色々試したあげく、思ったことは、
高精度計算 on many core CPUはOpenMP程度の高速化では難があるということだ。
最初思うことは、GPUでの高速化だが、高精度計算は(double-doubleのようなアプローチをのぞき)、分岐が多いため
GPUでの高速化には向かない。従って昨今マルチコア化けが進んできたCPUで行うというふうに思うのが常識的な
判断であろう。またメモリのアクセススピードが相対的に低下、または、今後このままの技術延長上には高速化の
余地はあまりない、ということでbytes/flopが下がってきたわけで、高精度計算は相対的に高速化されるはず
と見込んでやっているのであるが(正確にはモチベーションのごく小さい部分なのだが他の人にはわかってもらいやすい
モチベーションである)。
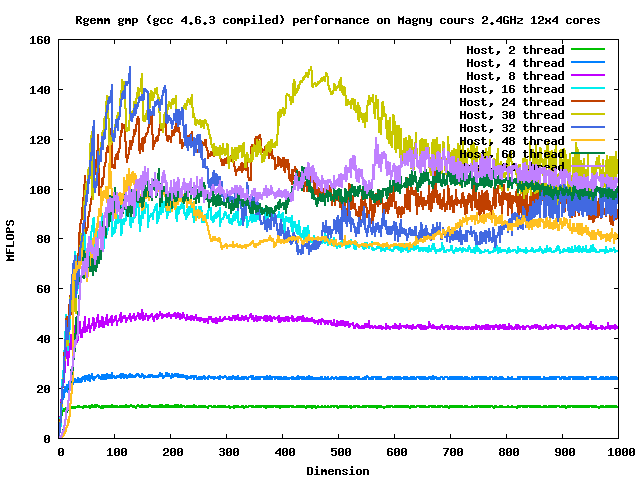
また、AMDの石では行列のサイズが大きくなるとCPUまたはスレッドの数を増やしてもパフォーマンスが
増えない、むしろ悪くなることもある、ということである。
さらに、__float128はgccのIEEE 754 2008のbinary128をソフトウェアで実装したものについては
double-doubleとはほぼ同精度であるにも関わらず10倍程度遅かった。
GMPのパフォーマンスは石を選ぶようで、必ずしも新しいのが良いという訳ではなかった。
IntelのコンパイラはAMDの石でも常に良い性能を示した。
Intelの石は比較的素直な性能を示したが、パフォーマンスには不連続なところが見られた。急に
パフォーマンスが良くなる行列のサイズがあった。
SIMDはスレッド数をあげれば自動的に使ってくれるかと思ったがそうではないということがわかった。
AMDはアーキテクチャ上NUMAを意識しないとパフォーマンスが出ないことがわかった。OpenMP程度でも
これを強く意識しないとダメということだ。
高精度計算 on many core CPUはOpenMP程度の高速化では難があるということだ。
最初思うことは、GPUでの高速化だが、高精度計算は(double-doubleのようなアプローチをのぞき)、分岐が多いため
GPUでの高速化には向かない。従って昨今マルチコア化けが進んできたCPUで行うというふうに思うのが常識的な
判断であろう。またメモリのアクセススピードが相対的に低下、または、今後このままの技術延長上には高速化の
余地はあまりない、ということでbytes/flopが下がってきたわけで、高精度計算は相対的に高速化されるはず
と見込んでやっているのであるが(正確にはモチベーションのごく小さい部分なのだが他の人にはわかってもらいやすい
モチベーションである)。
また、AMDの石では行列のサイズが大きくなるとCPUまたはスレッドの数を増やしてもパフォーマンスが
増えない、むしろ悪くなることもある、ということである。
さらに、__float128はgccのIEEE 754 2008のbinary128をソフトウェアで実装したものについては
double-doubleとはほぼ同精度であるにも関わらず10倍程度遅かった。
GMPのパフォーマンスは石を選ぶようで、必ずしも新しいのが良いという訳ではなかった。
IntelのコンパイラはAMDの石でも常に良い性能を示した。
Intelの石は比較的素直な性能を示したが、パフォーマンスには不連続なところが見られた。急に
パフォーマンスが良くなる行列のサイズがあった。
SIMDはスレッド数をあげれば自動的に使ってくれるかと思ったがそうではないということがわかった。
AMDはアーキテクチャ上NUMAを意識しないとパフォーマンスが出ないことがわかった。OpenMP程度でも
これを強く意識しないとダメということだ。