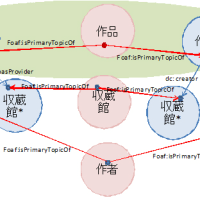
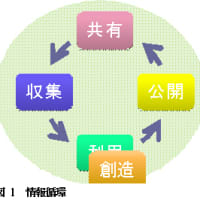
あとは参加したセッションと気になった発表など。
基本的にsocial network, semanic web, linked dataを中心に聴講。
ちょっとした聴講メモ。
**Social Web**
*** Tagommenders: Connecting Users to Items through Tags
233 Shilad Sen, Jesse Vig and John Riedl
MovieLensやsocial taggingのデータを使ってrecommendationをするという研究。
Basian Networkなど3種類のアルゴリズムをつかい、総合的に推定。
<よく調べられた研究。>
*** Collaborative Filtering for Orkut Communities: Discovery of User Latent Behavior
365 Wen-Yen Chen, Jon-Chyuan Chu, Junyi Luan, Hongjie Bai and Edward Chang
Orkutにおける community recommendation
Association rules mining (ARM)
Latent Dirichlet Allocation (LDA)
の両方を使って比較。
あと並列化の効果。
*** Personalized Recommendation on Dynamic Contents Using Predictive
Bilinear Models
713 Wei Chu and Seung-Taek Park
Yahoo!のトップページのように動的に変わるページをPersonalizeする話。
Colloborative filteringでは新ユーザや新コンテンツ対応が難しい。
ユーザとコンテンツのfeatureを抽出してfeature-basedでrecommendationをする。
<かなり実践的な話のようだ。>
*** Network Analysis of Collaboration Structure in Wikipedia
115 Ulrik Brandes, Patrick Kenis, Juergen Lerner and Denise van Raaij
Wikipediaのedit networkの分析。
<何か新しいのか??>
*** Social Search in "Small World" Experiments
45 Sharad Goel, Roby Muhamad and Duncan Watts
Mirigramの6次の隔たりの検証。
<これは面白い。丁寧に論文を読んでみないと。。。>
Track: Social Networks and Web 2.0 / Session: Photos and Web 2.0
*** Mapping the World's Photos (Page 761)
David Crandall (Cornell University)
Lars Backstrom (Cornell University)
Daniel Huttenlocher (Cornell University)
Jon Kleinberg (Cornell University)
Best Paper 候補
GeoTagの集中度のくらlandmarkを発見。そのLandmarkを代表するphoto
をtagの共通から発見。
逆にラベルのない写真をどのlandmarkかを推定
<geotagつきのflikrのデータの膨大さに驚く。その集中度をうまく使い、画像を解釈せずに処理。うまい。>
*** Constructing Folksonomies from User-Specified Relations on
Flickr (Page 781)
Anon Plangprasopchok (University of Southern California)
Kristina Lerman (University of Southern California)
metadataから隠れた階層構造を発見する。
Flikr自身のcollectionから単語間の階層関係生成
Signifanceで切る。
複数Pathはflow bottleneckで選択
ODPと比較
<これってsematic webの方ではよくやられている手法。画像系だから新しい?>
Mining-5 Andrew Tomkins
*** Learning Consensus Opinion:Mining Data from a Labeling Game
556 Paul Bennett, Max Chickering and Anton Mityagin
Image Gameのデータの分析。
単語と2-5程度のイメージをみせて一つ選択。二人が合うとAgree。
そのときのデータをMS SearchのRankingと比較。
<このMSのlabeling gameネタは2つぐらいあったと思います。そんなに重要な研究なんだろうか。まだよく理解できていません。>
Semantic Data Management
*** Rapid Semantic Web Mashup Development through Semantic Web Pipes
160 Danh Le Phuoc, Axel Polleres, Giovanni Tummarello, Christian Morbidoni and Manfred Hauswirth
Yahoo! PipesならぬSW Pipesの実装
<これは前にも紹介されていたが、普通に使えそうで面白い。>
Linked Data
*** Large Scale Integration of Senses for the Semantic Web
525 Jorge Gracia, Mathieu d'Aquin and Eduardo Mena
たくさんあるオントロジーの同じ概念を統合することに関する考察。
閾値をどこにおくかを実験。
*** Triplify - Light-weight Linked Data Publication from Relational
Databases
1 Soren Auer, Sebastian Dietzold, Jens Lehmann, Sebastian Hellmann and David Aumueller
RDBからRDFを作り出す話。
RDBからRDFを引き出すSQLパターンをたくさん用意しておく。
WordPress とかシステムごとに用意する。
<安直だが、結構はやるかも。>
*** Extracting Key Terms From Noisy and Multitheme Documents
366 Maria Grineva, Dmitry Lizorkin and Maxim Grinev
wikipediaから単語の関係グラフをつくり、そこからNewmanコミュニティを抽出してランキング。それを単語の重要度などに使う。
<え、それでいいのか?>
****
やっぱり5日目ぐらいになるとだれて理解力が落ちてますね。反省。
WWW2009は論文発表はちょっとクオリティにばらつきがある。各トラックごとセレクションが厳しすぎて研究のクオリティにまして論文自体のクオリティが効いてしまっているのかなあ。
(おしまい)
基本的にsocial network, semanic web, linked dataを中心に聴講。
ちょっとした聴講メモ。
**Social Web**
*** Tagommenders: Connecting Users to Items through Tags
233 Shilad Sen, Jesse Vig and John Riedl
MovieLensやsocial taggingのデータを使ってrecommendationをするという研究。
Basian Networkなど3種類のアルゴリズムをつかい、総合的に推定。
<よく調べられた研究。>
*** Collaborative Filtering for Orkut Communities: Discovery of User Latent Behavior
365 Wen-Yen Chen, Jon-Chyuan Chu, Junyi Luan, Hongjie Bai and Edward Chang
Orkutにおける community recommendation
Association rules mining (ARM)
Latent Dirichlet Allocation (LDA)
の両方を使って比較。
あと並列化の効果。
*** Personalized Recommendation on Dynamic Contents Using Predictive
Bilinear Models
713 Wei Chu and Seung-Taek Park
Yahoo!のトップページのように動的に変わるページをPersonalizeする話。
Colloborative filteringでは新ユーザや新コンテンツ対応が難しい。
ユーザとコンテンツのfeatureを抽出してfeature-basedでrecommendationをする。
<かなり実践的な話のようだ。>
*** Network Analysis of Collaboration Structure in Wikipedia
115 Ulrik Brandes, Patrick Kenis, Juergen Lerner and Denise van Raaij
Wikipediaのedit networkの分析。
<何か新しいのか??>
*** Social Search in "Small World" Experiments
45 Sharad Goel, Roby Muhamad and Duncan Watts
Mirigramの6次の隔たりの検証。
<これは面白い。丁寧に論文を読んでみないと。。。>
Track: Social Networks and Web 2.0 / Session: Photos and Web 2.0
*** Mapping the World's Photos (Page 761)
David Crandall (Cornell University)
Lars Backstrom (Cornell University)
Daniel Huttenlocher (Cornell University)
Jon Kleinberg (Cornell University)
Best Paper 候補
GeoTagの集中度のくらlandmarkを発見。そのLandmarkを代表するphoto
をtagの共通から発見。
逆にラベルのない写真をどのlandmarkかを推定
<geotagつきのflikrのデータの膨大さに驚く。その集中度をうまく使い、画像を解釈せずに処理。うまい。>
*** Constructing Folksonomies from User-Specified Relations on
Flickr (Page 781)
Anon Plangprasopchok (University of Southern California)
Kristina Lerman (University of Southern California)
metadataから隠れた階層構造を発見する。
Flikr自身のcollectionから単語間の階層関係生成
Signifanceで切る。
複数Pathはflow bottleneckで選択
ODPと比較
<これってsematic webの方ではよくやられている手法。画像系だから新しい?>
Mining-5 Andrew Tomkins
*** Learning Consensus Opinion:Mining Data from a Labeling Game
556 Paul Bennett, Max Chickering and Anton Mityagin
Image Gameのデータの分析。
単語と2-5程度のイメージをみせて一つ選択。二人が合うとAgree。
そのときのデータをMS SearchのRankingと比較。
<このMSのlabeling gameネタは2つぐらいあったと思います。そんなに重要な研究なんだろうか。まだよく理解できていません。>
Semantic Data Management
*** Rapid Semantic Web Mashup Development through Semantic Web Pipes
160 Danh Le Phuoc, Axel Polleres, Giovanni Tummarello, Christian Morbidoni and Manfred Hauswirth
Yahoo! PipesならぬSW Pipesの実装
<これは前にも紹介されていたが、普通に使えそうで面白い。>
Linked Data
*** Large Scale Integration of Senses for the Semantic Web
525 Jorge Gracia, Mathieu d'Aquin and Eduardo Mena
たくさんあるオントロジーの同じ概念を統合することに関する考察。
閾値をどこにおくかを実験。
*** Triplify - Light-weight Linked Data Publication from Relational
Databases
1 Soren Auer, Sebastian Dietzold, Jens Lehmann, Sebastian Hellmann and David Aumueller
RDBからRDFを作り出す話。
RDBからRDFを引き出すSQLパターンをたくさん用意しておく。
WordPress とかシステムごとに用意する。
<安直だが、結構はやるかも。>
*** Extracting Key Terms From Noisy and Multitheme Documents
366 Maria Grineva, Dmitry Lizorkin and Maxim Grinev
wikipediaから単語の関係グラフをつくり、そこからNewmanコミュニティを抽出してランキング。それを単語の重要度などに使う。
<え、それでいいのか?>
****
やっぱり5日目ぐらいになるとだれて理解力が落ちてますね。反省。
WWW2009は論文発表はちょっとクオリティにばらつきがある。各トラックごとセレクションが厳しすぎて研究のクオリティにまして論文自体のクオリティが効いてしまっているのかなあ。
(おしまい)