








まず,驚くところは,Julia の k-means 関数では,データを ncol x nrow であたえるところ。
よく,help も読まないでやると,戸惑う所の騒ぎではない。
ということで,データを transpose して与えないといけない。
これくらいのこと,ユーザに強いるなよ!!
using RDatasets
iris = dataset("datasets", "iris");
a = Matrix(iris[!, 1:2]);
using Clustering, Plots
ncluster = 3;
R = kmeans(a', 3; maxiter=200) # データを transpose して与えること!!! a' よりは,わかりやすく transpose(a) とする
a = assignments(R);
c = counts(R);
M = R.centers;
println(a) # 結果として,どこに分類されたか
M[1,:] # 各クラスターの平均値
図に描いてみよう
repeateach(x, n) = vec([j for i = 1:n, j in x])
colors = repeateach([:brown, :blue, :red], 50);
p1 = scatter(iris[!, 1], iris[!,2], markercolor=colors, tick_direction=:out, label="");
p1 = scatter!(M[1,:], M[2,:], markershape=:star6, markersize=10, markercolor=:cyan, label="")
display(p1)
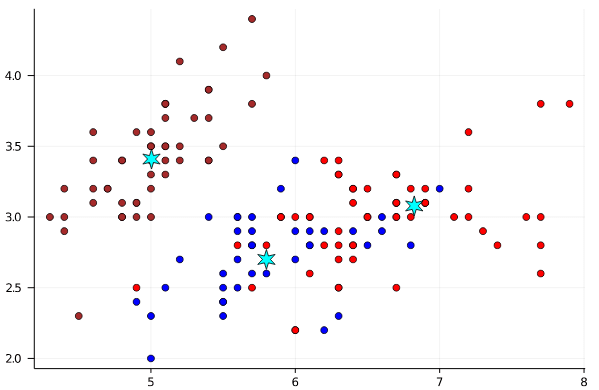
分類結果
using FreqTables
freqtable(iris[!, 5], a)
Out[7]:
R ではどんな風にやるのかな??
using RCall
R"""
a = kmeans(iris[1:2], 3)
plot(iris[,1], iris[,2], col=rep(1:3, each=50))
points(a$centers, pch=17, col=c(1,3,2), cex=2)
"""
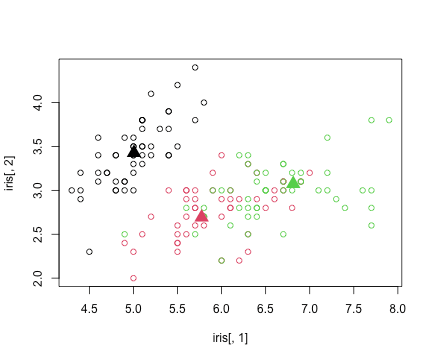
RObject{IntSxp}
a$cluster
iris[, 5] 1 2 3
setosa 50 0 0
versicolor 0 38 12
virginica 0 15 35










