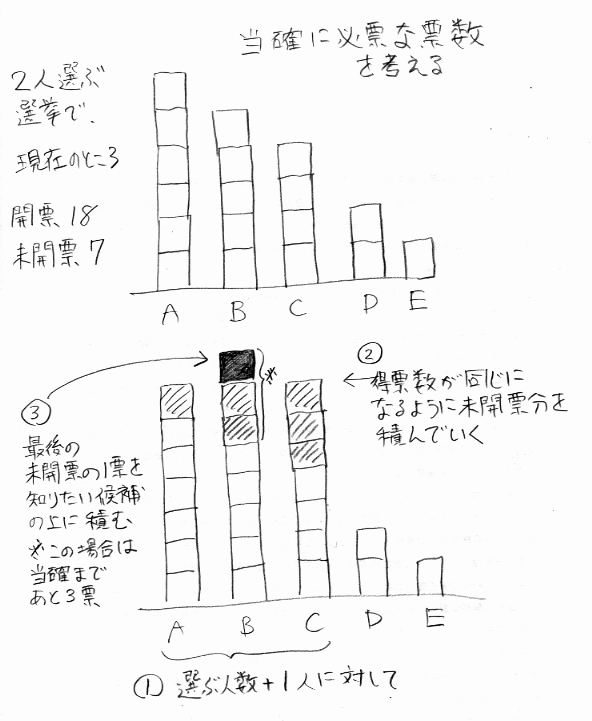
年をとると時間が経つのが速く感じられるという。色々な心裡的説明がなされ
ているが、いま一つ私も説明を試みてみたい。
学校に通っていた頃は何事も学年に結びつけて覚えている。たとえば、三年に
一回開かれる学芸会が開かれるとして、前の学芸会のことを「二年生のときに
あった学芸会」と記憶している。だから、五年生のときに学芸会がある年が回っ
てきて、「もう三年も経ってしまったのか」とは思わない。
一方、二年に一回の車検があるとする。前の車検のことを、「○○年にあった
車検」と記憶している人はほとんどおらず、たんに「前の車検」ということで
記憶の隅にしまってある。そして、二年経って新たに車検の時期が来たときに
なってはじめて、タイムスタンプのない過去の車検の記憶が呼び出される。タ
イムスタンプがないから、それがいつの記憶だったのか、実感としてわからな
い。この実感のなさが「もう車検の時期か」という気持ちになる。
なにも○○年の車検というふうに年号と結びついていなくても、「沖縄に旅行
した年の車検」とか「長男が小学校に上がった年の車検」とかいうふうに他の
記憶とリンクした形で記憶していれば、それでタイムスタンプの役目を十分果
たす。ところが、年をとると、どういう形にせよタイムスタンプのない記憶が
増えていく。仮にタイムスタンプが押されているものであっても、「○○氏が
首相をしていたとき」などと、その精度が低くなっていく。
タイムスタンプのない記憶が増え、また、互いに時間的なリンクを持たない記
憶が増えていくにつれて、われわれが任意の記憶を呼び起こしたときに感じら
れる、そのイベントからの経過時間が実感できなくなる。
もしこの説明が正しいとすると、時間の流れをゆっくり感じるようになるため
にするべきことは、はっきりしている。つまり、イベント間の時間関係を正確
に把握すればよいのである。
ているが、いま一つ私も説明を試みてみたい。
学校に通っていた頃は何事も学年に結びつけて覚えている。たとえば、三年に
一回開かれる学芸会が開かれるとして、前の学芸会のことを「二年生のときに
あった学芸会」と記憶している。だから、五年生のときに学芸会がある年が回っ
てきて、「もう三年も経ってしまったのか」とは思わない。
一方、二年に一回の車検があるとする。前の車検のことを、「○○年にあった
車検」と記憶している人はほとんどおらず、たんに「前の車検」ということで
記憶の隅にしまってある。そして、二年経って新たに車検の時期が来たときに
なってはじめて、タイムスタンプのない過去の車検の記憶が呼び出される。タ
イムスタンプがないから、それがいつの記憶だったのか、実感としてわからな
い。この実感のなさが「もう車検の時期か」という気持ちになる。
なにも○○年の車検というふうに年号と結びついていなくても、「沖縄に旅行
した年の車検」とか「長男が小学校に上がった年の車検」とかいうふうに他の
記憶とリンクした形で記憶していれば、それでタイムスタンプの役目を十分果
たす。ところが、年をとると、どういう形にせよタイムスタンプのない記憶が
増えていく。仮にタイムスタンプが押されているものであっても、「○○氏が
首相をしていたとき」などと、その精度が低くなっていく。
タイムスタンプのない記憶が増え、また、互いに時間的なリンクを持たない記
憶が増えていくにつれて、われわれが任意の記憶を呼び起こしたときに感じら
れる、そのイベントからの経過時間が実感できなくなる。
もしこの説明が正しいとすると、時間の流れをゆっくり感じるようになるため
にするべきことは、はっきりしている。つまり、イベント間の時間関係を正確
に把握すればよいのである。