5.RDFが作るLinked Dataの世界
前章でみてきたようにURIを中心にエンティティのアイデンティティをWebの世界で表現できる。とくに説明情報をコンピュータ可読の情報とすることでコンピュータが処理可能な世界を作ることができる。その記述方法としてRDF(Resource Description Framework) [Manola04] [Brickly04]およびOWL(Web Ontology Language) [Smith04]を用いることが増えている。
RDF(およびOWL)でエンティティの記述を表現するとは、オントロジー上の概念(これもまたエンティティである)や他の個体(individual)を示すエンティティとの関係でそのエンティティの記述を行うことである。特に他の個体のエンティティとの関係を記述することは、HTMLページで他のHTMLページに対するリンクを作ることに相当する。通常のHTMLページがつくるWebがWeb of Documentsであるならば、RDF記述がつくるWebはWeb of Dataであるといえる。
このようなRDFがつくる情報のネットワークをLinked Dataと呼び、近年Webで急速に普及している。
なお、Linked Dataは基本的に個体に関する情報を取り扱う。個体でなくオントロジー上の概念間に関連づけはオントロジーマッピングという形で研究されている。この問題には今回は触れないので、興味のある方は[市瀬07]を参照されたい。
また動的なデータに関してはセマンティックWebサービス[McIlraith01]の枠組みを使うことも考えられるが、まだきちんと考察されている例は少ない。ここでは静的なデータのみを考える。
5.1 Linked Dataの現状
Webの創始者であり、現在World Wide Web Consortium (W3C)のdirectorであるTim Berners-LeeはLinked Dataを次のように定義している[Berners-Lee06]。
(1) 事柄の名前にURIを使うこと
すべてのモノ,コトにURIを!
(2) 名前の参照がHTTP URIでできること
URNとか独自のプロトコルは使わないように
(3) URIを参照したときに関連情報が手に入るように
理解可能なデータを提供するように
(4) 外部へのリンクも含めよう
Webのようにリンクでつながるデータを作ろう
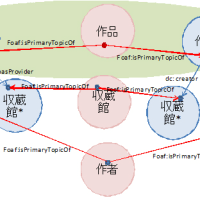
現在,Linked Dataがどんな状況であるかを図2に示す.この中でDBpedia (http://dbpedia.org/)というのはWikipediaの情報のうち,infoboxの情報を中心に機械的に抜き出し,RDFのデータとして書きだしたものである.現在,約1.1億RDF文が公開されている.またこの中の地名に関してはGeoNamesというデータの相互にリンクがある.GeoNames自体は約7千万文ある.この関係は図中で相互リンクとして書かれている.
この例でもわかるようにLinked Dataは名前の通り相互にリンクしあうからこそ価値がある.そのためにデータはオープンであることが望ましい(必須ではないが).そこでオープンなLinked Dataを普及しようというプロジェクトLinking Open Data Project (http://esw.w3.org/topic/SweoIG/TaskForces/CommunityProjects/LinkingOpenData)がW3Cのメンバーらで行われている.
このようにRDFデータが相互にリンクしあうことで巨大なデータ空間を作っている.そうするとこのデータを使うアプリケーションが可能になる.
例えば,SemaPlorer (http://btc.isweb.uni-koblenz.de/)はGoogle mapを中心にDBpedia, Geonames, flickrデータをマッシュアップして作られている.そこでは単にデータを結合して検索する以上のサービスを提供している.
またすでに”Linked Planet Data Conference”と呼ばれるビジネスカンファレンスシリーズ が開かれるようになっている [Shakya08].
5.2 アイデンティティ利用としてのLinked Dataの問題点
Linked DataはWebである以上、分散的である。このことはアイデンティティの表現と利用において二つの問題を提起している。これはWeb特有というより分散システムがアイデンティティを取り扱うときに生じる一般的な問題であると思われる。
(1) エンティティの同一化
分散的に管理されている以上、同一エンティティを二つの異なるサイトがアイデンティティを与えることがあり得ることである。このとき、Linked Dataではowl:sameAsという述語で二つのURIが同一であるということ指示する。こうすることでコンピュータが異なるサイトにあるRDFSやOWLで書かれた情報を統合して解釈して推論することができる。
しかしこれは様々な問題を引き起こす。「明けの明星」と「宵の明星」の同一性に例示される古典的なフレーゲのパズルに相当する。一度、同一化してしまうとこの先、区別がつかなくなる。例えば、GeoNamesにおけるTokyoとDBpedia (Wikipedia)におけるTokyoを同一化したとする。しかしGeoNamesにおけるTokyoは純粋に地理的な存在としてのTokyoであり、WikipediaのTokyoはより幅広い意味でのTokyoの記述である 。
異なるサイトのエンティティが厳密な意味で同一であることはまれであろう。しかし、実用的な意味では同一化したいケースが多い(でないとLinked Dataは存在し得ない)。単にowl:sameAsで結びつけるだけは解決できない。
(2) どの記述を採用すべきか
誰かがあるエンティティをURIとして公開したら、そのURIを他の人が使うことは許されている。むしろ積極的に使おうというのがLinked Dataの精神である。すなわち、様々な人がRDF等を用いてエンティティに関する記述をする。例えば、ソーシャルブックマーキングでは一つのエンティティの多数の人々が記述を追加している。
このときに間違った記述、矛盾する記述が含まれていたときにどうしたらよいであろうか。
まず考えられるのはそのエンティティ登録の持ち主の記述を信じるべきであろう。URIを参照(dereference)したときに得られる記述があれば、たぶん持ち主の記述であろう。持ち主の記述がない場合、信頼すべきサイトを優先すべきであろう。
しかし、現在のRDFSやOWLには記述の持ち主という概念がない。これはNamed Graph [Carroll04]など別の仕組みが必要である。またサイトの信頼性をはかるというのは現在でも難しい問題である。
通常のWebであれば人間が読んで判断することでこの問題を回避しているが、Linked Dataではコンピュータが処理するので、この問題は回避することができない。
(続く)
前章でみてきたようにURIを中心にエンティティのアイデンティティをWebの世界で表現できる。とくに説明情報をコンピュータ可読の情報とすることでコンピュータが処理可能な世界を作ることができる。その記述方法としてRDF(Resource Description Framework) [Manola04] [Brickly04]およびOWL(Web Ontology Language) [Smith04]を用いることが増えている。
RDF(およびOWL)でエンティティの記述を表現するとは、オントロジー上の概念(これもまたエンティティである)や他の個体(individual)を示すエンティティとの関係でそのエンティティの記述を行うことである。特に他の個体のエンティティとの関係を記述することは、HTMLページで他のHTMLページに対するリンクを作ることに相当する。通常のHTMLページがつくるWebがWeb of Documentsであるならば、RDF記述がつくるWebはWeb of Dataであるといえる。
このようなRDFがつくる情報のネットワークをLinked Dataと呼び、近年Webで急速に普及している。
なお、Linked Dataは基本的に個体に関する情報を取り扱う。個体でなくオントロジー上の概念間に関連づけはオントロジーマッピングという形で研究されている。この問題には今回は触れないので、興味のある方は[市瀬07]を参照されたい。
また動的なデータに関してはセマンティックWebサービス[McIlraith01]の枠組みを使うことも考えられるが、まだきちんと考察されている例は少ない。ここでは静的なデータのみを考える。
5.1 Linked Dataの現状
Webの創始者であり、現在World Wide Web Consortium (W3C)のdirectorであるTim Berners-LeeはLinked Dataを次のように定義している[Berners-Lee06]。
(1) 事柄の名前にURIを使うこと
すべてのモノ,コトにURIを!
(2) 名前の参照がHTTP URIでできること
URNとか独自のプロトコルは使わないように
(3) URIを参照したときに関連情報が手に入るように
理解可能なデータを提供するように
(4) 外部へのリンクも含めよう
Webのようにリンクでつながるデータを作ろう
現在,Linked Dataがどんな状況であるかを図2に示す.この中でDBpedia (http://dbpedia.org/)というのはWikipediaの情報のうち,infoboxの情報を中心に機械的に抜き出し,RDFのデータとして書きだしたものである.現在,約1.1億RDF文が公開されている.またこの中の地名に関してはGeoNamesというデータの相互にリンクがある.GeoNames自体は約7千万文ある.この関係は図中で相互リンクとして書かれている.
この例でもわかるようにLinked Dataは名前の通り相互にリンクしあうからこそ価値がある.そのためにデータはオープンであることが望ましい(必須ではないが).そこでオープンなLinked Dataを普及しようというプロジェクトLinking Open Data Project (http://esw.w3.org/topic/SweoIG/TaskForces/CommunityProjects/LinkingOpenData)がW3Cのメンバーらで行われている.
このようにRDFデータが相互にリンクしあうことで巨大なデータ空間を作っている.そうするとこのデータを使うアプリケーションが可能になる.
例えば,SemaPlorer (http://btc.isweb.uni-koblenz.de/)はGoogle mapを中心にDBpedia, Geonames, flickrデータをマッシュアップして作られている.そこでは単にデータを結合して検索する以上のサービスを提供している.
またすでに”Linked Planet Data Conference”と呼ばれるビジネスカンファレンスシリーズ が開かれるようになっている [Shakya08].
5.2 アイデンティティ利用としてのLinked Dataの問題点
Linked DataはWebである以上、分散的である。このことはアイデンティティの表現と利用において二つの問題を提起している。これはWeb特有というより分散システムがアイデンティティを取り扱うときに生じる一般的な問題であると思われる。
(1) エンティティの同一化
分散的に管理されている以上、同一エンティティを二つの異なるサイトがアイデンティティを与えることがあり得ることである。このとき、Linked Dataではowl:sameAsという述語で二つのURIが同一であるということ指示する。こうすることでコンピュータが異なるサイトにあるRDFSやOWLで書かれた情報を統合して解釈して推論することができる。
しかしこれは様々な問題を引き起こす。「明けの明星」と「宵の明星」の同一性に例示される古典的なフレーゲのパズルに相当する。一度、同一化してしまうとこの先、区別がつかなくなる。例えば、GeoNamesにおけるTokyoとDBpedia (Wikipedia)におけるTokyoを同一化したとする。しかしGeoNamesにおけるTokyoは純粋に地理的な存在としてのTokyoであり、WikipediaのTokyoはより幅広い意味でのTokyoの記述である 。
異なるサイトのエンティティが厳密な意味で同一であることはまれであろう。しかし、実用的な意味では同一化したいケースが多い(でないとLinked Dataは存在し得ない)。単にowl:sameAsで結びつけるだけは解決できない。
(2) どの記述を採用すべきか
誰かがあるエンティティをURIとして公開したら、そのURIを他の人が使うことは許されている。むしろ積極的に使おうというのがLinked Dataの精神である。すなわち、様々な人がRDF等を用いてエンティティに関する記述をする。例えば、ソーシャルブックマーキングでは一つのエンティティの多数の人々が記述を追加している。
このときに間違った記述、矛盾する記述が含まれていたときにどうしたらよいであろうか。
まず考えられるのはそのエンティティ登録の持ち主の記述を信じるべきであろう。URIを参照(dereference)したときに得られる記述があれば、たぶん持ち主の記述であろう。持ち主の記述がない場合、信頼すべきサイトを優先すべきであろう。
しかし、現在のRDFSやOWLには記述の持ち主という概念がない。これはNamed Graph [Carroll04]など別の仕組みが必要である。またサイトの信頼性をはかるというのは現在でも難しい問題である。
通常のWebであれば人間が読んで判断することでこの問題を回避しているが、Linked Dataではコンピュータが処理するので、この問題は回避することができない。
(続く)