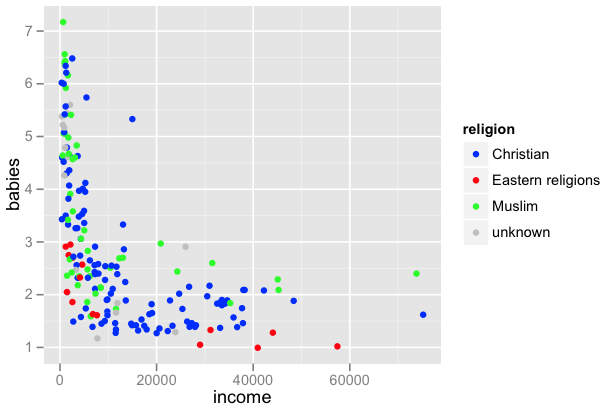
前の記事(元記事も)での religion = unknown の記号の色が gray で,バックグラウンドの色と近くて,目に入りにくいということもあるし,プログラムがごちゃごちゃしているので religion 別の散布図を描いた方がよさそう。
ということで,描いてみた。シンプルに plot を使って(余分な情報はいらない)。
df.split <- split(df.merged, df.merged$religion)
layout(matrix(1:4, 2, byrow=TRUE))
par(mgp=c(1.6, 0.6, 0), mar=c(3, 3, 0.5, 0.8))
lapply(df.split, function(d) {
plot(babies~income, data=d, xlim=c(0, 80000), ylim=c(0, 7),]
pch=19, col="#00330060", cex=0.7)
text(35000, 6, d[1, "religion"])
})
layout(1)
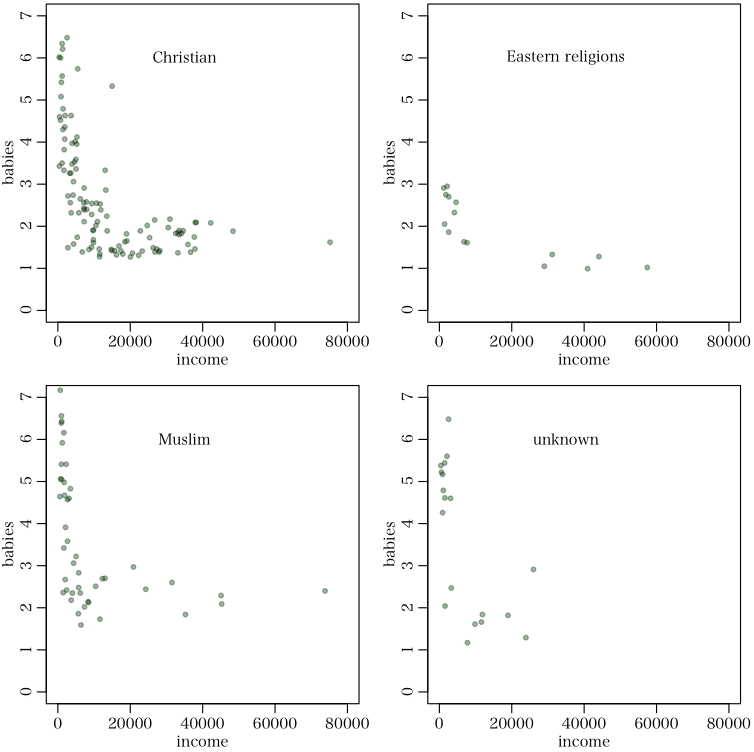
- Eastern religions は国の数も少ないが,babies が 3 ぐらいまでで,他とはちょっと違う。
- income < 15000 では babies > 3 の国がかなりある。income > 15000 では babies はほぼ一定。