な情報オブジェクトは書誌情報と著者情報であるが、主に書誌情報をRDFとして提供している(著者情報のRDFは簡易版)。その例を図4に示す。HTMLのURL+”.rdf”のURLとしてアクセスできる。基本的にはdctermsとPRISM(The Publishing Requirements for Industry Standard Metadata), foafを組み合わせて表現している。日本語と英語の混在については言語タグ(enとjp)をつけて、別のリソースとして扱っている。
Kakenは文部科学省科学研究費補助金の報告書のデータベースである。主な情報オブジェクトは報告書と研究者で、件数にして100万件程度の報告書および18万人程度の研究者がデータベース化されている。メタデータとしてはタイトルなどにdcterms、人物情報にfoafを使うもののの他は独自のタグを定義して使っている。RDFへのアクセスはhttpのcontent negotiationを使ってできるようになっている。実験的にSPAQLエンドポイントを構築している。このDBでは研究者名でDBLPおよびキーワードでDbpediaとリンクが張られている。
4.5 lod.acプロジェクト
このプロジェクトは情報・システム研究機構 新領域融合研究センターのプロジェクトの一環として「学術リソースのためのオープン・ソーシャル・セマンティックWeb基盤の構築」と題目で実施しているものである。日本における学術に関するデータをLinked Dataの方式で公開・共有するということを実践的に実施して、実践を通じてのプラットフォームつくりと構築知識の獲得を目的としてる。
(1)美術館・博物館情報
その最初の対象は分散かつ未統合のデータのテストケースとして美術館・博物館情報の統合とした。日本における美術館・博物館の情報は各館が独自に所蔵品情報を公開する程度で情報の統合が行われていない。そこで本プロジェクトで日本全国の美術館・博物館情報をLinked Dataとして共有して統合できる仕組みを作ることにした。このような試みはヨーロッパではEUのプロジェクトとしてEuropeanaというものが行われている 。EuropeanaではEU27カ国の博物館の収蔵情報を統合して扱えるサービスを構築している。Europeanaにおいても一部の情報をLinked Dataして提示する実験システムを公開している。
LOD Museum(仮)では美術シソーラス[2]、作品データベース、個別美術館・博物館といった異なる情報源からの情報を統合して構築される。このようなそれぞれが自身の情報のオーソリティであるような複数の情報源を統合す るときには、どのようにデータを統合するかという統合ポリシーが必要である。今回はオーソリティ統合に関して次にような原則を用意した。
1. 自分がオーソリティをもつ情報オブジェクトは自らIDを付与して管理する
2. 他の情報源がオーソリティを持つ情報オブジェクトはそのIDを流用した独自の情報オブジェクトとして記述する。
3. 自分がオーソリティを持つ情報オブジェクトから他の情報源がオーソリティを持つ情報オブジェクトとは参照関係(owl:isPrimaryTopicOfまたは他のプロパティ)で結ぶ。
このような構造にしたのは、オーソリティの異なるデータをその違いを残して管理するためである。データの追加や更新においてこの違いを保持しておくことは重要である。
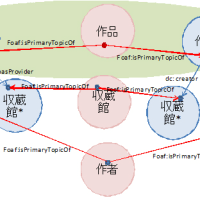
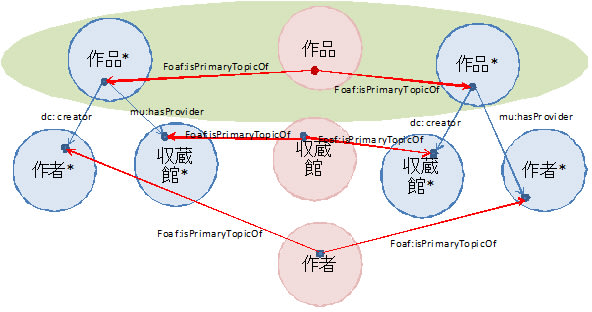
LOD Museum(仮)では作品、作者、所蔵館が基本の情報オブジェクトであり、それぞれを一元的にIDをつけて管理する。しかし、LOD Museum(仮)が生成した情報オブジェクトはIDと最小限の記述した持たず、これらに関して外部の情報源から取り込んだ情報はそれぞれ別の情報オブジェクトとして記述される(図5参照)。例えば、ある作品に関する情報は2個以上のowl:isPrimaryTopicOfでつながった情報オブジェクトの和として表現される。
それぞれのメタデータは、dcterms, foaf, NDLSH, CIDOC CRMといったメタデータから必要な項目を抜き出したタグを集めて構成した。このメタデータでは作品の詳細なデータを記述するのではなく共通性のある属性を列挙している。なお美術関係においては作者名義は作者とは別に重要である。LOD Meseum(仮)では作品には作者名義と作者を(もし違えば)別のプロパティで表現し、作者情報においてはfoaf:nickで作者名義を記述するようにしている。
日本語に関しては、作品名や作者名等は基本的に言語タグ(@ja-hani, @ja-hrkt等)を用いて同一プロパティにを多重に値を与えて表現する。
(2)ことば、事典情報
先に述べたようにDbpedia汎用的なリソースがあると参照先として使えるのでLOD化を進めやすい。そのために、まず日本でのことば、用語を集めてリソースとして参照できるサイト「ことはぶ」 を用意した。「ことはぶ」は各種辞書・事典(Wikipedia, はてなキーワード、ニコニコ大百科(仮), Yahoo!百科事典等)の掲載語を集め集約してRDFによって記述したものである。NICTで実施された日本語化されたWordNetも含まれている。集約の結果、約225万語あった。個別のリソースごとのRDFあるいはSPARQLエンドポイントとしてアクセスできる。
またWikipediaのinfoboxを利用したLOD化は東京大学の中山浩太郎氏と共同で日本語版Dbpediaを開設する予定である。
5.未来に向けて
本章では日本におけるLinked Dataに関わる活動を紹介した。まだ個別の取り組みにとどまっており、大きな動きになっているとはいえない。しかし、国内においてもオープンガバメントの動きがでてきたように 、海外の動きに合わせて大きく変化することも考えられる。そのときに備えて国内においてもコミュニティをつくり技術や情報の共有を進めるべきであろう。
謝辞
本稿をまとめるに当たって、lod.acプロジェクトでの議論が大変参考になりました。とくに大向一輝氏(NII)、加藤文彦氏(NII)、嘉村哲郎氏(総合研究大学院大学/東京芸術大学)、濱崎雅弘氏(産総研), Tran Duy Hoang氏(NII)には感謝いたします。また該当項目においては豊田哲郎氏(理化学研究所)、中尾光輝氏(DBCLS)にご教授いただきました。感謝いたします。
ここでは日本において大規模にLODあるいはRDFを公開している例をいくつか取り上げる。
4.1 理化学研究所のDB
理化学研究所が運営している公開DBサービスであるサイネス(SciNetS.org)においてはすべてのデータがOWL/RDFとして利用可能である。バイオ系を中心に現在100個以上のデータベースが登録されている。全インスタンス数は約900万件、データサイズは約11TBである。また、サイネスを使って国際的なデータ連携のプロジェクトが行われている(例:マウス表現型データの国際共有化/InterPhenome )。
サイネスではバイオ研究者が求める検索を実現するために通常のSPARQLエンジンではなく、統計処理機能を拡張した独自開発の検索エンジン(GRASE)を採用している。また、RDFのままではウェブブラウザやJavaScriptが直接処理しにくいという欠点を補うために、簡易な方式でも同じデータにアクセスできるようSemantic-JSONというインタフェースを提供している 。Semantic-JSON APIではすべての情報にIDがつけられ、データ取得の指示(命令)とこのIDを含んだURIをサーバに投げることでデータを取得する。このAPIは各種言語(Ruby, Perl他)のライブラリとして用意されており、さらにはこのサイト上でスクリプトを書いて実行する環境も用意している。
4.2 ライフサイエンス統合データベースプロジェクト
大学共同利用機関法人 情報・システム研究機構ライフサイエンス統合データベースセンター(DBCLS)では様々なアプローチでバイオデータのセマンティックWeb化を進めている。例えば各種ライフサイエンス系のWebサービスの標準的な方法でアクセス可能にするTogoWS では出力をRDFとして得られるようにしている。DDBJ-PDBj-KEGG RDF化プロジェクトではタンパク質データベースPDBjのRDF化などを行っている。他にも小規模用データベースシステムTogoDBではRDF出力をサポートする予定である。
またDBCLSではバイオ系におけるプログラミング技術の向上と知識共有のために、合宿形式で行うDBCLS BioHackathonを主催している。そこではバイオ系のデータに対するセマンティックWeb技術を適用したプログラミングも行われている。
4.3 国立国会図書館のNDLSH
図書館の世界ではいま世界的に急速にLinked Data化が進んでいる。LOD クラウドの右上にpublication関係が集まっているが、そのなかでも図書館に関係するLODはLCSHを中心にまとまっている。LCSHはアメリカ議会図書館の件名標目表(subject heading)のことである。件名標目とは図書を分類するときの統制語彙で、多くは階層的な構造をもっている。各国の中央図書館は自らの管理する件名標目や著者名典拠や書誌をLinked Data化して公開をはじめている。
日本では国立国会図書館が自らが管理する国立国会図書館件名標目表(NDLSH)をLinked Data化して公開をはじめている 。規模としては約130万tripleである。またSPARQL endpointも用意されており、おそらく日本で最初の実用的なSPARQL endpointである。図3にSPARQLでのquery例を示す。
データ構造は単純で基本はdctermsとSKOSを使ったもの樽。SKOSは元々図書館系の情報構造に基づいているので相性はいい。対応するLCSHがある場合は rdfs:seeAlsoでつなげている。
日本語特有の問題としては「読み」がある。読みというのは他の言語には存在しない。しかし日本語のデータにおいては重要な要素である。NDLSHにおいては独自のtranscriptionというタグを定義してそれをタイトルの下部構造として埋め込んでいる。これはタイトルに限らず他のリソースでも読みが存在しうるので、統一的構造としてはわかりやすい。反面、ブランクノードを含む構造になり利用側では注意が必要である。
4.4 国立情報学研究所のCiNiiおよびKaken
国立情報学研究所が提供するデータベースサービスでは通常のHTMLによるデータ提供に加えてRDFによるデータ提供もはじめている。
CiNii は国内論文の書誌および本文検索サービスであり、現在、1300万件以上のデータを提供しており、月間6億以上のアクセスのあるサイトである。CiNiiにおける主要な情報オブジェクトは書誌情報と著者情報であるが、主に書誌情報をRDFとして提供している(著者情報のRDFは簡易版)。その例を図4に示す。HTMLのURL+”.rdf”のURLとしてアクセスできる。基本的にはdctermsとPRISM(The Publishing Requirements for Industry Standard Metadata), foafを組み合わせて表現している。日本語と英語の混在については言語タグ(enとjp)をつけて、別のリソースとして扱っている。
Kakenは文部科学省科学研究費補助金の報告書のデータベースである。主な情報オブジェクトは報告書と研究者で、件数にして100万件程度の報告書および18万人程度の研究者がデータベース化されている。メタデータとしてはタイトルなどにdcterms、人物情報にfoafを使うもののの他は独自のタグを定義して使っている。RDFへのアクセスはhttpのcontent negotiationを使ってできるようになっている。実験的にSPAQLエンドポイントを構築している。このDBでは研究者名でDBLPおよびキーワードでDbpediaとリンクが張られている。
4.5 lod.acプロジェクト
このプロジェクトは情報・システム研究機構 新領域融合研究センターのプロジェクトの一環として「学術リソースのためのオープン・ソーシャル・セマンティックWeb基盤の構築」と題目で実施しているものである。日本における学術に関するデータをLinked Dataの方式で公開・共有するということを実践的に実施して、実践を通じてのプラットフォームつくりと構築知識の獲得を目的としてる。
(1)美術館・博物館情報
その最初の対象は分散かつ未統合のデータのテストケースとして美術館・博物館情報の統合とした。日本における美術館・博物館の情報は各館が独自に所蔵品情報を公開する程度で情報の統合が行われていない。そこで本プロジェクトで日本全国の美術館・博物館情報をLinked Dataとして共有して統合できる仕組みを作ることにした。このような試みはヨーロッパではEUのプロジェクトとしてEuropeanaというものが行われている 。EuropeanaではEU27カ国の博物館の収蔵情報を統合して扱えるサービスを構築している。Europeanaにおいても一部の情報をLinked Dataして提示する実験システムを公開している。
LOD Museum(仮)では美術シソーラス[2]、作品データベース、個別美術館・博物館といった異なる情報源からの情報を統合して構築される。このようなそれぞれが自身の情報のオーソリティであるような複数の情報源を統合す るときには、どのようにデータを統合するかという統合ポリシーが必要である。今回はオーソリティ統合に関して次にような原則を用意した。
1. 自分がオーソリティをもつ情報オブジェクトは自らIDを付与して管理する
2. 他の情報源がオーソリティを持つ情報オブジェクトはそのIDを流用した独自の情報オブジェクトとして記述する。
3. 自分がオーソリティを持つ情報オブジェクトから他の情報源がオーソリティを持つ情報オブジェクトとは参照関係(owl:isPrimaryTopicOfまたは他のプロパティ)で結ぶ。
このような構造にしたのは、オーソリティの異なるデータをその違いを残して管理するためである。データの追加や更新においてこの違いを保持しておくことは重要である。
LOD Museum(仮)では作品、作者、所蔵館が基本の情報オブジェクトであり、それぞれを一元的にIDをつけて管理する。しかし、LOD Museum(仮)が生成した情報オブジェクトはIDと最小限の記述した持たず、これらに関して外部の情報源から取り込んだ情報はそれぞれ別の情報オブジェクトとして記述される(図5参照)。例えば、ある作品に関する情報は2個以上のowl:isPrimaryTopicOfでつながった情報オブジェクトの和として表現される。
それぞれのメタデータは、dcterms, foaf, NDLSH, CIDOC CRMといったメタデータから必要な項目を抜き出したタグを集めて構成した。このメタデータでは作品の詳細なデータを記述するのではなく共通性のある属性を列挙している。なお美術関係においては作者名義は作者とは別に重要である。LOD Meseum(仮)では作品には作者名義と作者を(もし違えば)別のプロパティで表現し、作者情報においてはfoaf:nickで作者名義を記述するようにしている。
日本語に関しては、作品名や作者名等は基本的に言語タグ(@ja-hani, @ja-hrkt等)を用いて同一プロパティにを多重に値を与えて表現する。
(2)ことば、事典情報
先に述べたようにDbpedia汎用的なリソースがあると参照先として使えるのでLOD化を進めやすい。そのために、まず日本でのことば、用語を集めてリソースとして参照できるサイト「ことはぶ」 を用意した。「ことはぶ」は各種辞書・事典(Wikipedia, はてなキーワード、ニコニコ大百科(仮), Yahoo!百科事典等)の掲載語を集め集約してRDFによって記述したものである。NICTで実施された日本語化されたWordNetも含まれている。集約の結果、約225万語あった。個別のリソースごとのRDFあるいはSPARQLエンドポイントとしてアクセスできる。
またWikipediaのinfoboxを利用したLOD化は東京大学の中山浩太郎氏と共同で日本語版Dbpediaを開設する予定である。
5.未来に向けて
本章では日本におけるLinked Dataに関わる活動を紹介した。まだ個別の取り組みにとどまっており、大きな動きになっているとはいえない。しかし、国内においてもオープンガバメントの動きがでてきたように 、海外の動きに合わせて大きく変化することも考えられる。そのときに備えて国内においてもコミュニティをつくり技術や情報の共有を進めるべきであろう。
謝辞
本稿をまとめるに当たって、lod.acプロジェクトでの議論が大変参考になりました。とくに大向一輝氏(NII)、加藤文彦氏(NII)、嘉村哲郎氏(総合研究大学院大学/東京芸術大学)、濱崎雅弘氏(産総研), Tran Duy Hoang氏(NII)には感謝いたします。また該当項目においては豊田哲郎氏(理化学研究所)、中尾光輝氏(DBCLS)にご教授いただきました。感謝いたします。