








MAGMA GEMM Sources for Fermi Released
2010-08-04
The MAGMA BLAS SGEMM and DGEMM sources for Fermi GPUs are now released.
These improved GEMMs, developed by Rajib Nath and Stan Tomov, will be
part of the up-coming MAGMA 0.3 library release and will be included in
CUBLAS 3.2 as well.
となっている。ソースコードも3条項BSDで。すごいなぁ。本当にすごいなあ。
This is a MAGMA 0.3 DGEMM Routine for Fermi GPUs.
In this version matrix sizes have to be divisible by 64.
Results for C2050
[peak is 515 GFlop/s, achieved up to 300 GFlop/s, i.e.,58% of peak]
N magmablas0.3 GFLops/s cudablas-3.1 GFlops/s error
==========================================================================
512 235.67643 92.18251 0.000000e+00
1088 286.17120 172.57316 0.000000e+00
1664 291.13124 174.15823 0.000000e+00
2240 295.47884 175.34066 0.000000e+00
2816 296.56132 175.25919 0.000000e+00
3392 297.93243 175.52666 0.000000e+00
3968 298.42470 175.66484 0.000000e+00
4544 298.72286 175.39565 0.000000e+00
5120 298.96818 175.67765 0.000000e+00
5696 299.35310 175.61312 0.000000e+00
こっちも焦る。Mittelmann先生からまた催促があったし...
> In this version matrix sizes have to be divisible by 64.
じゃないときはcuBLASを呼んでいる。
これはカーネルのみ性能であって、行列のGPUへの転送はふくまない。
2010-08-04
The MAGMA BLAS SGEMM and DGEMM sources for Fermi GPUs are now released.
These improved GEMMs, developed by Rajib Nath and Stan Tomov, will be
part of the up-coming MAGMA 0.3 library release and will be included in
CUBLAS 3.2 as well.
となっている。ソースコードも3条項BSDで。すごいなぁ。本当にすごいなあ。
This is a MAGMA 0.3 DGEMM Routine for Fermi GPUs.
In this version matrix sizes have to be divisible by 64.
Results for C2050
[peak is 515 GFlop/s, achieved up to 300 GFlop/s, i.e.,58% of peak]
N magmablas0.3 GFLops/s cudablas-3.1 GFlops/s error
==========================================================================
512 235.67643 92.18251 0.000000e+00
1088 286.17120 172.57316 0.000000e+00
1664 291.13124 174.15823 0.000000e+00
2240 295.47884 175.34066 0.000000e+00
2816 296.56132 175.25919 0.000000e+00
3392 297.93243 175.52666 0.000000e+00
3968 298.42470 175.66484 0.000000e+00
4544 298.72286 175.39565 0.000000e+00
5120 298.96818 175.67765 0.000000e+00
5696 299.35310 175.61312 0.000000e+00
こっちも焦る。Mittelmann先生からまた催促があったし...
> In this version matrix sizes have to be divisible by 64.
じゃないときはcuBLASを呼んでいる。
これはカーネルのみ性能であって、行列のGPUへの転送はふくまない。
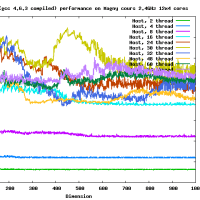

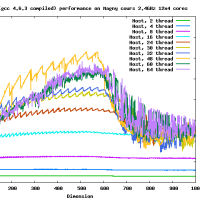
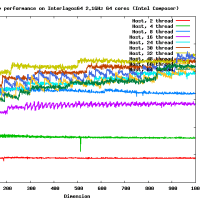
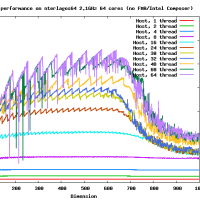
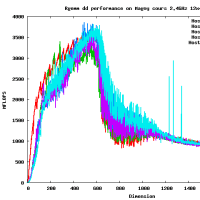

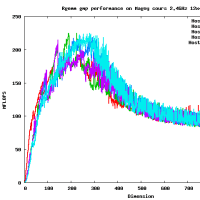
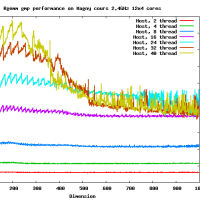
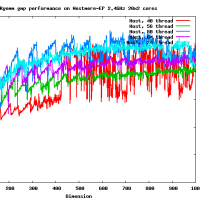
高速なカーネルを作るのはそれほど難しくはないよ。