








索引作成
2011-02-01 | 雑談
個人で仕事をしていると、休み前に仕事が飛び込んでくることがよくあります。それは土・日、祭日、連休、盆・正月を問いません。今年の正月休みも例外ではなく、駆け込みで何本かの仕事が入ってきました。新規の仕事だけではなく、進行中の仕事の修正などもその中には含まれます。
立て続けに入ってきたものの中に、2ヶ月前から進行中の本の索引を作る仕事がありました。依頼された段階で索引を作ることはわかっていたので、そのこと自体に問題はないのですが、困ったのは索引の作成方法です。親切なところだと、項目とノンブル(ページ)の入ったエクセルのデータが用意されていて、それをもとに索引を作るケースがまず一つあります。もう一つが、項目のデータだけあってノンブルをこちらで拾っていくケース。この場合は最初の例よりたしかに手間はかかりますが、項目のデータを用意してくれるだけまだいいといえます。今回はそのどちらのケースでもなく、編集者がゲラに書き込んだアンダーラインをもとに索引を作らなければならないというものでした。
数日後には帰省の日が迫っているというのに(まあ実際には予定通り帰省できなかったわけですが)、一つ一つ語句を拾っていかなければならないのかと考えると溜息が出ます。とりあえず索引は後回しにし、後日別の仕事が一段落したところで原稿のPDFを開いてみました。
最初のページを表示したところで、思わず「おいおい」と声を上げそうになりました。というのも、初っ端から想定外の箇所があったからです。次いで2ページ目、3ページ目と目を通していくと、想定外の箇所は原稿の書き間違いではなく、意図したものであることがはっきりしました。おまけに抜き出さなければならない語句もやけに多く、中には表内の語句すべてにアンダーラインが入っているページもあります。総ページ数が100数十ページと少ないのでまだいいようなものの、これでは語句を拾い出すだけで何時間かかるかわかったものではありません。
もともと最初の打ち合わせで索引を作るという話があったときから、InDesignの索引機能を使用する考えはありませんでした。InDesignの標準機能では語句を登録する際にいちいちふりがなを入力しなければならず、一つ一つ馬鹿丁寧に登録していたのでは日が暮れてしまうからです。そこで索引語句を手作業で抜き出さなければならないということがわかった時点で、文字スタイルの適用された語句をノンブル入りで一気に抽出するスクリプト(注1)を利用する腹積もりでいました。
ところが原稿を見たときに、このスクリプトを実行する上で一つ困ったこと、先ほど述べた想定外のことがあるのに気づきました。それは何かというと、一続きの語句を2つの索引項目に分けて抽出しなければならないものが混じっていたことです。わかりづらいので一つ例を挙げてみましょう。たとえば、
ABCDEF
という語句があるとします。これがABという語句とEFという語句を索引項目とする場合は何の問題もないのですが、ABCという語句とDEFという語句を索引として抜き出さなければならないとなると、困ったことになります。何故なら、ABCとDEFと2つに分けて文字スタイルを適用しても、2つの語句の間に区切りがないので結局ABCDEFに文字スタイルを適用したのと同じ結果になるからです。つまりABCとDEFとしては抽出されず、ABCDEFという語句が抽出されてしまうのです。この例ではABCとDEFの間に区切りの制御記号を入れれば何とか問題を回避できるかもしれませんが、ABCDとCDEFに分けて抽出しなければならない場合は完全にお手上げです。中にはABCとABEFに分けて抜き出すという理解に苦しむものもありました。
こうなると文字スタイルから索引項目を抽出するスクリプトは使えず、別の方法を考えなければなりません。焦っても仕方がないのでその日の残りは別の仕事に当てることにし、夜寝る前にゆっくりと対策を考えることにしました。
厄介なことになったと思いつつ、ある程度落ち着いていられたのは、InDesignの標準機能で一つ一つ地道に索引に登録していくという最後の手段が残されていたからです。が、できればそういう事態は避けたいのはいうまでもありません。
どんな手段を講じるにしろ、索引語句を範囲指定する作業を省くことはできないという結論に行き着きます。では、範囲指定して選択した語句をダイレクトに抜き出すにはどうすればいいか、そう考え始めると居ても立ってもいられず、夜中にもかかわらず布団から起き上がって一度切ったMacの電源を入れ直しました。
考え方としては、選択した文字列をファイルに書き出すか、コピーしてクリップボードに格納された文字列をファイルに書き出すかです。真っ先に思い浮かんだのはクリップボードの内容を書き出すことだったので、クリップボードをキーワードに検索してみました。すると、目的のものが予想外にあっさりと見つかりました。
それはAdobe Forumsでのやりとりの中で、質問者(natokoさん)がJavaScriptでクリップボードのデータを取得するにはどうしたらいいかと問うているのに対し、Ten Aさんが提示した以下のような回答です(スクリプト部分のみ抜粋)。
tmpFrm = app.activeWindow.activeSpread.textFrames.add(); //仮フレーム生成
app.select(tmpFrm.insertionPoints[0]); //仮フレームにiビーム(インサーションポイント)を設定する。
//クリップボードデータを正常に読み込めない場合のためのエラー処理
try{
app.paste();
}catch(e){
alert("クリップボードの内容を取り込めませんでした。");
}
str = tmpFrm.parentStory.contents; //ペーストしたテキストデータを読み込む
tmpFrm.remove(); //仮フレームの削除
このうち最後の2行はテキストを抜き出すという今回の目的には関係がないので削除し、また1行目のtmpFrm = app.activeWindow.activeSpread.textFrames.add();では抽出されたテキストが各スプレッドに分散してしまい、あとで一括して別のドキュメントにコピーペーストするのに不都合なので、次のように書き改めました。
tmpFrm = app.documents[0].textFrames.add(); //仮フレーム生成
これでスクリプトを実行すると、ドキュメント1ページ目の原点座標に10pt角のテキストフレームが作られ、その中にコピーした文字列が抜き出されます。10pt角のテキストフレームでは当然テキストがオーバーフローした状態になりますが、この場合の目的はあくまでテキストを抽出することなので何ら問題はありません。これを10回繰り返せば同じ座標位置に10個のテキストフレームが積み重なるという寸法です。
見通しが立ったことで多少は気も楽なり、明日の段取りを頭の中でイメージしながら眠りに就きました。
翌日目が覚めると早速作業を開始し、語句を選択してコピー、次いでスクリプトの実行という手順でどんどんテキストを抜き出していきました。つまり通常の作業では語句を選択してコピー、1ページ目に戻ってペースト、また元のページに戻って語句を探し選択、という手順を踏むところを、ページ間を移動することなく3つのアクションで済ませられるわけです。
1章の途中までそうして作業していたのですが、「待てよ、コピーもスクリプトに組み込めばもう1アクション減らせるじゃないか」と遅蒔きながら気づきました。そこで、スクリプトの冒頭に次の1行を書き加えました。
app.copy();
これで語句を選択した状態でスクリプトを実行するだけで、テキストが抜き出されます。わずか1アクションの違いとはいえ、何百回と同じ操作を繰り返すことを考えるとその差は十分大きいといえます。
この方法の欠点は、抜き出し終わった語句に目印がつくわけではないので、どこまで作業が終わったかが確認できないことです。途中うっかり席を立とうものなら、どこまで作業が終わったかを忘れてしまい、1ページに戻って見直さなければならないということにもなりかねません。しかしそれは注意を払っていれば防げることですし、短時間で作業を終わらせられるというメリットを打ち消すほどのものではありません。改良の余地はあるにしろ、今後同様の案件があった場合にも使える方法だと思います。
1章の作業が終わったところで、テストも兼ねて抜き出した語句をテキストファイルに纏めることにしました。この時点では、抜き出されたテキストは下図のような状態になっています。
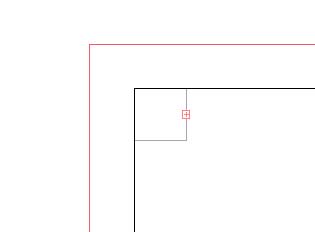
画面上はオーバーフローした1つのテキストフレームしか見えませんが、実際は何十というテキストフレームが重なった状態になっています。これをすべて選んでコピーし、新規ドキュメントを作成して適当な位置にペーストします。最後にAppleScriptで下記のスクリプトを実行します。
tell document 1 of application "Adobe InDesign CS3" to contents of stories as Unicode text(注2)
すると抜き出した語句がスクリプトエディタにカンマ区切りですべて書き出されます。それをテキストエディタにコピーペーストし、カンマを改行に置換して完成です。
見たところ特に問題はないよいうなので、同様の作業を2章以降についても繰り返します。ところがここで問題が一つ発生しました。本文中にはところどころにIllustratorで作成した図が配置してあるのですが、その図中の語句まで索引に含めなければならないものが出てきたのです。それを見た瞬間「えーっ、どうするんだよ」という声が思わず出てしまいました。面倒くさいので無視しようかとも思いましたが、さすがにそういうわけにもいきません。仕方がないので図中のテキストをInDesignの該当ページに一つ一つ貼り付けることにしました。
IllustratorのテキストをそのままInDesignにペーストすると、文字情報が消えてグラフィック化されてしまいます。かといってテキストエディタ経由でコピーペーストしていたのでは効率が悪すぎます。ここでもスクリプト(注3)にひと働きしてもらうことにしました。
図が何ページにもわたって連続するところにはうんざりしましたが、無事最後の章まで語句の抽出作業が終わりました。InDesignで一語一語索引に登録していったのでは、一日で作業が終えられたかどうかもわかりません。その意味では倍以上早く作業を終えられたのではないでしょうか。
次に出来上がった語句の一覧にノンブルを付加していくわけですが、ここでも当然スクリプト(注4)の出番です。
このスクリプトを実行すると、語句の一覧と合致する本文中のテキストがノンブルと一緒に抽出され、テキストファイルに書き出されます。抜き出した語句の数が全部で1000近くあったのでそれなりに時間はかかりましたが、1章あたりおおよそ3分前後で処理が終わりました。
章ごとに書き出されたテキストファイルをExcelで一つにまとめ、ふりがなを付ける作業に移ります。が、スクロールしてデータをざっと見渡しているうちに、おかしなことに気づきました。ところどころノンブルの列が空白になっているところがあるのです。語句は本文中から抜き出したものですから、本来ノンブルが空白になるはずはありません。一体何が起きたのかとしばしデータの前で考え込みました。
ノンブルが空白のところは一箇所や二箇所ではなく、相当な数があります。本文と照合してみたところ、ノンブルが抜けているのは表内の語句であることが判明しました。なんだ、そうだったのかと安堵すると同時に、困ったことになったと思いました。この期に及んでスクリプトを書き直している余裕はなく、かといって手作業でノンブルを入れていったのでは何時間かかるかわからなかったからです。それに折角ここまで手作業に頼らずに来たのに、今更手作業に戻るのも業腹です。
頭を悩ませていたのはわずかな時間で、すぐに対策を思いつきました。
表をテキストに変換してしまえばいいのです。安易といえば安易な方法ですが、これ以上の名案はありそうにありません。
行のずれに注意しながらすべての章の表をテキストに変換し、もう一度スクリプトを実行し直します。出来上がったテキストファイルをExcelに取り込み、各章のデータを合体して確認すると、今度はほぼ問題なさそうでした。
ほぼ、という留保をつけたのは、やはりいくつかノンブルが空白のところが残ったからです。どこが空白だったかというと、最初に述べたABEFのように、間の数語を飛ばした語句のところです。もともと本文にはABEFという語句は存在しないのですから、ノンブルが付かないのも当然です。仕方がないのでこれらに関しては手入力することにしました。
さて、残る面倒な作業はふりがなを振ることです。これが終われば作業は終わったも同然といっても過言ではありません。
ふりがなを振るにはPHONTIC関数を使えばいいという話をどこかで見たか聞いたかしたことがあるので、これもわけなくできるだろうと楽観していました。まず適当なセルにカーソルを置き、関数を入力します。とりあえず1つ範囲を指定してリターンキーを押すと、ふりがなが表示される……はずが表示されません。なぜか元の語句がそのまま表示されるだけです。何かの間違いだろ、と思いつつ二度、三度とやり直しても、結果は変わりません。ここで他に何も策がなければあわてふためくところですが、もう一つ別の策も用意してあったので潔く諦めてそちらの方法に切り替えることにしました。
あとで調べたところによると、PHONTIC関数はExcelで入力された情報をもとにふりがなを作成するのだそうです。今回のデータはテキストエディタからコピーペーストしたものですから、ふりがなが振られないのは当然の結果でした。ためしにExcelで直接入力した文字にPHONTIC関数でふりがなを振ってみたところ、たしかにちゃんと表示されます。こういうことは実際に経験してみなければわかりません。
Excelでのふりがな付けの代わりに利用したのが、漢字仮名変換サイトでした。翻訳サイトの漢字仮名変換版といえばわかりやすいでしょうか。どれくらいの変換精度なのか多少の不安があったので最初はPHONTIC関数を利用することを考えたのですが、実際に試してみると、まあ使えなくはないレベルにまでは変換してくれました。専門用語がかなり含まれていた点を考慮すれば、仕方のない結果といえます。
変換されたテキストを再びExcelに戻し、上から順にチェックしていきます。おかしなところは手作業で直し、明らかな誤変換を潰していきました。
これで材料がすべて揃ったわけですが、今回は編集者の校正用に一覧表の形で出してくれと依頼されていました。どんな形式で出すにせよ、材料さえ揃っていればあとはどうにでも料理できるはずです。やれやれやっと終わりそうだと思いながら渡された出力サンプルを見た僕は、またしても声を上げそうになりました。
普通索引といえば語句のあとにノンブルがつづき、それが五十音順に並んでいるものを想像します。が、渡された出力サンプルはまずノンブルがあり、そのあとに語句と読みが入るという形になっていたからです(下図参照)。こんな形のものはまったく想像していなかったので、何かの間違いじゃないかと何度も見直しました。
001 AAA ○○○
001 BBB ○○○
002 CCC ○○○
002 DDD ○○○
・
・
・
Excelのデータをどう加工すればこんな形にできるのか、頭の中でいろいろシミュレーションしてみても、すぐに行き詰まってしまいます。見込みのないことに時間を費やすよりもここは依頼先に聞くのが得策だと考え、電話で問い合わせることにしました。
*
さて、本当はこの後の顛末も書くつもりだったのですが(実際最後まで書いたのですが)、話が本題から外れますし、取引先のことをあれこれ書くのもどうかと思いますので割愛します。(ちなみに上記の件は、ExcelではなくInDesignのプラグインで処理していたという落ちでした)。
これまで索引といえばデータが支給される場合がほとんどだったので、今回のように一から作成していくのは初めての経験でした。作業が終わってからああすればよかった、こうしておけばよかったと思う点はあるものの、マーキングの作業を避けて通れなかった以上、その最大の難関を何とか乗り切れた点で、まずまず上首尾だったといえるんじゃないでしょうか。
とはいえ最初の語句を抜き出す処理については、あんな方法はとても人に勧められたものじゃないという気持ちと、いやいや、自分ひとりでやるんだからあれで十分じゃないかと開き直る気持ちが相半ばしています。開き直るのはいいとしても、開き直りっ放しでは向上もありません。せめてもう一つ二つ上のレベルを目指したい、というのがささやかな願望です。
------------------------------------------------------------------
今回の索引作成にあたり、以下のスクリプトを利用しました。作者の方々に感謝いたします。
(注1)index from characeter style(市川せうぞーさん作のAppleScript。もともとはInDesignCS用のスクリプトなので、CS3用に一部書き換えて使用しています)
(注2)「InDesignの勉強部屋」の掲示板で小泉さんがある質問の解答の一例として提示されたAppleScript
(注3)ai_TextFrame2InDesignTextFrame.js(kamisetoさん作のjavascript)
(注4)OPEN SPACEの「InDesignCS3自動化作戦」のサンプルスクリプト(古籏一浩さん作のjavascript。古籏さんの執筆された「InDesign自動処理実例集」という書籍もふだん参考にしています)
立て続けに入ってきたものの中に、2ヶ月前から進行中の本の索引を作る仕事がありました。依頼された段階で索引を作ることはわかっていたので、そのこと自体に問題はないのですが、困ったのは索引の作成方法です。親切なところだと、項目とノンブル(ページ)の入ったエクセルのデータが用意されていて、それをもとに索引を作るケースがまず一つあります。もう一つが、項目のデータだけあってノンブルをこちらで拾っていくケース。この場合は最初の例よりたしかに手間はかかりますが、項目のデータを用意してくれるだけまだいいといえます。今回はそのどちらのケースでもなく、編集者がゲラに書き込んだアンダーラインをもとに索引を作らなければならないというものでした。
数日後には帰省の日が迫っているというのに(まあ実際には予定通り帰省できなかったわけですが)、一つ一つ語句を拾っていかなければならないのかと考えると溜息が出ます。とりあえず索引は後回しにし、後日別の仕事が一段落したところで原稿のPDFを開いてみました。
最初のページを表示したところで、思わず「おいおい」と声を上げそうになりました。というのも、初っ端から想定外の箇所があったからです。次いで2ページ目、3ページ目と目を通していくと、想定外の箇所は原稿の書き間違いではなく、意図したものであることがはっきりしました。おまけに抜き出さなければならない語句もやけに多く、中には表内の語句すべてにアンダーラインが入っているページもあります。総ページ数が100数十ページと少ないのでまだいいようなものの、これでは語句を拾い出すだけで何時間かかるかわかったものではありません。
もともと最初の打ち合わせで索引を作るという話があったときから、InDesignの索引機能を使用する考えはありませんでした。InDesignの標準機能では語句を登録する際にいちいちふりがなを入力しなければならず、一つ一つ馬鹿丁寧に登録していたのでは日が暮れてしまうからです。そこで索引語句を手作業で抜き出さなければならないということがわかった時点で、文字スタイルの適用された語句をノンブル入りで一気に抽出するスクリプト(注1)を利用する腹積もりでいました。
ところが原稿を見たときに、このスクリプトを実行する上で一つ困ったこと、先ほど述べた想定外のことがあるのに気づきました。それは何かというと、一続きの語句を2つの索引項目に分けて抽出しなければならないものが混じっていたことです。わかりづらいので一つ例を挙げてみましょう。たとえば、
ABCDEF
という語句があるとします。これがABという語句とEFという語句を索引項目とする場合は何の問題もないのですが、ABCという語句とDEFという語句を索引として抜き出さなければならないとなると、困ったことになります。何故なら、ABCとDEFと2つに分けて文字スタイルを適用しても、2つの語句の間に区切りがないので結局ABCDEFに文字スタイルを適用したのと同じ結果になるからです。つまりABCとDEFとしては抽出されず、ABCDEFという語句が抽出されてしまうのです。この例ではABCとDEFの間に区切りの制御記号を入れれば何とか問題を回避できるかもしれませんが、ABCDとCDEFに分けて抽出しなければならない場合は完全にお手上げです。中にはABCとABEFに分けて抜き出すという理解に苦しむものもありました。
こうなると文字スタイルから索引項目を抽出するスクリプトは使えず、別の方法を考えなければなりません。焦っても仕方がないのでその日の残りは別の仕事に当てることにし、夜寝る前にゆっくりと対策を考えることにしました。
厄介なことになったと思いつつ、ある程度落ち着いていられたのは、InDesignの標準機能で一つ一つ地道に索引に登録していくという最後の手段が残されていたからです。が、できればそういう事態は避けたいのはいうまでもありません。
どんな手段を講じるにしろ、索引語句を範囲指定する作業を省くことはできないという結論に行き着きます。では、範囲指定して選択した語句をダイレクトに抜き出すにはどうすればいいか、そう考え始めると居ても立ってもいられず、夜中にもかかわらず布団から起き上がって一度切ったMacの電源を入れ直しました。
考え方としては、選択した文字列をファイルに書き出すか、コピーしてクリップボードに格納された文字列をファイルに書き出すかです。真っ先に思い浮かんだのはクリップボードの内容を書き出すことだったので、クリップボードをキーワードに検索してみました。すると、目的のものが予想外にあっさりと見つかりました。
それはAdobe Forumsでのやりとりの中で、質問者(natokoさん)がJavaScriptでクリップボードのデータを取得するにはどうしたらいいかと問うているのに対し、Ten Aさんが提示した以下のような回答です(スクリプト部分のみ抜粋)。
tmpFrm = app.activeWindow.activeSpread.textFrames.add(); //仮フレーム生成
app.select(tmpFrm.insertionPoints[0]); //仮フレームにiビーム(インサーションポイント)を設定する。
//クリップボードデータを正常に読み込めない場合のためのエラー処理
try{
app.paste();
}catch(e){
alert("クリップボードの内容を取り込めませんでした。");
}
str = tmpFrm.parentStory.contents; //ペーストしたテキストデータを読み込む
tmpFrm.remove(); //仮フレームの削除
このうち最後の2行はテキストを抜き出すという今回の目的には関係がないので削除し、また1行目のtmpFrm = app.activeWindow.activeSpread.textFrames.add();では抽出されたテキストが各スプレッドに分散してしまい、あとで一括して別のドキュメントにコピーペーストするのに不都合なので、次のように書き改めました。
tmpFrm = app.documents[0].textFrames.add(); //仮フレーム生成
これでスクリプトを実行すると、ドキュメント1ページ目の原点座標に10pt角のテキストフレームが作られ、その中にコピーした文字列が抜き出されます。10pt角のテキストフレームでは当然テキストがオーバーフローした状態になりますが、この場合の目的はあくまでテキストを抽出することなので何ら問題はありません。これを10回繰り返せば同じ座標位置に10個のテキストフレームが積み重なるという寸法です。
見通しが立ったことで多少は気も楽なり、明日の段取りを頭の中でイメージしながら眠りに就きました。
翌日目が覚めると早速作業を開始し、語句を選択してコピー、次いでスクリプトの実行という手順でどんどんテキストを抜き出していきました。つまり通常の作業では語句を選択してコピー、1ページ目に戻ってペースト、また元のページに戻って語句を探し選択、という手順を踏むところを、ページ間を移動することなく3つのアクションで済ませられるわけです。
1章の途中までそうして作業していたのですが、「待てよ、コピーもスクリプトに組み込めばもう1アクション減らせるじゃないか」と遅蒔きながら気づきました。そこで、スクリプトの冒頭に次の1行を書き加えました。
app.copy();
これで語句を選択した状態でスクリプトを実行するだけで、テキストが抜き出されます。わずか1アクションの違いとはいえ、何百回と同じ操作を繰り返すことを考えるとその差は十分大きいといえます。
この方法の欠点は、抜き出し終わった語句に目印がつくわけではないので、どこまで作業が終わったかが確認できないことです。途中うっかり席を立とうものなら、どこまで作業が終わったかを忘れてしまい、1ページに戻って見直さなければならないということにもなりかねません。しかしそれは注意を払っていれば防げることですし、短時間で作業を終わらせられるというメリットを打ち消すほどのものではありません。改良の余地はあるにしろ、今後同様の案件があった場合にも使える方法だと思います。
1章の作業が終わったところで、テストも兼ねて抜き出した語句をテキストファイルに纏めることにしました。この時点では、抜き出されたテキストは下図のような状態になっています。
画面上はオーバーフローした1つのテキストフレームしか見えませんが、実際は何十というテキストフレームが重なった状態になっています。これをすべて選んでコピーし、新規ドキュメントを作成して適当な位置にペーストします。最後にAppleScriptで下記のスクリプトを実行します。
tell document 1 of application "Adobe InDesign CS3" to contents of stories as Unicode text(注2)
すると抜き出した語句がスクリプトエディタにカンマ区切りですべて書き出されます。それをテキストエディタにコピーペーストし、カンマを改行に置換して完成です。
見たところ特に問題はないよいうなので、同様の作業を2章以降についても繰り返します。ところがここで問題が一つ発生しました。本文中にはところどころにIllustratorで作成した図が配置してあるのですが、その図中の語句まで索引に含めなければならないものが出てきたのです。それを見た瞬間「えーっ、どうするんだよ」という声が思わず出てしまいました。面倒くさいので無視しようかとも思いましたが、さすがにそういうわけにもいきません。仕方がないので図中のテキストをInDesignの該当ページに一つ一つ貼り付けることにしました。
IllustratorのテキストをそのままInDesignにペーストすると、文字情報が消えてグラフィック化されてしまいます。かといってテキストエディタ経由でコピーペーストしていたのでは効率が悪すぎます。ここでもスクリプト(注3)にひと働きしてもらうことにしました。
図が何ページにもわたって連続するところにはうんざりしましたが、無事最後の章まで語句の抽出作業が終わりました。InDesignで一語一語索引に登録していったのでは、一日で作業が終えられたかどうかもわかりません。その意味では倍以上早く作業を終えられたのではないでしょうか。
次に出来上がった語句の一覧にノンブルを付加していくわけですが、ここでも当然スクリプト(注4)の出番です。
このスクリプトを実行すると、語句の一覧と合致する本文中のテキストがノンブルと一緒に抽出され、テキストファイルに書き出されます。抜き出した語句の数が全部で1000近くあったのでそれなりに時間はかかりましたが、1章あたりおおよそ3分前後で処理が終わりました。
章ごとに書き出されたテキストファイルをExcelで一つにまとめ、ふりがなを付ける作業に移ります。が、スクロールしてデータをざっと見渡しているうちに、おかしなことに気づきました。ところどころノンブルの列が空白になっているところがあるのです。語句は本文中から抜き出したものですから、本来ノンブルが空白になるはずはありません。一体何が起きたのかとしばしデータの前で考え込みました。
ノンブルが空白のところは一箇所や二箇所ではなく、相当な数があります。本文と照合してみたところ、ノンブルが抜けているのは表内の語句であることが判明しました。なんだ、そうだったのかと安堵すると同時に、困ったことになったと思いました。この期に及んでスクリプトを書き直している余裕はなく、かといって手作業でノンブルを入れていったのでは何時間かかるかわからなかったからです。それに折角ここまで手作業に頼らずに来たのに、今更手作業に戻るのも業腹です。
頭を悩ませていたのはわずかな時間で、すぐに対策を思いつきました。
表をテキストに変換してしまえばいいのです。安易といえば安易な方法ですが、これ以上の名案はありそうにありません。
行のずれに注意しながらすべての章の表をテキストに変換し、もう一度スクリプトを実行し直します。出来上がったテキストファイルをExcelに取り込み、各章のデータを合体して確認すると、今度はほぼ問題なさそうでした。
ほぼ、という留保をつけたのは、やはりいくつかノンブルが空白のところが残ったからです。どこが空白だったかというと、最初に述べたABEFのように、間の数語を飛ばした語句のところです。もともと本文にはABEFという語句は存在しないのですから、ノンブルが付かないのも当然です。仕方がないのでこれらに関しては手入力することにしました。
さて、残る面倒な作業はふりがなを振ることです。これが終われば作業は終わったも同然といっても過言ではありません。
ふりがなを振るにはPHONTIC関数を使えばいいという話をどこかで見たか聞いたかしたことがあるので、これもわけなくできるだろうと楽観していました。まず適当なセルにカーソルを置き、関数を入力します。とりあえず1つ範囲を指定してリターンキーを押すと、ふりがなが表示される……はずが表示されません。なぜか元の語句がそのまま表示されるだけです。何かの間違いだろ、と思いつつ二度、三度とやり直しても、結果は変わりません。ここで他に何も策がなければあわてふためくところですが、もう一つ別の策も用意してあったので潔く諦めてそちらの方法に切り替えることにしました。
あとで調べたところによると、PHONTIC関数はExcelで入力された情報をもとにふりがなを作成するのだそうです。今回のデータはテキストエディタからコピーペーストしたものですから、ふりがなが振られないのは当然の結果でした。ためしにExcelで直接入力した文字にPHONTIC関数でふりがなを振ってみたところ、たしかにちゃんと表示されます。こういうことは実際に経験してみなければわかりません。
Excelでのふりがな付けの代わりに利用したのが、漢字仮名変換サイトでした。翻訳サイトの漢字仮名変換版といえばわかりやすいでしょうか。どれくらいの変換精度なのか多少の不安があったので最初はPHONTIC関数を利用することを考えたのですが、実際に試してみると、まあ使えなくはないレベルにまでは変換してくれました。専門用語がかなり含まれていた点を考慮すれば、仕方のない結果といえます。
変換されたテキストを再びExcelに戻し、上から順にチェックしていきます。おかしなところは手作業で直し、明らかな誤変換を潰していきました。
これで材料がすべて揃ったわけですが、今回は編集者の校正用に一覧表の形で出してくれと依頼されていました。どんな形式で出すにせよ、材料さえ揃っていればあとはどうにでも料理できるはずです。やれやれやっと終わりそうだと思いながら渡された出力サンプルを見た僕は、またしても声を上げそうになりました。
普通索引といえば語句のあとにノンブルがつづき、それが五十音順に並んでいるものを想像します。が、渡された出力サンプルはまずノンブルがあり、そのあとに語句と読みが入るという形になっていたからです(下図参照)。こんな形のものはまったく想像していなかったので、何かの間違いじゃないかと何度も見直しました。
001 AAA ○○○
001 BBB ○○○
002 CCC ○○○
002 DDD ○○○
・
・
・
Excelのデータをどう加工すればこんな形にできるのか、頭の中でいろいろシミュレーションしてみても、すぐに行き詰まってしまいます。見込みのないことに時間を費やすよりもここは依頼先に聞くのが得策だと考え、電話で問い合わせることにしました。
*
さて、本当はこの後の顛末も書くつもりだったのですが(実際最後まで書いたのですが)、話が本題から外れますし、取引先のことをあれこれ書くのもどうかと思いますので割愛します。(ちなみに上記の件は、ExcelではなくInDesignのプラグインで処理していたという落ちでした)。
これまで索引といえばデータが支給される場合がほとんどだったので、今回のように一から作成していくのは初めての経験でした。作業が終わってからああすればよかった、こうしておけばよかったと思う点はあるものの、マーキングの作業を避けて通れなかった以上、その最大の難関を何とか乗り切れた点で、まずまず上首尾だったといえるんじゃないでしょうか。
とはいえ最初の語句を抜き出す処理については、あんな方法はとても人に勧められたものじゃないという気持ちと、いやいや、自分ひとりでやるんだからあれで十分じゃないかと開き直る気持ちが相半ばしています。開き直るのはいいとしても、開き直りっ放しでは向上もありません。せめてもう一つ二つ上のレベルを目指したい、というのがささやかな願望です。
------------------------------------------------------------------
今回の索引作成にあたり、以下のスクリプトを利用しました。作者の方々に感謝いたします。
(注1)index from characeter style(市川せうぞーさん作のAppleScript。もともとはInDesignCS用のスクリプトなので、CS3用に一部書き換えて使用しています)
(注2)「InDesignの勉強部屋」の掲示板で小泉さんがある質問の解答の一例として提示されたAppleScript
(注3)ai_TextFrame2InDesignTextFrame.js(kamisetoさん作のjavascript)
(注4)OPEN SPACEの「InDesignCS3自動化作戦」のサンプルスクリプト(古籏一浩さん作のjavascript。古籏さんの執筆された「InDesign自動処理実例集」という書籍もふだん参考にしています)







※コメント投稿者のブログIDはブログ作成者のみに通知されます