








"Getting data from GapMinder.org" のグラフについて
当初は,このグラフ(図1)を見て,「記号の大きさが人口に比例していないなあ。困ったものだ」と思っていた。おまけに,記号の大きさは人口そのままではなく,log(人口+1e7) になっている。
図1

ggplot は記号の大きさを,最大値と最小値から決めるようで,筆者が 1e7 を採用したのは,記号の大きさのバランスがちょうど好みにあったのだろう。population をそのまま使った図2と比較すればよい。
図2

そして,このふたつの図を比べると,受ける印象が全く違うことにびっくりする。どちらかの図が不適切なわけだ。だって,どちらも適切なわけがない。
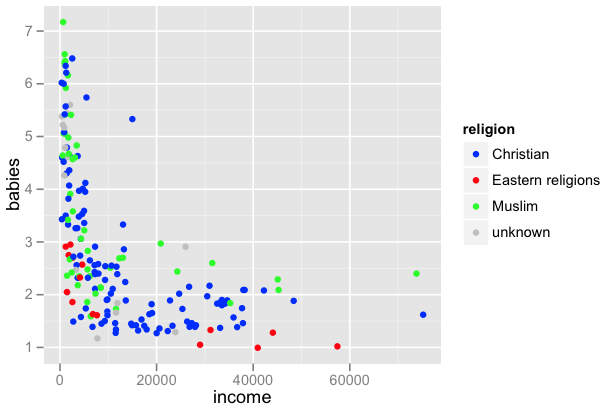
筆者がなぜ babies とincome, population, religion を取り上げたのか真意は不明だが,このデータを分析してみる。
まず,religion 別に population, babies, income 相互間の相関を見る。
人口が極端に大きいふたつの国(インドと中国)の影響を除くために,スピアマンの順位相関係数を計算した。
> df.split <- split(df.merged, df.merged$religion)
> lapply(df.split, function(d) round(cor(d[,3:5], use="pair", method="spearman"), 3))
$Christian
population babies income
population 1.000 -0.029 -0.028
babies -0.029 1.000 -0.721
income -0.028 -0.721 1.000
$`Eastern religions`
population babies income
population 1.000 0.104 -0.275
babies 0.104 1.000 -0.871
income -0.275 -0.871 1.000
$Muslim
population babies income
population 1.000 0.023 -0.098
babies 0.023 1.000 -0.757
income -0.098 -0.757 1.000
$unknown
population babies income
population 1.000 0.043 0.028
babies 0.043 1.000 -0.689
income 0.028 -0.689 1.000
この結果を見ると,religion に係わらず,3変数は同じような相関関係にあることがわかる。Eastern religions で,population と babies, income の間の相関が他と比べると若干高いが。babies も income も population で調整されているので,こういうことをしなくても population の要因は除外してよいだろうということがわかる。とすれば,当初描かれた図は,特に人口サイズが強調された図は不適切ということであろう。ということで,図3を得る。
図3
(つづく)



















※コメント投稿者のブログIDはブログ作成者のみに通知されます