








今度は NY(264K点/734K枝) に対して APSP(全対全最短路問題) を計算してみた。
環境はこれまでと同様 Nehalem-EP と Istanbul4 である。
Nehalem-EP : Intel(R) Xeon(R) CPU X5550 @ 2.67GHz (4cores x 2sockets)
Istanbul4 : Six-Core AMD Opteron(tm) Processor 8439 SE (6cores x 4sockets)
今回測定した実装は以下の通りである。いずれもコア数=並列数で計算している。
naive : 一般的な pthread 並列
huge/numactl : numactl による affinity 設定とHugePage(LargePage) によるメモリ確保
affinity : sched_setaffinity() による affinity 設定
hugepage/affinity : hugepage かつ affinity
やはり Istanbul は実装に応じた性能差が大きく、Nehalem-EP は性能差が少ない。
コア数は Nehalem-EP : Istanbul = 8 : 24 = 1 : 3 だが、
実行時間は Nehalem-EP : Istanbul = 1298.830 : 600.991 = 2.1611 : 1 となっており、
コアあたりの性能は Nehalem-EP の方が高い。
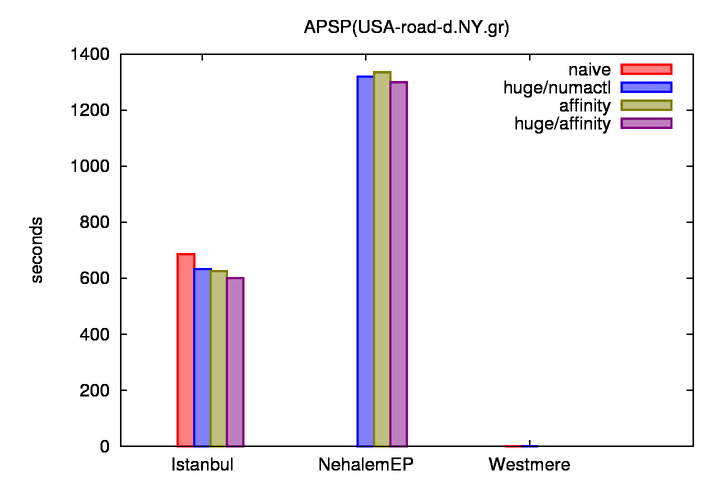
スループットとしての TEPS を算出すると、 Istanbul では 322.7969 ME/s、Nehalem-EP では、149.3604 ME/s となる。

画像には westmere が書いてあるのはご愛嬌ということで。
環境はこれまでと同様 Nehalem-EP と Istanbul4 である。
Nehalem-EP : Intel(R) Xeon(R) CPU X5550 @ 2.67GHz (4cores x 2sockets)
Istanbul4 : Six-Core AMD Opteron(tm) Processor 8439 SE (6cores x 4sockets)
今回測定した実装は以下の通りである。いずれもコア数=並列数で計算している。
naive : 一般的な pthread 並列
huge/numactl : numactl による affinity 設定とHugePage(LargePage) によるメモリ確保
affinity : sched_setaffinity() による affinity 設定
hugepage/affinity : hugepage かつ affinity
やはり Istanbul は実装に応じた性能差が大きく、Nehalem-EP は性能差が少ない。
コア数は Nehalem-EP : Istanbul = 8 : 24 = 1 : 3 だが、
実行時間は Nehalem-EP : Istanbul = 1298.830 : 600.991 = 2.1611 : 1 となっており、
コアあたりの性能は Nehalem-EP の方が高い。
スループットとしての TEPS を算出すると、 Istanbul では 322.7969 ME/s、Nehalem-EP では、149.3604 ME/s となる。
画像には westmere が書いてあるのはご愛嬌ということで。









