








レフェリーで CUDA 関係の論文が来たので、CUDA をインストールして使ってみることにした。手元にあった GeForce 8xxx 系は 8600GTS だけなので、GeForce 8800GTS 512MB を購入した。現在は Fedora 7 が正式サポートだが、手元に Fedora 7 のマシンが無いので、Fedora 8 で試してみた。
1: CUDA のダウンロード (Fedora 8 x86_64 の場合)
CUDA Toolkit version 1.1 for Fedora 7
CUDA SDK version 1.1 for Linux
NVIDIA Driver for Linux with CUDA Support (169.09)
2: NVIDIA ドライバのインストール
yum install kernel-devel
yum install freeglut freeglut-devel
init 3
sh NVIDIA-Linux-x86_64-169.09-pkg2.run
init 5
3: CUDA のインストール
sh NVIDIA_CUDA_Toolkit_1.1_Fedora7_x86_64.run
sh NVIDIA_CUDA_SDK_1.1_Linux.run
/etc/ld.so.conf に /usr/local/cuda/lib を追加
ldconfig
PATH に /usr/local/cuda/bin を追加
4: サンプルファイルの make
cd NVIDIA_CUDA_SDK
make
ただし、gcc 4.2.x ではコンパイルできない。gcc 4.1.x を推奨
NVIDIA_CUDA_SDK/bin/linux/release 以下に様々なバイナリが出来ている
この中の bandwidthTest を用いるとメインメモリ ←→ ビデオカードのメモリ間の
バンド幅の測定が出来る。ビデオカード内は 50GB/s強になる。
./bandwidthTest
Quick Mode
Host to Device Bandwidth for Pageable memory
.
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 1520.1
Quick Mode
Device to Host Bandwidth for Pageable memory
.
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 1227.4
Quick Mode
Device to Device Bandwidth
.
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 50910.8
&&&& Test PASSED
1: CUDA のダウンロード (Fedora 8 x86_64 の場合)
CUDA Toolkit version 1.1 for Fedora 7
CUDA SDK version 1.1 for Linux
NVIDIA Driver for Linux with CUDA Support (169.09)
2: NVIDIA ドライバのインストール
yum install kernel-devel
yum install freeglut freeglut-devel
init 3
sh NVIDIA-Linux-x86_64-169.09-pkg2.run
init 5
3: CUDA のインストール
sh NVIDIA_CUDA_Toolkit_1.1_Fedora7_x86_64.run
sh NVIDIA_CUDA_SDK_1.1_Linux.run
/etc/ld.so.conf に /usr/local/cuda/lib を追加
ldconfig
PATH に /usr/local/cuda/bin を追加
4: サンプルファイルの make
cd NVIDIA_CUDA_SDK
make
ただし、gcc 4.2.x ではコンパイルできない。gcc 4.1.x を推奨
NVIDIA_CUDA_SDK/bin/linux/release 以下に様々なバイナリが出来ている
この中の bandwidthTest を用いるとメインメモリ ←→ ビデオカードのメモリ間の
バンド幅の測定が出来る。ビデオカード内は 50GB/s強になる。
./bandwidthTest
Quick Mode
Host to Device Bandwidth for Pageable memory
.
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 1520.1
Quick Mode
Device to Host Bandwidth for Pageable memory
.
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 1227.4
Quick Mode
Device to Device Bandwidth
.
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 50910.8
&&&& Test PASSED



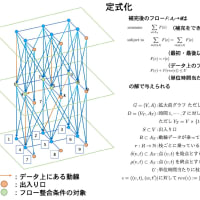


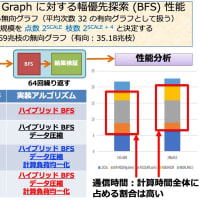
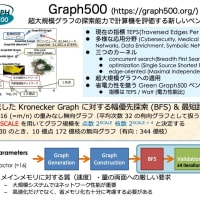

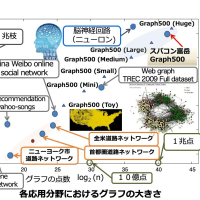





どうしても GPGPU で計算がしたい、ということであれば Out-of-Core のモデルを使うとうまくいくと思います。
それよりも、多倍長整数計算とか倍々精度浮動小数のエミュレーションをやらせたら面白いと思うのですが。
無限大の演算性能を持つカード上で 4倍精度のエミュレーションを行った場合の最大性能は 30GFlops 程度と予想できます。Intel Core2 だと 20MFlops 程度ですので、それなりに高速化できます(実際には GPGPU での整数乗算性能で律速されるとは思いますが)。ただし、m, k を大きくしなければならない制限がありますので、SDPA に使えるかどうかは未知数です。
GPGPU 上での行列積の上限値 : 120GFlops(単精度), 60GFlops (倍精度), 30 GFlops (4倍精度)
AXPY の上限値 : 180 MFlops (単精度), 90MFlops (倍精度), 45 MFlops (4倍精度)
というわけで、カード上に大容量バッファを持っていないタイプのアクセラレータカードでは行列積の性能が出ることはありません。