








kernel/genericの下は使われてなさそうだが参考になるプログラムが多々ある。
これは、行列をキャッシュへ載せるためのプログラムだ。
C:=alpha AB + beta Cを行うわけだ。
レジスタ、キャッシュは使いきらず、半分程度にするのが肝要とのこと。
* kernel/generic/gemm_ncopy_4.c: 4x4の行列(訂正:4x4単位での行列??)のコピー。並べ替えあり。a->bで転置を取ってる。
* ブロックサイズ(レジスタ載せる)のはレジスタ総数の半分。SSE2ならば32/2=16レジスタ。
* Cは直接更新。A, Bはコピーする。L2, L3に載せる程度。
* Cでも高速なプログラムは可能。キャッシュにデータを載せるには、実際に書き込むこと。
これは、行列をキャッシュへ載せるためのプログラムだ。
C:=alpha AB + beta Cを行うわけだ。
レジスタ、キャッシュは使いきらず、半分程度にするのが肝要とのこと。
* kernel/generic/gemm_ncopy_4.c: 4x4の行列(訂正:4x4単位での行列??)のコピー。並べ替えあり。a->bで転置を取ってる。
* ブロックサイズ(レジスタ載せる)のはレジスタ総数の半分。SSE2ならば32/2=16レジスタ。
* Cは直接更新。A, Bはコピーする。L2, L3に載せる程度。
* Cでも高速なプログラムは可能。キャッシュにデータを載せるには、実際に書き込むこと。
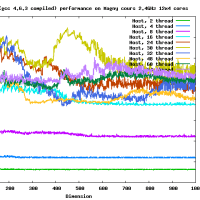

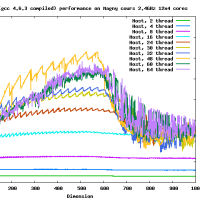
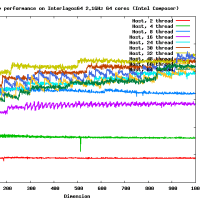
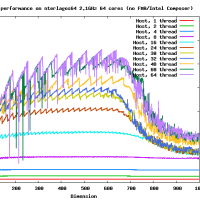
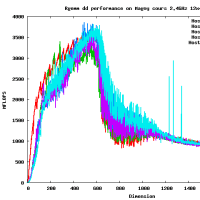

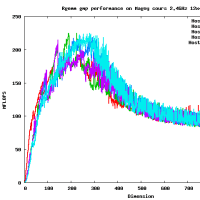
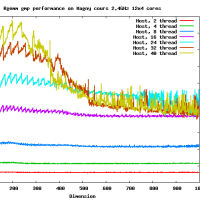
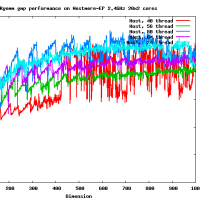
違うよ。4x? もしくは ?x4 の形式で使用する。4x8 の場合には gemm_ncopy_8.c との組み合わせになる。
do{
ctemp1 = *(a_offset1 + 0);
ctemp2 = *(a_offset1 + 1);
ctemp3 = *(a_offset1 + 2);
ctemp4 = *(a_offset1 + 3);
ctemp5 = *(a_offset2 + 0);
ctemp6 = *(a_offset2 + 1);
ctemp7 = *(a_offset2 + 2);
ctemp8 = *(a_offset2 + 3);
ctemp9 = *(a_offset3 + 0);
ctemp10 = *(a_offset3 + 1);
ctemp11 = *(a_offset3 + 2);
ctemp12 = *(a_offset3 + 3);
ctemp13 = *(a_offset4 + 0);
ctemp14 = *(a_offset4 + 1);
ctemp15 = *(a_offset4 + 2);
ctemp16 = *(a_offset4 + 3);
4x?もしくは?x4ですね。
4x?で、?は四の倍数ずつ最後余ったらその処理、ですね。大まかな処理単位は4x4。
私はここを理解してないことがわかった。一つ進んだ!
> gemm_ncopy_8.c との組み合わせになる。
dgemmだと、4x8 8xn となるからgemm_ncopy_8と組み合わさるのだ。