#=
Julia の修行をするときに,いろいろなプログラムを書き換えるのは有効な方法だ。
以下のプログラムを Julia に翻訳してみる。
塗り分け地図を描く
http://aoki2.si.gunma-u.ac.jp/R/color-map.html
ファイル名: colormap.jl
関数名: colormap, colormap1, colormap2, colormap3, colormap4
rgb(i::Int), rgb(str::String)
翻訳するときに書いたメモ
x = [1,2,3,4,]
append!(x, 5)
はいいのに,
y = [:red, :yellow]
append!(y, :red)
はエラーになる
append!(y, [:red])
なら,通る。何故なんだ!
引数の型が違う関数を同じ関数名で定義できるのは面白い。
rgb(i::Int), rgb(str::String)
colormap1 〜 colormap4 もそのようにするのもよいかも知れないが,混乱しそうなので止めておく。
=#
using Printf, DataFrames, Plots
using FixedPointNumbers, ColorTypes # for RGB
function colormap(codelist; color=repeat([:red], length(codelist)))
function map0(data; color)
cont = (data.lon .!= 0) .| (data.lat .!= 0)
allowmissing!(data)
data[.!cont, 1] .= missing
data[.!cont, 2] .= missing
p = plot(data.lon, data.lat, linecolor=:black, showaxis=false,
ticks=false, grid=false, aspect_ratio=1, label="")
start = 1
k = 0
for i = 2:size(data, 1)
if cont[i] == false
k += 1
if i-start == 4
plot!(data.lon[start:(i-1)], data.lat[start:(i-1)], label="")
else
plot!(data.lon[start:(i-1)], data.lat[start:(i-1)],
seriestype=:shape, fillcolor=color[k], label="")
end
start = i + 1
end
end
display(p)
end
for i in 1:length(codelist)
if codelist[i] in [15, 28, 47]
append!(codelist, -codelist[i])
append!(color, [color[i]])
end
end
codelist[codelist .== -15] .= 48
codelist[codelist .== -28] .= 49
codelist[codelist .== -47] .= 50
lon = []
lat = []
for i in codelist
fn = @sprintf "jpn/%02i" i
xy = parse.(Int, split(readline(fn)));
append!(lon, vcat(xy[1:2:end], 0))
append!(lat, vcat(xy[2:2:end], 0))
end
minlon = minimum(lon[lon .!= 0])
maxlat = maximum(lat[lat .!= 0])
lon = map(x -> x == 0 ? 0 : x - minlon + 1, lon)
lat = map(x -> x == 0 ? 0 : maxlat - x + 1, lat)
map0(DataFrame(lon=lon, lat=lat); color)
end
function rgb(cn::Int) # 各色 5 段階
colorset = [
["#ffffff", "#bfbfbf", "#7f7f7f", "#151515", "#000000"], # 灰色1 cn = 1
["#eeeeee", "#bbbbbb", "#999999", "#777777", "#555555"], # 灰色2 cn = 2
["#ee0000", "#bb0000", "#990000", "#770000", "#550000"], # 赤色系 cn = 3
["#00ee00", "#00bb00", "#009900", "#007700", "#005500"], # 緑色系 cn = 4
["#0000ee", "#0000bb", "#000099", "#000077", "#000055"], # 青色系 cn = 5
["#ee00ee", "#bb00bb", "#990099", "#770077", "#550055"], # 紫色系 cn = 6
["#00eeee", "#00bbbb", "#009999", "#007777", "#005555"], # 水色系 cn = 7
["#eeee00", "#bbbb00", "#999900", "#777700", "#555500"]] # 黄色系 cn = 8
[rgb(i) for i in colorset[cn]]
end
function rgb(str::String) # 任意の "#aabbcc"
r, g, b = [parse(Int, str[i:i+1], base=16)/256 for i =2:2:6]
RGB(r, g, b)
end
function colormap1(x; colornumber=8) # モノクロ・デフォルト色で既定の段階で描画
colornumber in 1:8 || error("color.no は,1〜8 の整数でなければなりません")
divideat = [9, 19, 28, 38];
xs = sort(x);
divideat2 = (xs[divideat] .+ xs[divideat .+ 1]) ./ 2;
rank = [sum(z .> divideat2) + 1 for z in x];
colormap(collect(1:47), color=rgb(colornumber)[rank])
end
function colormap2(x, t; colornumber=8) # モノクロ・デフォルト色で任意の段階で色分け
length(t) == 4 || error("t = $t は,長さ4のベクトルでなければなりません")
colornumber in 1:8 || error("color.no = $colornumber は,1〜8 の整数でなければなりません")
rank = [sum(z .>= t) + 1 for z in x];
colormap(collect(1:47), color=rgb(colornumber)[rank])
end
function colormap3(x, t, colorset) # 任意の段階数,任意の色で塗り分け
length(t)+1 == length(colorset) || error("t の長さ ($(length(t))) は colorset の長さ ($(length(colorset))) より 1 だけ小さくなければならない")
rank = [sum(z .>= t) + 1 for z in x];
colormap(collect(1:47); color=colorset[rank])
end
function colormap4(prefs, marks, color, others = :white) # 複数の県の一部だけ塗り分け
colormap(prefs, color=map(x -> x in marks ? color : others, prefs))
end
# colormap
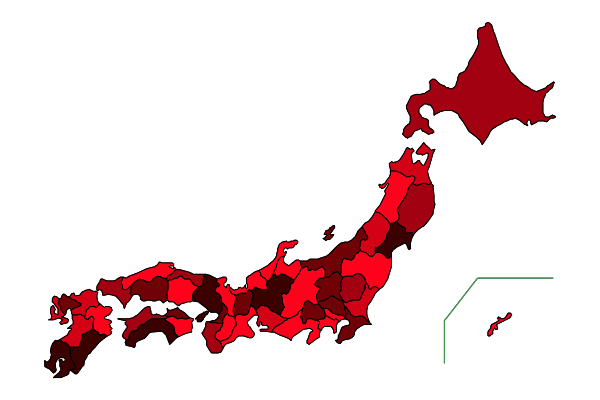
color = [RGB(i, 0, 0) for i = 0.2:1/5:1];
colormap(collect(1:47), color=rand(color, 47));
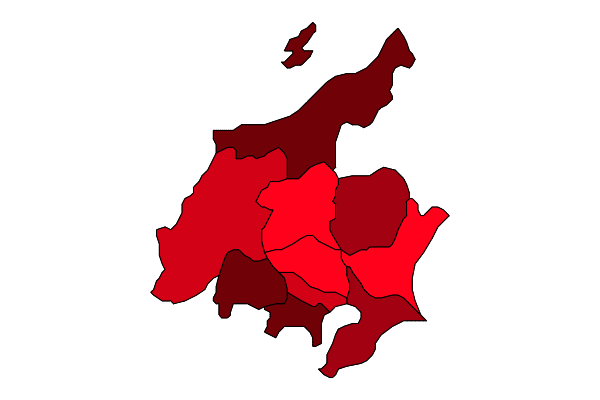
codelist = vcat(collect(8:15), 19, 20);
colormap(codelist, color=rand(color, length(codelist)))
# colormap1
x = rand(47)
colormap1(x; colornumber=8)
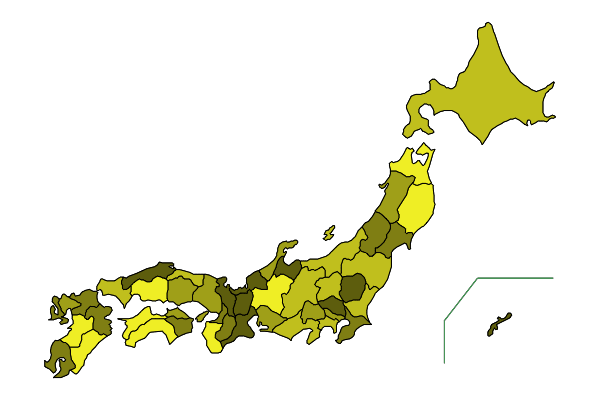
# colormap2
t = [0.2, 0.5, 0.8, 1] # 任意の段階
colormap2(x, t, colornumber=4)
# colormap3
funky = [:red, :blue, :yellow, :green, :cyan, :magenta, :black]
t = collect(0.1:0.15:0.85)
colormap3(rand(47), t, funky)
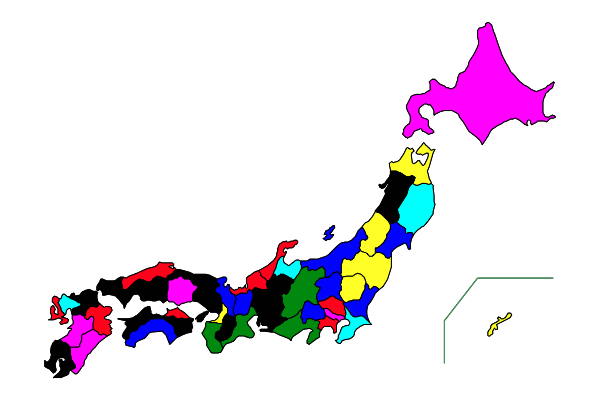
# colormap4
prefs = vcat(collect(7:15), 19, 20)
marks = [10, 13]
colormap4(prefs, marks, RGB(0.4, 0.6, 0.8), RGB(0.85, 0.93, 0.95))