








これまでダイクストラ法の並列化には次のようにグラフデータは共通とし各コア直下に作業領域を確保していた。
しかしながら NUMA アーキテクチャでは図に書いてあるとおり、グラフデータが置かれている NUMA-Node 付近に非常に負荷がかかってしまい、性能低下の原因となってしまう。
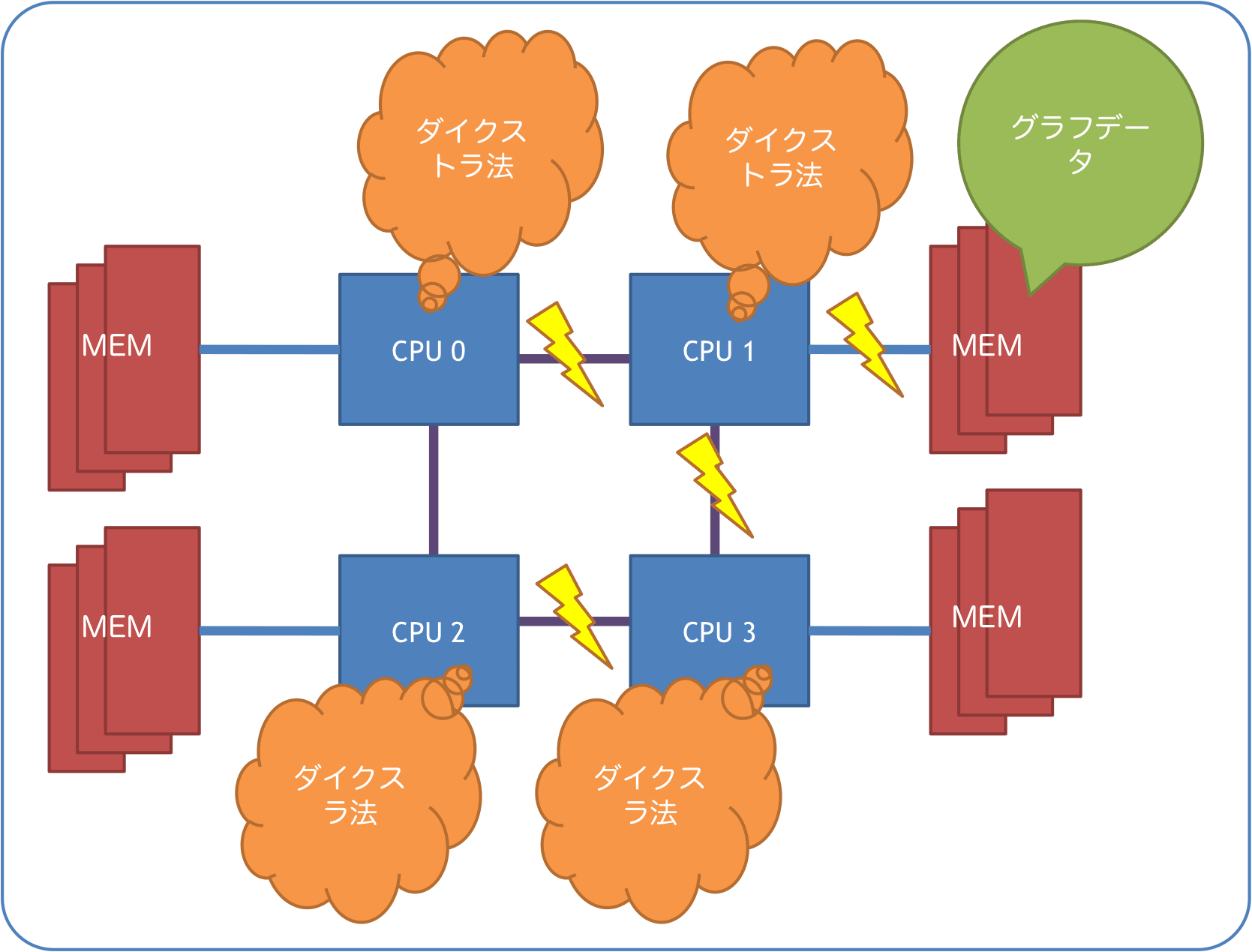
一方理想的なのは次のように完全に分離してしまうことである。ただ実現するためには、MPI を使用するか getmempolicy などで固定する必要があるが、どちらも簡単には実現が難しい。

まずは効果があるかを確かめたいので、次の操作をほぼ手動(script 化はしている)で試してみた。
1. クエリファイルをソケット数で分割する
2. 分割したクエリファイル毎にプロセスを立ち上げる。その際 numactl を用いソケットに固定する。
3. 各プロセスはコア数分のスレッドを立ち上げる(正確にはコア数-1個のスレッドを新たに立ち上げる)
最も時間のかかったプロセスを実行時間とする。
しかしながら NUMA アーキテクチャでは図に書いてあるとおり、グラフデータが置かれている NUMA-Node 付近に非常に負荷がかかってしまい、性能低下の原因となってしまう。
一方理想的なのは次のように完全に分離してしまうことである。ただ実現するためには、MPI を使用するか getmempolicy などで固定する必要があるが、どちらも簡単には実現が難しい。
まずは効果があるかを確かめたいので、次の操作をほぼ手動(script 化はしている)で試してみた。
1. クエリファイルをソケット数で分割する
2. 分割したクエリファイル毎にプロセスを立ち上げる。その際 numactl を用いソケットに固定する。
3. 各プロセスはコア数分のスレッドを立ち上げる(正確にはコア数-1個のスレッドを新たに立ち上げる)
最も時間のかかったプロセスを実行時間とする。