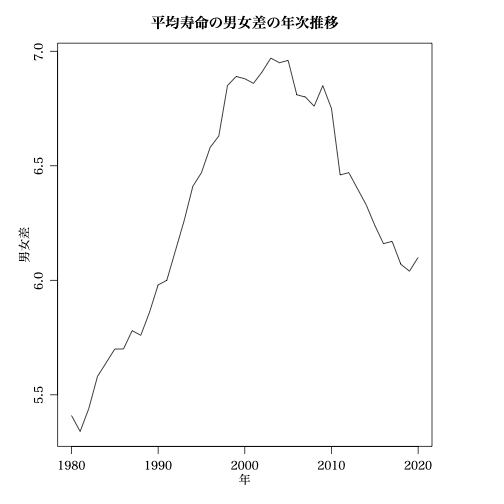
中澤先生が,男女の平均寿命の差について,「格差が拡大してから低下している」とツイートしたそうだ。
https://minato.sip21c.org/im3r/20220129.html
中澤先生の図は(日本語が文字化けしているので,簡略化した)
le0 <- data.frame(
YEAR = 1980:2020,
Males = c(73.35, 73.79, 74.22, 74.20, 74.54, 74.78, 75.23, 75.61, 75.54, 75.91,
75.92, 76.11, 76.09, 76.25, 76.57, 76.38, 77.01, 77.19, 77.16, 77.10,
77.72, 78.07, 78.32, 78.36, 78.64, 78.56, 79.00, 79.19, 79.29, 79.59,
79.55, 79.44, 79.94, 80.21, 80.50, 80.75, 80.98, 81.09, 81.25, 81.41, 81.64),
Females = c(78.76, 79.13, 79.66, 79.78, 80.18, 80.48, 80.93, 81.39, 81.30, 81.77,
81.90, 82.11, 82.22, 82.51, 82.98, 82.85, 83.59, 83.82, 84.01, 83.99,
84.60, 84.93, 85.23, 85.33, 85.59, 85.52, 85.81, 85.99, 86.05, 86.44,
86.30, 85.90, 86.41, 86.61, 86.83, 86.99, 87.14, 87.26, 87.32, 87.45, 87.74))
le0$sexdif <- le0$Females - le0$Males
plot(sexdif ~ YEAR, data=le0, type="l", lty=1, lwd=1, col="black",
xlab="年", ylab="男女差",
main="平均寿命の男女差の年次推移")
により,以下の図を掲示している。
なるほど,「格差が拡大してから低下している」
これを拝見して,なんとなくピンときて私が描いてみた図は
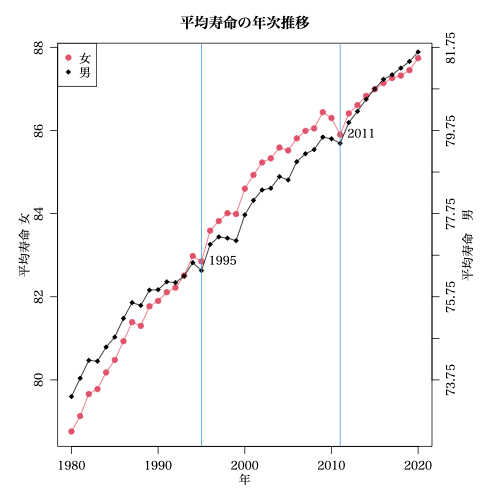
女の平均寿命と,男の平均寿命+6.25 を併記してみた。(6.25 は恣意的に選んだ)
かつて,女の平均寿命は伸び率が大きく,男の平均寿命の伸びを追いかけ,1995年の両者とものカックンをのぞき追いつき追い越した。
そして再びの 2011 年の大ガックンを迎え,女の伸び率は男の伸び率と同じくらいになって,現在に至る。
2011年は, 東日本大震災のあった年だなあ。それと関係があるのだろうか。人口学にはとんと疎いが,多分関係があるのだろう。
1995年は, 何があったっけ。ググッてみた。1位:阪神大震災 ,2位:オウム真理教による地下鉄サリン事件 , 3位:不良債権で住専やコスモ、木津、兵銀など金融機関の破綻。ガックンの原因はわかったようで,わからない。
6.25 は恣意的と書いたが,6.5 だとちょっとイメージが変わる。
2011 年を契機に(?)女の伸び率が低くなっている(?)。
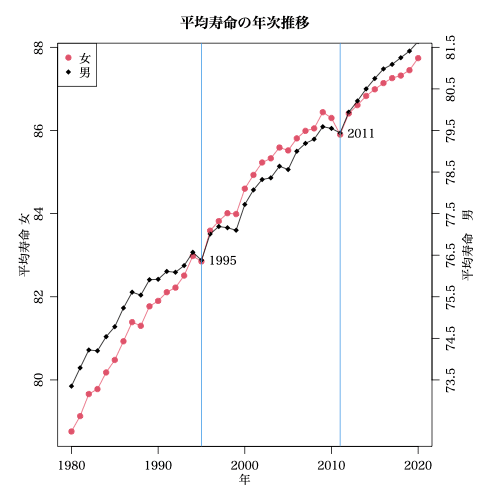
プログラムも載せておくが,最近メッキリ R のプログラミング力が落ちてしまって,恥ずかしい限り。
delta = 6.25
par(mar=c(4, 4, 3, 5), mgp=c(1.8, 0.8, 0))
plot(le0$Females ~ le0$YEAR, col=2, pch=19,
xlab="年", ylab="平均寿命 女", main="平均寿命の年次推移")
points(le0$Males+ delta ~ le0$YEAR, col=1, pch=18)
lines(le0$Females ~ le0$YEAR, col=2)
lines(le0$Males+ delta ~ le0$YEAR, col=1)
text(le0$YEAR[16], le0$Females[16], le0$YEAR[16], pos=4)
abline(v = le0$YEAR[16], col=4)
text(le0$YEAR[32], le0$Females[32], le0$YEAR[32], pos=4)
abline(v = le0$YEAR[32], col=4)
axis(4, 80:88, as.character(seq(80-delta, 88-delta)))
legend("topleft", c("女", "男"), pch=c(19, 18), col=c(2, 1))
mtext("平均寿命 男", 4, 2)