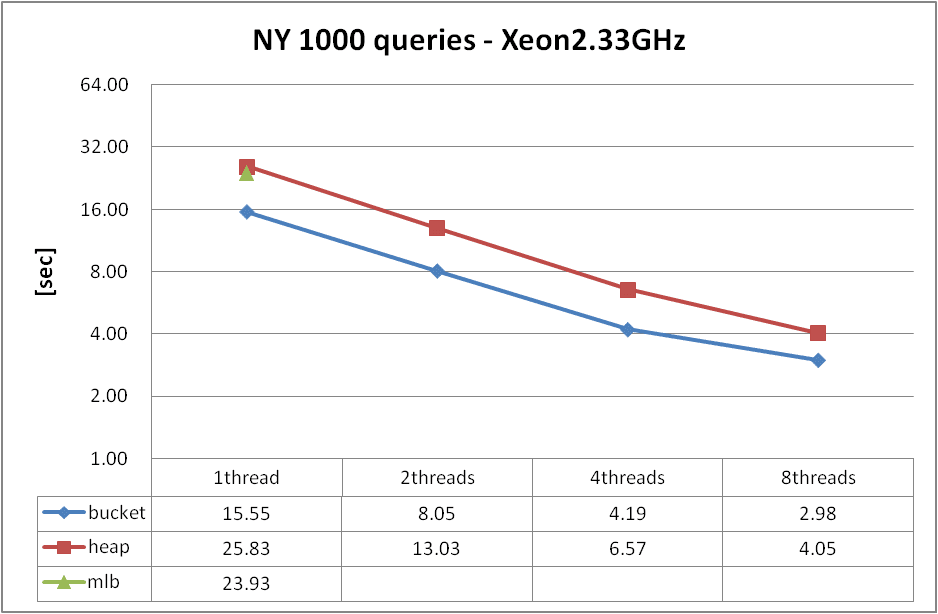
ソースコードをいろいろいじっているうちに、ヒープ版の実行時間が短くなってきたので、ここら辺で全米グラフに対しての1対1最短路の実行時間を測定してみた。
実行環境は以下の通りになっている。すべて1スレッドで実行しており、ファイル読み込みを含めての実行時間となっている。
CPU : Xeon(R) E5345 2.33GHz (4core x 2)
Mem : 16 GB
OS : CentOS 5.1 (64bit)
バケット 2548 秒
ヒープ 3920 秒
マルチレベルバケット 4088 秒
[binary heap] で [malti-level bucket] を抜くというのが1つの目標だったので、とりあえず達成する事が出来た。[binary heap] は特にメモリ要求量が少ないため、低スペックな組み込み系ハードで実行する際に必要になってくるといえる。
実行環境は以下の通りになっている。すべて1スレッドで実行しており、ファイル読み込みを含めての実行時間となっている。
CPU : Xeon(R) E5345 2.33GHz (4core x 2)
Mem : 16 GB
OS : CentOS 5.1 (64bit)
バケット 2548 秒
ヒープ 3920 秒
マルチレベルバケット 4088 秒
[binary heap] で [malti-level bucket] を抜くというのが1つの目標だったので、とりあえず達成する事が出来た。[binary heap] は特にメモリ要求量が少ないため、低スペックな組み込み系ハードで実行する際に必要になってくるといえる。