(現在執筆中の解説記事の草稿です。乞ご意見、コメント)
1. 私たちのLinked Data?
Linked Dataはデータの共有の新しい方法として欧米で認知され、実践が進んでいる。日本においてはどうだろうか。セマンティックWeb自体の未普及もあって、まだ認知すらされているとはいえない状況である。日本においてもLinked Dataは可能のだろうか。いやそれ以前にそもそもLinked Dataは日本に必要なのだろうか。
本稿では日本におけるLinked Data化活動を概観する。
まず、前提としてなぜLinked Dataが必要なのかから考察をはじめる。情報共有の問題である。これはLinked Dataだけに関わる問題ではないのだが、Linked Dataというのは情報共有の新しい世界である以上、避けて通れない。その上で、日本あるいは日本語固有の課題を挙げ、どのような解決法があるか考える。最後に具体的に大規模なLinked DataあるいはRDFを提供している活動を取り上げ、説明する。
2.Linked Dataの社会的意義
当たり前のことだが、Web技術の発展の先にLinked Dataがある。その重要性は情報技術者や研究者にとっては比較的わかりやすいが、社会的意義をきちんと説明できないと、広く公開のデータをつくろうというLinking Open Data(LOD)活動は参加者や理解者を増やすことができない。そこで本節ではまずWebの社会的位置づけから考えることで、まぜLODが社会的な意義があるかについて述べる。
2.1.情報循環としてのWeb
Webの社会的意義とは、情報の社会的循環の大規模化・高速化こそが情報の価値を高めると言うことを実践的に知らしめた点である。
情報というのは単に作られただけでは価値がない。当然、他の人たちに伝達され、利用されてこそ価値が生まれる。ある人によって他の人の情報に基づき新たな情報が作られ、それがまた他の人に使われて新しい情報が作られる。この循環こそが我々の社会での情報を豊かにさせてきた源泉である。個人的な情報伝達手段しかなかった時代には、利用・創造-伝達-利用・創造-…という単純なものでしかなく、極めて遅く小規模なものであった。
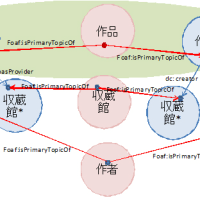
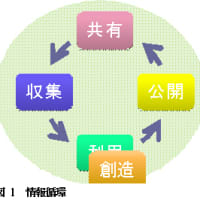
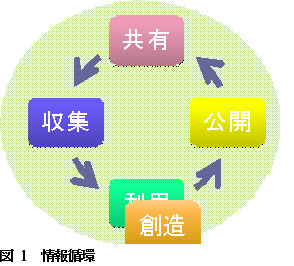
マスメディアの登場により公共的な情報循環が始まった。すなわち、利用・創造-公開-収集-共有-利用・創造-...となった(図1参照)。個人的な情報伝達に比べ、格段に速く規模も大きくなった。この仕組みにより多くの職業的情報創造者(ジャーナリスト、作家、作詞者、作曲者等)が生まれた一方、情報を公開できる人間はそういった職業的情報創造者やメディア関係者に限られており、情報循環への関与という点では偏っていた。すなわち情報を創造して公開できるのは一部の人々であり、多くの人々は単に利用者でしかないという偏りである。
Webはこの偏りを直す仕組みを提供した。すなわち、だれでも自らの情報を公開し共有することができる。無料あるいは極めて低料金で自らの情報を他者に利用可能な形で公開することができる。また公開された情報は一元的なコントロールなどをうけることなく自由に共有され、自由に利用することができる。この結果、情報循環はかつてないほど多数の参加者により大規模かつ高速に行われるようになった。
2.2.情報循環としてのセマンティックWeb
このように情報循環に新しい時代をつくったWebであるが、さまざまな課題も生まれてきた。その中の一つがデータのコンピュータでの利用である。
Webの仕組みは当然のことながらコンピュータとコンピュータネットワークによって実現されている。しかし、情報循環には人間が関与することが前提になっていて、コンピュータにはあまり適切でない。顕著なのがHTMLで、HTMLによる情報の構造は人間が理解するために使われており、これだけではコンピュータがそこに書かれている情報を適切に処理することができない。
その克服のための仕組みがセマンティックWebである。セマンティックWebは人間とコンピュータ双方が情報の内容をより多く理解でき共有できるように、情報の意味を与える仕組みを用意している。それがセマンティックWeb言語であるRDFSやOWLである。
2.3.情報循環としてのLinked Data
Linked Dataはセマンティック Webのうち、個別の情報(インスタンス)を重視して情報公開・共有を行うというものである。セマンティックWebの構想はいくつかの階層からなる。図2は最も初期のころのセマンティックWebの階層である。このうち、研究としては下位から上位へ、すなわちRDF記述のレベルからオントロジーへ、そしてさらに上位へと進んでいる。
しかし、言語が整備されたとしてもオントロジーを実際構築して共有していくのは大変なことである。オントロジーが広く共有されていれば、それに基づいた情報の共有は容易になる。しかし、それを待っていてはなかなか
進捗しない。
Linked Dataではオントロジーの共有はひとまずおいておき、まずはデータの共有をしましょうというところに特徴がある。それがTim Berners-LeeのいうところのLinked Dataの3原則(1章参照)である。概念レベルのオントロジーの共有は一朝一夕ではできないが、個別のデータの共有は比較的容易だと言うことである。これがLinked Dataの狙いであり、実際大きな勢いでデータが増えている。
2.4 情報循環としてのLOD
Linking Open Data(LOD)はLinked Dataとして情報を共有していこうという活動である。Linked Dataの性質として相互につながってこそ意味があるので、そのつながりを集めて公開することでデータの利用を促進したり、より多くの参加者を集めようとしている。
LODにおいて公共セクターは重要な部分である。というのは元々公共セクターの情報は国民・市民に公開されている情報である。当然公開された情報は利用されることを期待されている。Web以前は紙媒体や限定されたデータベースとして公開していたが、Web以後はHTMLやPDFで公開されるようなった。しかし、HTMLやPDFで公開された情報はデータとしての利用は難しい。個別の処理をしないと、そこから必要なデータを抜き出すことができない。Linked Dataの形式でデータを公開することで、こういった個別の処理なしでデータを利用可能になる。
また、公共セクターは社会において重要かつ大量のデータを抱えている。もちろんプラバシーや国家機密に関わることはそもそも公開情報でないので除外するとしても、それ以外にも大量の情報を抱えている。この情報をLinked Dataの情報循環に入れることは、情報循環が前提の社会として、必須なことといえよう。すなわち公共セクターはLODに情報提供をすることで情報循環のインフラを支えることが期待されている。
もちろん個別の企業や団体の情報も社会的な価値を多く持っている。その多くの情報の価値は社会における情報循環によって支えられている。とすれば公開可能な情報はむしろより利用されやすい形式で公開することがその価値を上げることになる。その仕組みとしてLODを使うのは企業的にみても十分意義のあるものであると考える。
1. 私たちのLinked Data?
Linked Dataはデータの共有の新しい方法として欧米で認知され、実践が進んでいる。日本においてはどうだろうか。セマンティックWeb自体の未普及もあって、まだ認知すらされているとはいえない状況である。日本においてもLinked Dataは可能のだろうか。いやそれ以前にそもそもLinked Dataは日本に必要なのだろうか。
本稿では日本におけるLinked Data化活動を概観する。
まず、前提としてなぜLinked Dataが必要なのかから考察をはじめる。情報共有の問題である。これはLinked Dataだけに関わる問題ではないのだが、Linked Dataというのは情報共有の新しい世界である以上、避けて通れない。その上で、日本あるいは日本語固有の課題を挙げ、どのような解決法があるか考える。最後に具体的に大規模なLinked DataあるいはRDFを提供している活動を取り上げ、説明する。
2.Linked Dataの社会的意義
当たり前のことだが、Web技術の発展の先にLinked Dataがある。その重要性は情報技術者や研究者にとっては比較的わかりやすいが、社会的意義をきちんと説明できないと、広く公開のデータをつくろうというLinking Open Data(LOD)活動は参加者や理解者を増やすことができない。そこで本節ではまずWebの社会的位置づけから考えることで、まぜLODが社会的な意義があるかについて述べる。
2.1.情報循環としてのWeb
Webの社会的意義とは、情報の社会的循環の大規模化・高速化こそが情報の価値を高めると言うことを実践的に知らしめた点である。
情報というのは単に作られただけでは価値がない。当然、他の人たちに伝達され、利用されてこそ価値が生まれる。ある人によって他の人の情報に基づき新たな情報が作られ、それがまた他の人に使われて新しい情報が作られる。この循環こそが我々の社会での情報を豊かにさせてきた源泉である。個人的な情報伝達手段しかなかった時代には、利用・創造-伝達-利用・創造-…という単純なものでしかなく、極めて遅く小規模なものであった。
マスメディアの登場により公共的な情報循環が始まった。すなわち、利用・創造-公開-収集-共有-利用・創造-...となった(図1参照)。個人的な情報伝達に比べ、格段に速く規模も大きくなった。この仕組みにより多くの職業的情報創造者(ジャーナリスト、作家、作詞者、作曲者等)が生まれた一方、情報を公開できる人間はそういった職業的情報創造者やメディア関係者に限られており、情報循環への関与という点では偏っていた。すなわち情報を創造して公開できるのは一部の人々であり、多くの人々は単に利用者でしかないという偏りである。
Webはこの偏りを直す仕組みを提供した。すなわち、だれでも自らの情報を公開し共有することができる。無料あるいは極めて低料金で自らの情報を他者に利用可能な形で公開することができる。また公開された情報は一元的なコントロールなどをうけることなく自由に共有され、自由に利用することができる。この結果、情報循環はかつてないほど多数の参加者により大規模かつ高速に行われるようになった。
2.2.情報循環としてのセマンティックWeb
このように情報循環に新しい時代をつくったWebであるが、さまざまな課題も生まれてきた。その中の一つがデータのコンピュータでの利用である。
Webの仕組みは当然のことながらコンピュータとコンピュータネットワークによって実現されている。しかし、情報循環には人間が関与することが前提になっていて、コンピュータにはあまり適切でない。顕著なのがHTMLで、HTMLによる情報の構造は人間が理解するために使われており、これだけではコンピュータがそこに書かれている情報を適切に処理することができない。
その克服のための仕組みがセマンティックWebである。セマンティックWebは人間とコンピュータ双方が情報の内容をより多く理解でき共有できるように、情報の意味を与える仕組みを用意している。それがセマンティックWeb言語であるRDFSやOWLである。
2.3.情報循環としてのLinked Data
Linked Dataはセマンティック Webのうち、個別の情報(インスタンス)を重視して情報公開・共有を行うというものである。セマンティックWebの構想はいくつかの階層からなる。図2は最も初期のころのセマンティックWebの階層である。このうち、研究としては下位から上位へ、すなわちRDF記述のレベルからオントロジーへ、そしてさらに上位へと進んでいる。
しかし、言語が整備されたとしてもオントロジーを実際構築して共有していくのは大変なことである。オントロジーが広く共有されていれば、それに基づいた情報の共有は容易になる。しかし、それを待っていてはなかなか
進捗しない。
Linked Dataではオントロジーの共有はひとまずおいておき、まずはデータの共有をしましょうというところに特徴がある。それがTim Berners-LeeのいうところのLinked Dataの3原則(1章参照)である。概念レベルのオントロジーの共有は一朝一夕ではできないが、個別のデータの共有は比較的容易だと言うことである。これがLinked Dataの狙いであり、実際大きな勢いでデータが増えている。
2.4 情報循環としてのLOD
Linking Open Data(LOD)はLinked Dataとして情報を共有していこうという活動である。Linked Dataの性質として相互につながってこそ意味があるので、そのつながりを集めて公開することでデータの利用を促進したり、より多くの参加者を集めようとしている。
LODにおいて公共セクターは重要な部分である。というのは元々公共セクターの情報は国民・市民に公開されている情報である。当然公開された情報は利用されることを期待されている。Web以前は紙媒体や限定されたデータベースとして公開していたが、Web以後はHTMLやPDFで公開されるようなった。しかし、HTMLやPDFで公開された情報はデータとしての利用は難しい。個別の処理をしないと、そこから必要なデータを抜き出すことができない。Linked Dataの形式でデータを公開することで、こういった個別の処理なしでデータを利用可能になる。
また、公共セクターは社会において重要かつ大量のデータを抱えている。もちろんプラバシーや国家機密に関わることはそもそも公開情報でないので除外するとしても、それ以外にも大量の情報を抱えている。この情報をLinked Dataの情報循環に入れることは、情報循環が前提の社会として、必須なことといえよう。すなわち公共セクターはLODに情報提供をすることで情報循環のインフラを支えることが期待されている。
もちろん個別の企業や団体の情報も社会的な価値を多く持っている。その多くの情報の価値は社会における情報循環によって支えられている。とすれば公開可能な情報はむしろより利用されやすい形式で公開することがその価値を上げることになる。その仕組みとしてLODを使うのは企業的にみても十分意義のあるものであると考える。