








火曜日ってあっという間にくるのね。。。と思う今日この頃。
今回は先週シェープファイルにしたDEMのデータをグリッドにしてみようと思う。グリッドにすると、表示が速いし、傾斜角とか斜面の向きとか計算できるし。ただし、ここから先はSpatial Analystが必要だ。持ってない人ごめんなさい。
ポイントのシェープファイルからグリッドを作成するには、
- 単純にシェープファイルをラスタに変換する方法
ArcToolbox>変換ツール>ラスタへ変換>ポイント→ラスタ(Point to Raster) - ポイントシェープから補間をしてラスタに変換する方法
ArcToolbox>Spatial Analystツール>内挿 ツールボックスに含まれるツール
の2つがある。1.の方法だと処理は速いんだけど、ラスタに値を割り当てる際、統計的な処理が行われてしまい、DEMには不向きだと思う。いや、表示だけならまぁいっかとも思うけど。
ここでいう統計的な処理というのは、ポイントからラスタに変換する際に、1つのセルの中に複数のポイントが入った場合、その平均をとるとか、合計をとるとか、という処理を指す。
今回は(約)5m間隔のポイントシェープができているのだが、1.の方法で30mのセルサイズのグリッドを作成するように指定すると、30mの中に複数のポイントが含まれることになる。この複数のポイントを合計したり、最も値の出現数が多かったりするものをそのセルの値として使って、グリッドを作る、ということになる。
今回の場合、平均値を出力するならまぁ悪くはないかもしれないけど、そのセルの真ん中から複数のポイントへの距離も考慮されずにそのセルの値にしちゃうのはうーん、って思わない?かな。。。
ついでにセルサイズが30mであれば大丈夫だけど、5mとか1mとかだと、そのセルに入るポイントがないという事態が発生し、ここには標高値は入らない。この場合斜めに白い線が入ったようなグリッドが作成される。それはこまるっしょ。
ということで、今回は2.の内挿のスプラインを使おうと思う。
スプラインを実行するには、「ArcToolbox>Spatial Analystツール>内挿>スプライン(Spline)」を実行する。
入力ポイントフィーチャには前回ポイントシェープに変換した基盤地図情報、で、Z値フィールドは「標高」になる。出力ラスタなどを適宜入力して、出力セルサイズは今回は処理が重いかもしれないけど5mにする。あと、オプションのスプラインの種類で「TENSION」を指定する(と大きな外れ値のないきれいな標高データができることが多い)。
もし文京区の形でグリッドを出力したい場合は「環境」ボタンをぽちっと押して、「処理範囲」と「ラスタ解析」の「マスク」を指定しておこう。四角いままでいいようなら、「環境」の設定は抜かしてくださいな。
余裕があったら、前回ダウンロードした基盤地図の文京区の範囲をポリゴンにしておいて、ここで指定するといいんだけど、そういえば少し前にe-Statのページから文京区の町丁目界のデータをダウンロードしたのでそれを使っちゃうことにする。ああ、データの測地系、座標系が同じってすばらしい。
まずは「処理範囲」の文字をクリックして、「範囲」のところで、「h1713105.shp」を指定する。
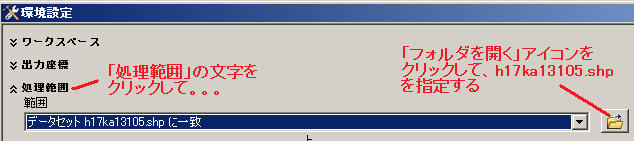
同様にして、ラスタ解析の「マスク」のところで「h1713105.shp」を指定する。

2つの設定が終わったら「環境設定」ウインドウの「OK」をクリックする。
で、スプライン(Spline)のウインドウでOKをクリックする。入力の指定は、例えば以下のような感じ。

で、しばししばしまつ。結構待つかも。(1分ぐらい待った)。
グリッドができあがるとこんな感じ。

ついでに文京区の形で切り出すとこんな感じ。

うんうん。きれいきれい。
しかし、ふと基盤地図情報のメタデータ(fmdid0-6.xml)を見てみると、今回ダウンロードしたのは数値地図5mメッシュ(標高)を0.2度間隔で読み直したデータだったらしい。それをまた5mに補間し直すって。。。何か分析に入る前に、ちょっとずつ誤差が出てきてしまうような気がする。
ちゃんと分析をしたいなら数値地図を買って、point to rasterを出力セルサイズ5mで実行する方がよいかもしれない。数値地図は確実に5mメッシュであって、0.2度メッシュ=約5mメッシュじゃないということだ(と思う)から、Point to Rasterで統計的な処理が行われる心配もないわけだし。
まま、今週はこんなところで。。。








