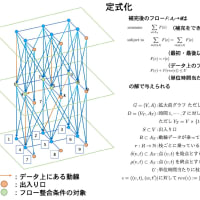
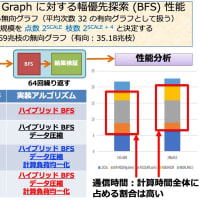
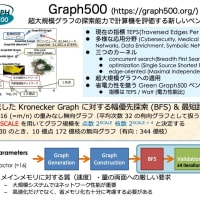
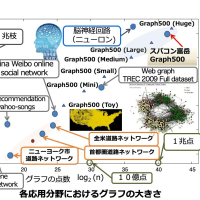
9,10日と今後の開発計画について議論を行った(非常に中身の濃い議論だった)。高速化等の改善のためには、まず現在のプログラムについて徹底した調査が必要になる。どのような問題を入力したときに、どの部分がボトルネックになるのかについても、いろいろな方法で直接的、間接的に知ることができる。今までのアルゴリズム開発というのは、計算量(CPU 上での演算量に近い)と記憶容量に重点を置いてきていたので、CPU とメモリ間のデータの移動量については考慮されることは少なかった。また、データを参照する範囲、局所性のような概念も取り入れる必要がある。
例えば現在、開発を行いながら同時に公開も行っている最短路問題に対するダイクストラ法を実装したプログラムでは、最小ポテンシャルの点を高速に見つけるために、ヒープやバケットを利用している。ヒープは最小点を見つけるのは大変高速だが、データの更新に非常にデータ参照と書き込みのコストがかかる。というわけで、データ参照を局所的に収めて書き込みを減らせば、データをパッキングして、主要データを L1, L2 キャッシュに格納することが可能になる。当面はこの辺の可能性を考えていくことになる。
例えば現在、開発を行いながら同時に公開も行っている最短路問題に対するダイクストラ法を実装したプログラムでは、最小ポテンシャルの点を高速に見つけるために、ヒープやバケットを利用している。ヒープは最小点を見つけるのは大変高速だが、データの更新に非常にデータ参照と書き込みのコストがかかる。というわけで、データ参照を局所的に収めて書き込みを減らせば、データをパッキングして、主要データを L1, L2 キャッシュに格納することが可能になる。当面はこの辺の可能性を考えていくことになる。