








 ホームページやブログを丸ごと保存する(オフラインで閲覧できるようにする)方法
ホームページやブログを丸ごと保存する(オフラインで閲覧できるようにする)方法
はじめに
ブログはホームページとは違って自分のPCにデータが残らないので、「いざ」って時に困ります。なので、今日は今まで書いたブログの記事を一括して保存することにしました。(そうしておけば、ホームページに転載するときにも都合がいいし、バックアップにもなる。)
ホームページなどを一括保存するフリーソフトは幾つかあって各々を試してみましたが、今回は僕的に使い勝手がよく、また皆さんに紹介するにもわかりやすいと思うものを取り上げます。
「WeBoX」
http://webox.sakura.ne.jp/software/webox/index.html
サイトおよびブログの構成そのままにオフラインで閲覧できるようにしてくれる一括ダウンロードソフトです。
なにはともあれ、ダウンロードページへ行って最新版を手に入れましょう。
インストール手順などは省いて(大丈夫ですよね)、保存の手順だけを示していきます。
まずはメイン画面です。プログラムを起動すると、この画面が出てきます。
次です。ツールバーにある「設定」の中の「環境設定」をクリックします。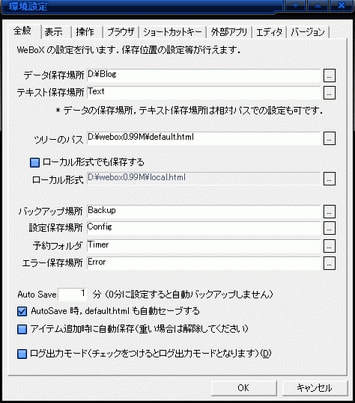
ここで、「データ保存場所」を指定しておきましょう。
自分のわかりやすい場所および名前を入力すると良いと思います。
その他は、とりあえずデフォルトのままで使ってみましょう。
(もし実際に使ってみて、取りこぼしがあるようならば、その時に設定を見直してみる)
OKして「環境設定」を閉じると、再びメイン画面に戻ります。
そしたら、取り込みたいウェブサイトなりブログのトップページのアドレスを「アドレス」の中にコピペします。
※このとき、僕のブログみたいにアドレスの最後に「/」スラッシュが抜けている場合、下層フォルダが作成できずエラーとなってダウンロードされないので、スラッシュがないときは必ず入れておかなくてはなりません。
アドレスを入力してEnterを押すか、どこか別の余白をクリックすると、そのページが画面上に出てきます。そしたら、次にメイン画面の左側にある、「未整理フォルダ」を選択します。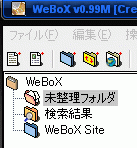
この状態で、「サイトをまるごと取り込む」のボタンをクリックします。
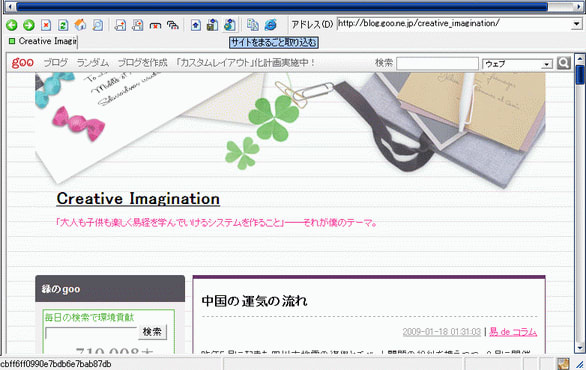
すると、次の画面が出てきますので、リンクを辿る際のURLを確認し、その辿る深さを指定します。
通常は何もせずにそのままOKで大丈夫だと思いますが、もし取りこぼすようならば回数(深さ)を増やしてみてください。(あるいは、先にも書いたように「取り込み設定」を見直してみる。)
OKを押せばダウンロードが始まります。
あとはダウンロードが全て終了するまで気長に待つだけです。
ダウンロードされたファイルは、サイトおよびブログのフォルダ階層を再現しつつ、オフライン閲覧用にリンクが修正されますので、ローカルフォルダにあっても、普通にブログやサイトを読んでいるような感じで使えます。
トップページ(index.htmlファイル)のショートカットをデスクトップにでも置いておけば便利でしょうね。
設定の仕方によりますが、このWeBoXで僕が気に入っているところは、あまり無駄なファイルを落とさずに必要なファイルだけをダウンロードしてくれるという点です。
また、サイト解析をした後に最適化して取り込むというような面倒な事をせずに、ストレートに丸ごと保存できるというシンプルさも気に入っています。
~おまけ~
ここでは、「WeBoX」を紹介しましたが、他にも同じようなソフトは多種あります。
もし「WeBoX」で上手くいかなかった場合は、他のも試してみてください。
「Website Explorer」
http://www.umechando.com/webex/index.html
このソフト、今回紹介した「WeBoX」とインターフェースが似ています。
各種設定も詳細に行えますし、IEのお気に入りも引き継ぐようで、簡易ブラウザーとしても利用できます。
まあ、ダウンロードに関してはサイト(ブログ)探査を行ってからなので時間も掛かるし、少し面倒ですね。その分、多機能で優れている点は魅力的ですけども。(検索の高速化のためのデータベース化や最適化に時間が掛かるのは玉に瑕かな。いい機能ではありますが)
一括ダウンロードの手順としては、取り込み設定をした後、探査「開始」。(ロケットのボタン)
探査完了まで待ったら、「ツール」の「フォルダダウンロード」で一括ダウンロードできます。
以下に、簡単に画像を使って手順を示しておきます。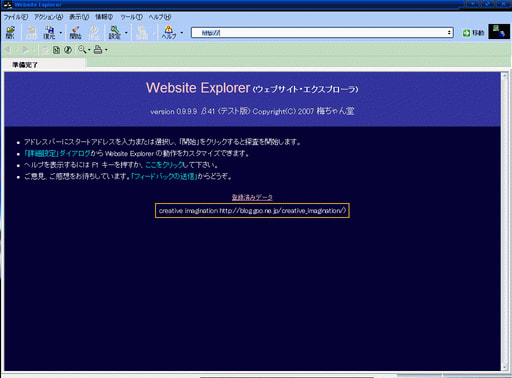
起動後に出てくるメイン画面です。
画面の上にアドレスを入れる場所がありますので、まずは取り込みたいサイトやブログのURLをコピペします。
続いて、探査&ダウンロードする際の設定を行っておきましょう。
基本的にはデフォルトでいいと思いますが、一応、僕はフォルダの階層を指定しています。(デフォルトでは指定されていない)
あとは、「ミッション」内にある「収集方法」の設定くらいでしょうか、主に必要なのは。
これで後は探査をしていくわけですが、問題は、(デフォルト設定では)ブログのカレンダーのリンクをMAXまで辿ってしまうこと。
これ、取り込み設定次第で回避できるのか分かりませんが、余計な容量と時間を食ってしまうので修正したほうがいいと思います。ちなみにgooブログの場合、探査の最後、99%のところでカレンダーの探査が始まるので、不要箇所まで進んだら中止しておきましょう。そのまま続けると、なかなか終わらずイライラします。
可能ならばダウンロードする前に該当ファイル、もしくはフォルダを除外しておいたほうがいいです。(ちなみに、次の「巡集」では、「ブログのカレンダー機能を辿らない」のON/OFFができる)
次です。
「探査」が終わったら、トップページが選択されていることを確認して、「ツール」→「フォルダダウンロード」をクリックします。(左のツリーのフォルダを右クリックして出てくるメニューから選んでもいい)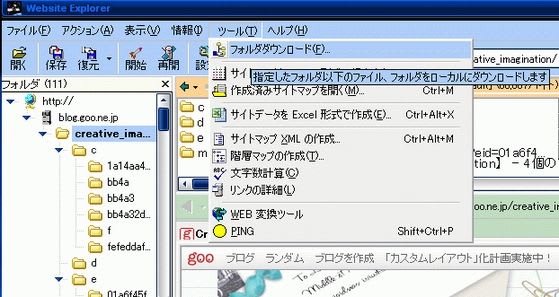
その後、何度か設定画面が出てきますが、基本的には何も変えずに次に進んで行けばいいはずです。ただし、最後の保存先の指定だけは必ずしておきましょう。
すべての設定が済んだらダウンロードを始めます。
そうしてダウンロードが終わると、最後に「最適化」が行われて終了です。(・・・結構長い)
今すぐ確認するかのメッセージが出るので、必要ならば見ておきましょう。
また、先述したように、「カレンダーのリンク追跡」が過剰になってしまった場合は、ここで不要ファイルをすべて削除しておきましょう。それだけで数十MBも容量を消費している場合があります。
※このソフトに関しては、あまり使い込んでないので説明が不十分(不親切)かもしれません。詳しい人がいれば、より簡単で適切な使い方を教えて下さい
「巡集」
紹介ページ
http://ringonoki.net/tool/download/junshu.php
http://xylocopal.exblog.jp/1376037
広告削除機能という、ステキな機能がついてます。
リンクを辿る階層を個別に設定できたり、辿るリンクを複数指定することもできます。
けれど、個人的には設定が少し難しい感があり、不要ファイルをいつまでもダウンロードし続けてしまうこともあるので注意が必要です。
「波乗野郎」
http://www.bug.co.jp/nami-nori/
上の「巡集」に似たソフトです。
ダウンロード後に気の聞いたセリフを言ってくれるところなんかが結構好きなんですが、残念なことに、かなり前に開発がストップしているようです。
「GetHTMLW」
http://www.vector.co.jp/soft/win95/net/se077067.html
これも要領としては、「WeBoX」のようなやり方で使えます。
取得条件の設定も細かくできますし、取り込んだ後の処理の操作(コピー・移動・消去)もツールバーから指定できますので、必要なファイルだけを残すこともできます。自動切断機能もついています。・・・でも、ブログには向いてないかも。
僕は、基本的には今回紹介した「WeBoX」を使っていますが、より使いやすいソフトを探して紆余曲折していた時期には、これらのソフトを使い比べていました。
まだ他にもありますが、とりあえずこの辺りのソフトで上手に設定をしていけば、目的は果たせるだろうと思います。では、幸運を祈ります
{kind=link}
最初の方法でダウンロードまでは出来たと思うのですが、さて、これをオフラインで見るにはどうしたら良いのでしょうか?
webの画面上で、ストップしています。
「ダウンロードまではできた」とのことですが、目的のサイトやブログの取り込みはできた、ということでしょうか?
Weboxを使っているなら、データ保存場所に指定したところにできるフォルダの中に、そのサイトのページが取り込まれているはずです。
ただ、この記事はもう10年前のものですので、WeboxやWebsite Explorerその他で、取り込み不可能になっているサイトなども多くあるようです。
出来ました。余白をクリック又はエンターのところで間違っていたみたいです。
見事まるごとダウンロードしオフラインで見ることがで来ました。
再度、ありがとうございました。{/
ヤフーのブログを丸ごと保存したいとあれこれ試してここにたどり着きました。
今まで試して一番判りやすくて有難いのですが、最後の丸ごと取り込むで「フィルタ設定を確認してください」のエラーメッセージが出ます。
ヘルプなど探してみましたが、らちが明かず弱っています。なにか解決策があれば宜しくご教示いただければ有難いです。
どのソフトを使っているのでしょうか?
もしWeBoXでしたら、次のような回答を見つけましたので、ご紹介しておきます。
“「フィルタ設定を確認してください」と表示された方はURL欄の”https://”を”http://”に変更してみてください。”
(https://freesoft-100.com/review/soft/webox.html)
なお、Website Explorerのほうは今も更新が続けられているようなので、そちらであれば現在のブログやサイト構成に合っているだろうと思います。試してみてください。
またご報告いただけると他の方の助けにもなると思います。
お陰様でエラーメッセーの件は解決しましたが、ファイルを開く事ができずにそちらは削除してしまいました。
Website Explorer、試してみます。
日にちがないので焦っていますが、何とか頑張ります。
やっと保存する事ができました。ありがとうございます。
この記事を書いたことでお力になれたのなら幸いです。