








前回、EasyOCRを利用できる環境を作ったので今度はマイコン雑誌のリストを読み取るプログラムを作成します。プログラムにはPythonを使います。EasyOCRをPythonから利用するのは数行のプログラムで書けるので簡単ですが、ネットによくあるコマンドラインからの利用では使い勝手が悪いので、tkinterを使ったGUIプログラムにしようと思います。
また、以前OCR検証に使ったWindows標準のOCRやGoogleのOCRと違って、EasyOCRは画像の読み取り動作をカスタマイズできるのでその辺りも利用していきます。
それではプログラムを作成していきます。このプログラムでは前に検証したようにBASICリストとマシン語ダンプリストを読み取ってテキストファイルを出力します。このとき誤変換を少なくするため読み取り対象の文字を制限します。また、テキスト出力時に文字の順番が入れ替わることがあるのでこれも修正します。
最終的に作成したプログラムはこちらです。
easyocr_test.pyw (右上のダウンロードアイコンをクリックしてください)
GUIプログラムですので、Pythonが正しくインストールされていればWindowsのエクスプローラーからダブルクリックで起動できます。ただし、このプログラムは日本語の入っていないパスに置くようにしてください。Pythonは日本語を扱えますが、EasyOCRのエンジンは読み取りたい画像ファイルのパスに日本語が入っているとうまく動作してくれませんでした。
プログラムを起動すると次のようなウィンドウが開きます。
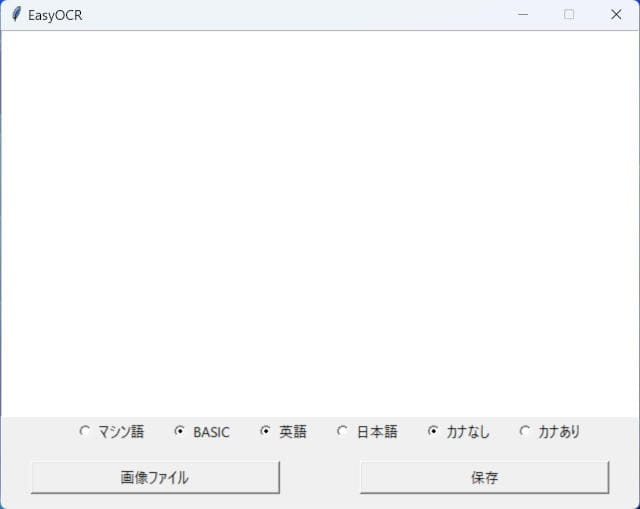
ウィンドウ中央のテキストボックスには読み取ったプログラムリストが表示されます。下部に6個のラジオボタンがありますが、これは2個ずつ3組になっています。左から"マシン語"と"BASIC"、"英語""日本語"、"カナなし""カナあり"がそれぞれ組になっています。
"マシン語"と"BASIC"では読み取りリストの種類を指定します。"マシン語"を選択すると右側の"英語"以降の設定は無視されます。"BASIC"を選ぶと右側の設定が有効です。
"英語"と"日本語"はEasyOCRの言語設定を英語だけにするか英語+日本語にするかの選択に使います。
"カナなし""カナあり"はEasyOCRで検出する文字をASCIIの英数字だけにするか、ASCII+カナ文字にするかの選択に使います。ただし"英語"を選択して"カナあり"に設定してもカナ文字は認識されないので、この組み合わせは意味がありません。
"マシン語"を選択したときはEasyOCRの言語設定は"英語"で、読み取る文字は数字とA~F(とSumの文字)とダンプリスに使われる区切り記号だけに限定してあります。
ラジオボタンで設定したら、"画像ファイル"ボタンでプログラムリストの画像を読み込みます。するとEasyOCRが文字を読み取りを開始し、読み取り終わったらテキストボックスに表示します。
"保存"ボタンを押すと、読み込んだ画像ファイルと同じファイル名で拡張子を.txtにしたファイルにテキストボックスの内容を出力します。
それでは読み取りテストをしてみましょう。
まず言語の設定によって認識精度がどうなるのか見てみます。以下のようなカナ文字の入ったBASICプログラムを読み取ってみましょう。

↓
日本語・カナあり
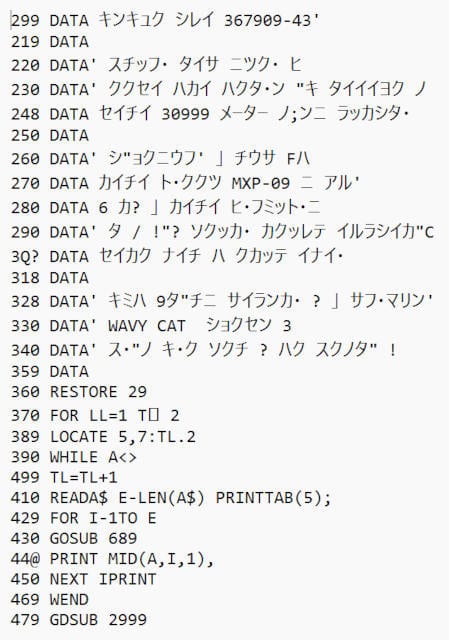
英語・カナなし

英語+日本語の設定でのカナ文字の読み取りは誤変換が結構あって今一つですね。そのうえ英数字の誤変換も結構あります。試しにフォントの異なる別のBASICリストを読み取ってみたらカナ文字は上記よりも正確に読み取れましたが、英数字の誤変換が大量に発生していました。日本語の設定はBASICリスト読み取りには向いていないようです。
英語だけ認識する場合は、当然カナは文字化けしますが英数字は割と正確に読み取ってくれています。誤変換もありますが、レイアウトの乱れは少ないですね。今回作成したPythonプログラムにもう少し手をかければBASICリストのインデントも再現できたのですが、面倒なので手を抜きました。
試しにGoogleのOCRで読み取ってみるとこうなりました。
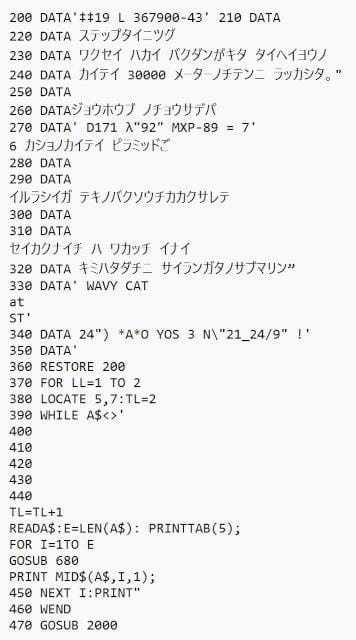
カナ文字含め文字の認識はEasyOCRより勝っていますが、レイアウトが崩れています。
次回は、前にProgramListOCRやGoogleOCRで試したプログラムリストを読み取らせるとどうなるのか確認したいと思います。









※コメント投稿者のブログIDはブログ作成者のみに通知されます