








リリースアナウンス
これはNVIDIA C2050で行列-行列積を高速に行うルーチンで、BLAS, LAPACKのスタイルを踏襲したMPACKのルーチンの一つRgemmを加速したものです。
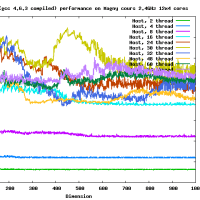
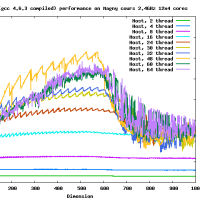
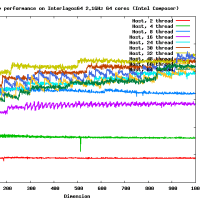
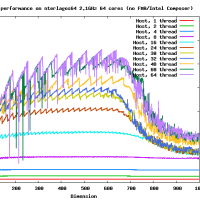
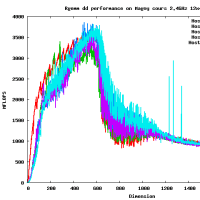
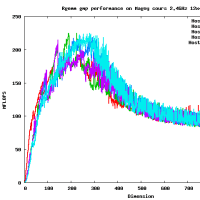
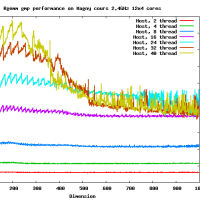
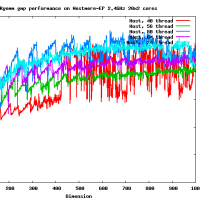
だいたい、16GFlopsくらいでて(CPU-GPU転送も含め、精度を落とすと26GFlops程度までさらに高速化する)、CPUの参照実装とくらべると、150倍程度高速です。これ以上、劇的に高速化するのは、アルゴリズムを変えない限り難しいでしょう。チューニングされた倍精度行列-行列積はCore i7 920で42GFlopsなので、なんと、その半分程度の性能が出ます。
プログラムは高雄保嘉と中田真秀で行いました。
これはベンチマークとなっていて、
$ tar xvfz Rgemm_C2050_20111026.tar.gz
$ cd Rgemm_C2050
$ make
...
とするとCSVファイルにベンチマーク結果がかえってきます。
他の研究用の実装とは違い、応用を主眼としているので、Rgemmの仕様にそったものとなり、さらに他のプログラムなどに埋め込み、信頼性などを確かめています。応用については近々発表する予定です。
また、
これを礎にしてさらに様々な線形代数演算ルーチンが加速できます。
これはNVIDIA C2050で行列-行列積を高速に行うルーチンで、BLAS, LAPACKのスタイルを踏襲したMPACKのルーチンの一つRgemmを加速したものです。
だいたい、16GFlopsくらいでて(CPU-GPU転送も含め、精度を落とすと26GFlops程度までさらに高速化する)、CPUの参照実装とくらべると、150倍程度高速です。これ以上、劇的に高速化するのは、アルゴリズムを変えない限り難しいでしょう。チューニングされた倍精度行列-行列積はCore i7 920で42GFlopsなので、なんと、その半分程度の性能が出ます。
プログラムは高雄保嘉と中田真秀で行いました。
これはベンチマークとなっていて、
$ tar xvfz Rgemm_C2050_20111026.tar.gz
$ cd Rgemm_C2050
$ make
...
とするとCSVファイルにベンチマーク結果がかえってきます。
他の研究用の実装とは違い、応用を主眼としているので、Rgemmの仕様にそったものとなり、さらに他のプログラムなどに埋め込み、信頼性などを確かめています。応用については近々発表する予定です。
また、
これを礎にしてさらに様々な線形代数演算ルーチンが加速できます。


※コメント投稿者のブログIDはブログ作成者のみに通知されます