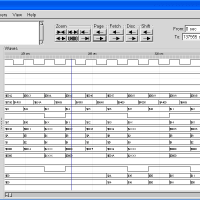
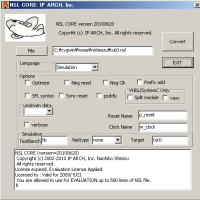
一応、自分で用意している4つのテストケースは完動したので、完成としておこう。
最終的に、LD/ST専用にインオーダーのリザベーションステーションを作ったり、各種事象の同時発生対応コードを入れたりと、コード量はずいぶん増えて、現在、794行。
かろうじて800行は切った。まぁ、これでも、Out of Order実行CPUとしては、極小の部類だと思う。
主要諸元は以下の通り
最後まで悩ませたのが、SORTの例題で、実行結果のメモリがおかしいというもの。これは、メモリまでアウトオブオーダーにしていたので、STの後にLDで同じアドレスを読み出すケースで、LDをSTよりも先に実行してしまい、値を誤っていた。LD/STのリザベーションステーションを1エントリにするという方法もあるけれど、一応、インオーダー2エントリとして対処。メモリをアウトオブオーダーに実行すると、性能上は非常に優れているのだけれど、演算結果がおかしいのでは意味がないね。
インオーダーCPUは、順番に実行するので、リソースの競合はあらかじめ避けるように設計するのだけれど、アウトオブオーダーの場合には各ユニットが勝手に実行するので、同時発生の競合や、読み出し・書き込み同時の場合に、スルーでデータを渡すのか、待たせるのかなど、個別に詳細な検討が必要だ。
それに、何より、結果がおかしい時のデバッグが難しい。
お勧めは、命令リタイヤはインオーダーだし、発行もインオーダーなので、まずは、リタイヤを追いかけて、命令結果を見て、その後、リタイヤアドレスから命令発行場所を探して、解析を行うというもの。
命令発行と命令リタイヤが1命令ずつなので、アウトオブオーダーにしたからといって、大きく性能が向上するわけではないけれど、原理を理解するための教育目的CPUなので、その目的には十分な効果があると思う。
最終的に、LD/ST専用にインオーダーのリザベーションステーションを作ったり、各種事象の同時発生対応コードを入れたりと、コード量はずいぶん増えて、現在、794行。
かろうじて800行は切った。まぁ、これでも、Out of Order実行CPUとしては、極小の部類だと思う。
主要諸元は以下の通り
| CPU アーキテクチャ | SN/X |
| リザベーションステーション | ALU(2エントリ) |
| リザベーションステーション | BRANCH(2エントリ) |
| リザベーションステーション | LD/ST(2エントリ:インオーダー) |
| リオーダーバッファ・リネームレジスタ | 8エントリ |
| ストアバッファ | 2エントリ |
| コード行数 | 794行 |
| 開発期間 | 実働4日 |
| 使用言語 | NSL |
最後まで悩ませたのが、SORTの例題で、実行結果のメモリがおかしいというもの。これは、メモリまでアウトオブオーダーにしていたので、STの後にLDで同じアドレスを読み出すケースで、LDをSTよりも先に実行してしまい、値を誤っていた。LD/STのリザベーションステーションを1エントリにするという方法もあるけれど、一応、インオーダー2エントリとして対処。メモリをアウトオブオーダーに実行すると、性能上は非常に優れているのだけれど、演算結果がおかしいのでは意味がないね。
インオーダーCPUは、順番に実行するので、リソースの競合はあらかじめ避けるように設計するのだけれど、アウトオブオーダーの場合には各ユニットが勝手に実行するので、同時発生の競合や、読み出し・書き込み同時の場合に、スルーでデータを渡すのか、待たせるのかなど、個別に詳細な検討が必要だ。
それに、何より、結果がおかしい時のデバッグが難しい。
お勧めは、命令リタイヤはインオーダーだし、発行もインオーダーなので、まずは、リタイヤを追いかけて、命令結果を見て、その後、リタイヤアドレスから命令発行場所を探して、解析を行うというもの。
命令発行と命令リタイヤが1命令ずつなので、アウトオブオーダーにしたからといって、大きく性能が向上するわけではないけれど、原理を理解するための教育目的CPUなので、その目的には十分な効果があると思う。