前回の方法では、malloc で確保した領域が全て HugeTLB の上に乗ってしまうので、mmap を用いて自作のルーチンを作った方が良いかもしれない。正直、最短路ソルバーで malloc するものは、かなり大きな配列(構造体の配列も)であるのでこのままでもよいが、小さなグラフの場合ではかなり遅くなってしまうかもしれない。
やはり自作で作った方がいいとは思うのだが、ソースに手を加える前に実験を行ってみた。
実験環境は
CPU : Core2Duo E8200 3.2 GHz (2.66 GHz からクロックアップ)
OS : CentOS 5.1 64bit
gcc : gcc 4.3
HugeTLB : 1GB (2048 KB x 512)
クエリファイルはこれを用いている。
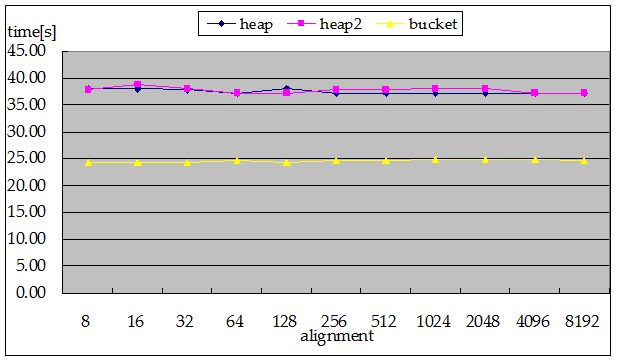
0. multi-bucket(by goldberg)
20.13[s]
1. bucket
14.55[s]
2. bucket with libhugetlbfs
12.07[s] (x 1.21)
3. heap
21.39[s]
4. heap with libhugetlbfs
18.20[s] (x 1.18)
と、1.2 倍ほどに高速化されている。ページサイズが 4KB → 2MB と大きくなり、TLB ミスが 1/512 となったためであろうか。こちらも OProfile を用いて測定してみようと思う。
やはり自作で作った方がいいとは思うのだが、ソースに手を加える前に実験を行ってみた。
実験環境は
CPU : Core2Duo E8200 3.2 GHz (2.66 GHz からクロックアップ)
OS : CentOS 5.1 64bit
gcc : gcc 4.3
HugeTLB : 1GB (2048 KB x 512)
クエリファイルはこれを用いている。
0. multi-bucket(by goldberg)
20.13[s]
1. bucket
14.55[s]
2. bucket with libhugetlbfs
12.07[s] (x 1.21)
3. heap
21.39[s]
4. heap with libhugetlbfs
18.20[s] (x 1.18)
と、1.2 倍ほどに高速化されている。ページサイズが 4KB → 2MB と大きくなり、TLB ミスが 1/512 となったためであろうか。こちらも OProfile を用いて測定してみようと思う。