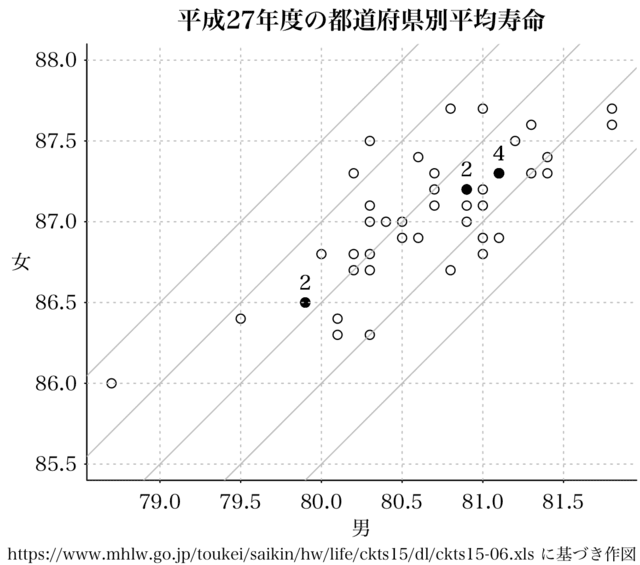
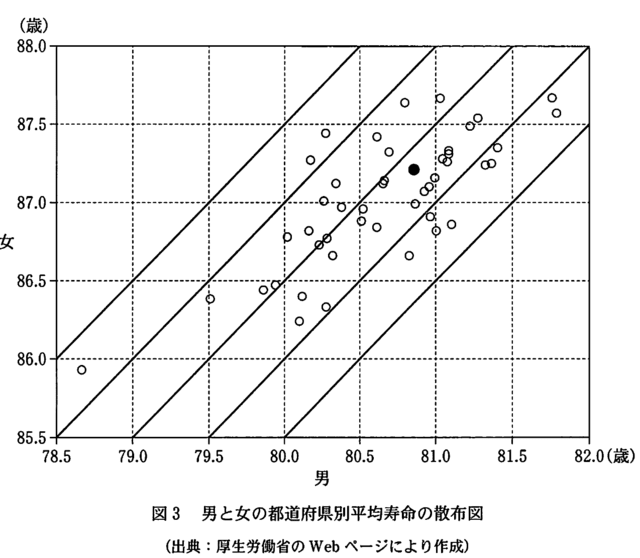
センター試験の男女の都道府県別平均寿命の散布図は,小数点以下 2 桁までのデータが記載されている
https://www.mhlw.go.jp/toukei/saikin/hw/life/tdfk15/dl/tdfk15-09.xls
によるものと判明したので,やり直してみる。
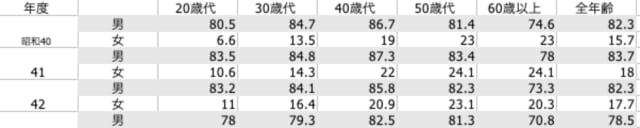
表5-1 が平均寿命の推移(男),表5-2 が平均寿命の推移(女)で,それぞれが 7 段組みになっているので,最終的に以下のようなデータフレームにまとめ上げる。
pref.name male1965 female1965 male1975 female1975 male1985 female1985 male1995 … female2015
1 北海道 67.46 72.82 71.46 76.74 74.50 80.42 76.56 …
2 青森 65.32 71.77 69.69 76.50 73.05 79.90 74.71 …
3 岩手 65.87 71.58 70.27 76.20 74.27 80.69 76.35 …
4 宮城 67.29 73.19 71.50 77.00 75.11 80.69 77.00 …
5 秋田 65.39 71.24 70.17 75.86 74.12 80.29 75.92 …
6 山形 66.49 71.94 70.96 76.35 74.99 80.86 76.99 …
:
46 鹿児島 67.36 72.71 70.54 76.53 74.09 80.34 76.13 …
47 沖縄 NA NA 72.15 78.96 76.34 83.70 77.22 …
# https://www.mhlw.go.jp/toukei/saikin/hw/life/tdfk15/dl/tdfk15-09.xls
# 図表データのダウンロード
# 表5-1 が平均寿命の推移(男),表5-2 が平均寿命の推移(女)
# install.packages("readxl")
library(readxl)
# データが 7 段組み(S40, S50, S60, H7, H17, H22, H27)になっているので分解と結合
pref.name = c("北海道", "青森", "岩手", "宮城", "秋田", "山形", "福島",
"茨城", "栃木", "群馬", "埼玉", "千葉", "東京", "神奈川", "新潟",
"富山", "石川", "福井", "山梨", "長野", "岐阜", "静岡", "愛知",
"三重", "滋賀", "京都", "大阪", "兵庫", "奈良", "和歌山", "鳥取",
"島根", "岡山", "広島", "山口", "徳島", "香川", "愛媛", "高知",
"福岡", "佐賀", "長崎", "熊本", "大分", "宮崎", "鹿児島", "沖縄")
year = c(1965+0:4*10, 2010, 2015)
get.data = function(name, value) {
name = gsub(" ", "", name)
return(sapply(pref.name, function(pn) value[which(pn == name)]))
}
data3 = matrix(0, 47, 14)
for (page in 1:2) {
data = as.data.frame(read_excel("tdfk15-09.xls", sheet = page+5,
col_types = rep(c("skip", "text", "numeric"), 7)))
data2 = data[c(6:53),]
data2 = data2[-ifelse(page == 1, 52, 53),]
data2[47, 1] = "沖縄" # 1965 年には沖縄は含まれない
for (i in 1:7) {
data3[, i*2-(2-page)] = get.data(data2[, i*2-1], data2[, i*2])
}
}
data4 = data.frame(data3)
colnames(data4) = c(outer(c('male', 'female'), year, paste0))
data5 = cbind(data.frame(pref.name), data4)
all2.data = data5 # 最終的なデータフレーム
write.csv(all2.data, "all2.csv", row.names=FALSE)
all2.csv を用いて,目的の散布図を描く。
par(las=1, bty="l", mar=c(4, 4, 2, 0.5), mgp=c(2, 0.4, 0), tck=-0.005)
df2 = read.csv("all2.csv")
plot(female2015 ~ male2015, data=df2, asp = TRUE, xlim=c(80, 80.5), ylim=c(85.5, 88.0),
xlab="", ylab="", main = "平成27年度の都道府県別平均寿命")
for (intercept in 1:5) {
abline(intercept*0.5+5, 1, col="gray")
}
abline(v=seq(78.0, 82, by=0.5), h=seq(85.5, 88.0, by=0.5), lty=3, col="gray")
mtext("男", side=1, line=1.5)
mtext("女", side=2, line=2.3, las=1)
mtext("https://www.mhlw.go.jp/toukei/saikin/hw/life/tdfk15/dl/tdfk15-09.xls に基づき作図", side=1, line=2.5, adj=1, cex=0.8)

正しく描けたようだ。
次は,男女差のヒストグラム。
選択肢の中にあるヒストグラムが描けた。
par(las=1, bty="l", mar=c(4, 4, 2, 0.5), mgp=c(1.5, 0.4, 0), tck=-0.01)
hist(df2$female2015 - df2$male2015, breaks=seq(5.5, 7.5, by=0.25), right=FALSE,
col="aliceblue", xlab="歳", ylab="度数",
main="平成27年の男女の都道府県別平均寿命の差")