








藤澤先生から
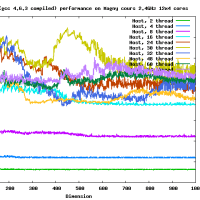
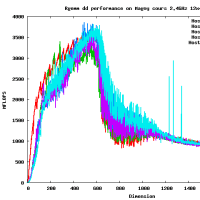
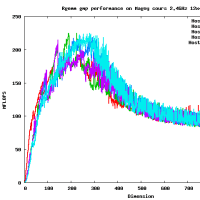
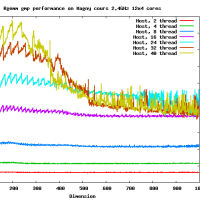
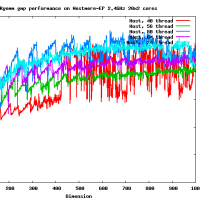
Opteron Magny-Cours 2.4GHz 12x4コアのマシンをアクセスさせてもらった。そこで、Rgemm __float128 のベンチマークをとってみた。
これはIEEE 754 2008で定義されているbinary128のgccでの実装である。
* マシン:AMD Opteron Magny-Cours 2.4GHz 12x4 = 48 cores
* MPACK 0.7.0 (SVN)
* gcc 4.6.3
* reference implementation + openmp
* Rgemm (dgemm like routine), すべて正方行列、初期値はランダムな行列。
* スレッド数は1,2,4,8,16,...など変えた

300MFlopsとddと比較するとほぼ同じ精度なのに10倍も遅い!!
行列のサイズが大きくなると、おそくなるというのは今回は見られなかった。
きっとメモリアクセスはボトルネックにならない程度に演算が遅いのであろうと思われる。
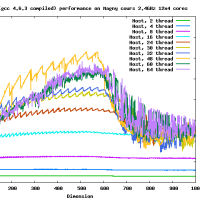
Opteron Magny-Cours 2.4GHz 12x4コアのマシンをアクセスさせてもらった。そこで、Rgemm __float128 のベンチマークをとってみた。
これはIEEE 754 2008で定義されているbinary128のgccでの実装である。
* マシン:AMD Opteron Magny-Cours 2.4GHz 12x4 = 48 cores
* MPACK 0.7.0 (SVN)
* gcc 4.6.3
* reference implementation + openmp
* Rgemm (dgemm like routine), すべて正方行列、初期値はランダムな行列。
* スレッド数は1,2,4,8,16,...など変えた
300MFlopsとddと比較するとほぼ同じ精度なのに10倍も遅い!!
行列のサイズが大きくなると、おそくなるというのは今回は見られなかった。
きっとメモリアクセスはボトルネックにならない程度に演算が遅いのであろうと思われる。


※コメント投稿者のブログIDはブログ作成者のみに通知されます