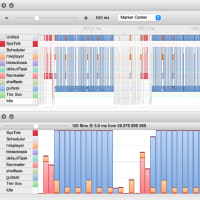
前回の記事では、CMSIS-DSPの例としてあげられているグライコを実際に走らせてみて、実時間でのオーディオ信号処理をやってみました。サンプルのとおりだと、およそ35MHzのクロック速度が必要なことがわかりましたが、もともとのプログラムはCortex-M4, M3, M0のいずれでも動作するようになっています。Cortex-M4/M3であれば、Biquad IIRフィルター処理には高速版のAPIを使うことができるので、こちらを使うようにプログラムを変更してみました。具体的には、arm_biquad_cascade_df1_q31( ) の代わりに arm_biquad_cascade_df1_fast_q31( ) を使うように変更するだけです。こちらを使うと、演算精度は犠牲になるものの、実行速度は速くなるハズだったのですが。。。
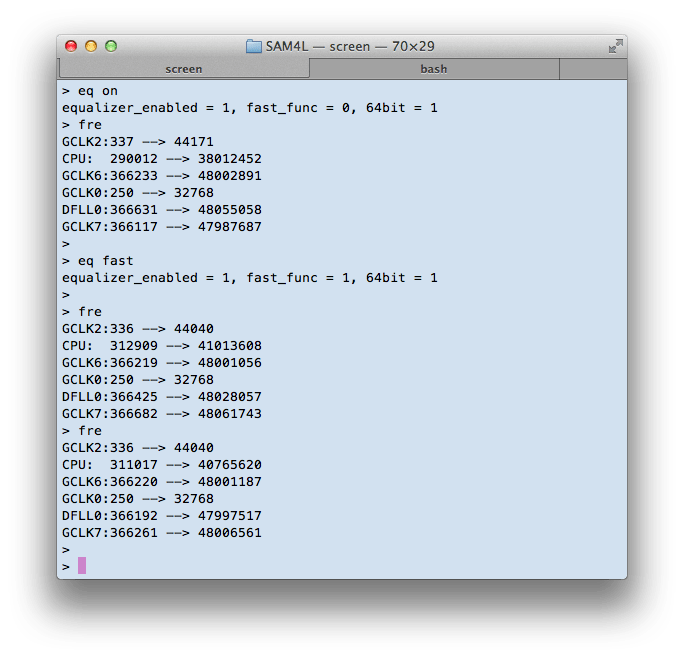
Fast版を使うと40MHz越えです。予想に反してfast版のAPIを使うと遅くなっちゃいました。どうして? 8ビットとか16ビットの演算であれば、Cortex-M4のSIMD命令を使って複数の乗算や加算を並行実行できますが、32ビットだとその恩恵を受けることができないからでしょうか?でも、これは早くならない理由にはなっても、遅くなる理由は別にあるはずですね。生成されたコードをobjdumpして調べれば原因調査可能ですが、Cortex-M4のアセンブラ勉強しなくてはならないので、そこまでの深追いは断念。せっかくなので、別の場所をいじってみます。
グライコのサンプルは、5つのバンドを5つのフィルターを通して処理していますが、低域の2つのフィルタにおいてはノイズを軽減するために32x64ビットの演算をするarm_biquad_cas_df1_32x64_q31を使用しています。通常版が内部的には64ビットでの演算をおこなっても状態変数には32ビットしか保存しないのに対して、こちらのAPIでは状態変数も64ビットで保存しているので32x64ビットの乗算が必要となり、時間がかかります。この部分を通常版のarm_biquad_cascade_df1_q31( ) に置き換えれば、演算精度が失われ音質は悪くなるでしょうが、時間は短縮できるはずです。
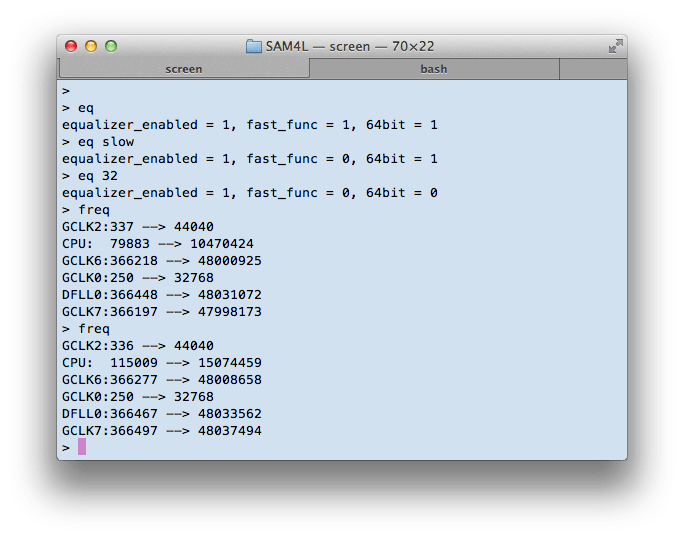
Fast版を使うのはやめて、32x32ビット演算に変更。効果てきめん。10MHzから15MHz程度で間に合うようになりました。これならステレオ処理もできるじゃんと喜びましたが、副作用も顕著。最低域の100Hz以下のバンドはゲインを付けると全く使い物にならなくなってしまいました。量子化誤差の影響でフィルタ動作が安定領域から逸脱したということかな。うーん、IIRフィルタは難しい。
Fast版を使うと40MHz越えです。予想に反してfast版のAPIを使うと遅くなっちゃいました。どうして? 8ビットとか16ビットの演算であれば、Cortex-M4のSIMD命令を使って複数の乗算や加算を並行実行できますが、32ビットだとその恩恵を受けることができないからでしょうか?でも、これは早くならない理由にはなっても、遅くなる理由は別にあるはずですね。生成されたコードをobjdumpして調べれば原因調査可能ですが、Cortex-M4のアセンブラ勉強しなくてはならないので、そこまでの深追いは断念。せっかくなので、別の場所をいじってみます。
グライコのサンプルは、5つのバンドを5つのフィルターを通して処理していますが、低域の2つのフィルタにおいてはノイズを軽減するために32x64ビットの演算をするarm_biquad_cas_df1_32x64_q31を使用しています。通常版が内部的には64ビットでの演算をおこなっても状態変数には32ビットしか保存しないのに対して、こちらのAPIでは状態変数も64ビットで保存しているので32x64ビットの乗算が必要となり、時間がかかります。この部分を通常版のarm_biquad_cascade_df1_q31( ) に置き換えれば、演算精度が失われ音質は悪くなるでしょうが、時間は短縮できるはずです。
Fast版を使うのはやめて、32x32ビット演算に変更。効果てきめん。10MHzから15MHz程度で間に合うようになりました。これならステレオ処理もできるじゃんと喜びましたが、副作用も顕著。最低域の100Hz以下のバンドはゲインを付けると全く使い物にならなくなってしまいました。量子化誤差の影響でフィルタ動作が安定領域から逸脱したということかな。うーん、IIRフィルタは難しい。