








今日は、あるお客さんの依頼でシステム規模の見積をFPで行った。
依頼のあったシステムは、2つでともに生産管理のシステムでした。 計測規模としては、1つが400FPほどでもう一つが700FPぐらいでしたが、この2つのシステムの規模見積を2~3日でやって欲しいという依頼で・・・
まあ、なんとかやり遂げましたが、疲れました~。
もともとのリクエストとしては、現在、自社で見積を実施しているが、IFPUGのCPMで見積もった場合と、どの程度の違いがあるのかということを実際のプロジェクトで作成した成果物(ドキュメント)をもとに比較するというものでした。
もちろん、お客さんの方で見積もった規模がどの程度なのかはわかりませんので、近い値が出ているのか、それともかけ離れた値となっているのか・・・(ちょっと心配ではあります。)
最近はUMLで仕様を記述するお客様(我が社にとってのお客様はSIerさんです。)が多いようで、UMLドキュメントからFPの見積を行うという作業を行いました。
1.トランザクションファンクション
(1)トランザクションファンクションの識別
まずは、ユースケースとユースケース記述書からトランザクションファンクションを洗い出していきました。
ユースケース記述(シナリオ記述)の中に「システムは**する」と明確に記述されていましたので、その記述から要素処理の候補を挙げていくことは、わりと簡単にできたように思います。
しかし、単なる画面遷移やダイアログの表示といったものがありますので、そのような処理は対象外としていきます。(CPMでは、操作のナビゲーション機能はファンクションとはなりません。)
また、トランザクションファンクションの基準としてデータ(テーブル)にアクセスする処理なのかどうかを検討していくと、割と判断し易いかもしれません。
データ(テーブル)にアクセスしないものはファンクションの対象外とします。
例えば、ComboBoxが存在し、リストの中から選択するという処理があったとします。
その場合、マスタから都度データを読み込んでリスト表示しているような処理はトランザクションファンクションとなります。
しかし、予め決められている値を単にリスト表示しているだけでは、トランザクションファンクションとはなりません。
さらに、その処理がユーザに対して何らかの効用を提供しているかどうか(システムがその処理をしてくれるとユーザがうれしいかどうか)という基準で判断します。
ユーザに対して何らの効用も提供していない処理は要素処理とはなりえません。
(2)トランザクションファンクションのタイプ判定
要素処理を識別したら、今度はトランザクションファンクションのタイプ判定です。
ざっくり、入力系の処理と出力系の処理にまず分けて考えます。
入力系の処理(登録、更新、削除)については、これは外部入力(EI)に分類すればいいでしょう。
出力系の処理については、当該要素処理がデータベースの値を単に出力しているかどうかを判断します。 何の加工もせずに、データ(テーブル)の情報を外部に出力しているだけであれば、それは外部照会(EQ)となります。
出力系の要素処理で、何らかの加工(処理)を行っている要素処理は外部出力(EO)に分類していきます。
(3)DETとFTRの集計と複雑度の判定
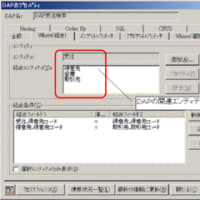
あとは、それぞれの要素処理で取り扱っているデータ要素(データ項目)の数と関連しているデータ(テーブル)の数をカウントしていけば、複雑度を判定し未調整のファンクションポイントを算出することができます。
データ要素の数も、基本的には画面や帳票インタフェースを見ながらカウントしていきます。(今回の作業では、きちんとユーザインタフェース仕様が整理されていたので、その点は楽でした。)
あと、関連ファイル数(FTR)ですが、これはやはりデータ構造(エンティティ)を意識しながら行わないと、なかなかイメージできません。
今回の作業では、ERwin(最近、知らない人も多いかもしれませんが、数年前まではデータベース設計のツールといえば、ERwinでした。そうそう、Xupperも・・・)でデータモデル(エンティティ関連図)が整理されていましたので、イメージはし易かったのですが・・・
データ要素数(DET)と関連ファイル数(FTR)が把握できたら、CPMに規定されている基準で評価すれば自動的に書くファンクションの複雑を算出できますし、複雑度が決まれば未調整のファンクションポイントも求めることができます。
2.データファンクション
(1)データファンクションの識別
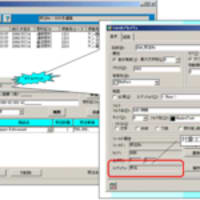
前述したように、データモデル(エンティティ関連図)ができていましたので、エンティティをそのままデータファンクションとして捉えて作業を行います。
ここで注意する点としては、概念的に同一(ユーザから見て同じ意味)のデータは1データファンクションとして捉えるということです。
例えば、実際には受注テーブルと受注明細テーブルがそれぞれ存在していたとしても、ユーザから見れば受注テーブルと受注明細テーブルを合わせて初めて業務的に意味のある受注データになります。
このような整理はデータモデル(エンティティ関連図)を利用します。
従属関係(依存関係)に着目して検討していけばわりと簡単に整理できます。
参照関係(非依存関係)のエンティティは、それぞれが独立して存在しうるという性質を持っていますので、同一概念であるかどうかの検討の対象から外します。
従属関係(依存関係)にこそ、それぞれがセットになって初めて業務的に意味を持つというものものが含まれていますので、そこに着目して整理しています。
このようにしてデータファンクションを識別していきます。
(2)データファンクションのタイプ判定
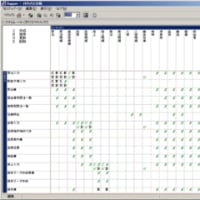
次にデータファンクションのタイプわけですが、私自身はCRUDという整理を行うようにしています。
C:Create
R:Read
U:Update
D:Delete
です。
このCRUDが整理できれば、トランザクションから参照だけされているものとそれ以外に分類します。
Rだけが定義されているデータは、当該アプリケーション境界の中の処理では、参照だけされているデータであると考え、これは外部インタフェースファイル(EIF)とします。
それ以外(C,U,Dが定義されているデータ)は、当該アプリケーション境界の中の処理で追加、変更、削除されているわけですから、維持管理されていると考え内部論理ファイル(ILF)として分類します。
(3)DETとRETの集計と複雑度の判定
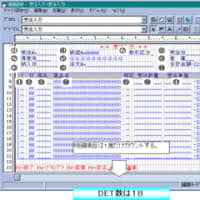
データファンクションのタイプを識別したら、今度はデータファンクションのデータ要素数(DET)とレコード要素数(RET)を識別していきます。
レコード要素数(RET)としては、前述の概念的に同一のデータとなるものをとしてカウントしていきます。
また、データファンクションのデータ要素数につてはテーブルの項目数(エンティティの属性数)をカウントすればよいでしょう。
ここで注意して欲しいのは、同一概念のデータについては、該当データの項目についてもデータ要素数としてカウントするということです。
データ要素数(DET)とレコード要素数(RET)が把握できたら、CPMに規定されている基準で評価すれば自動的に書くファンクションの複雑を算出できますし、複雑度が決まれば未調整のファンクションポイントも求めることができます。







※コメント投稿者のブログIDはブログ作成者のみに通知されます