








せっかくなので前回に引き続き、EasyOCRを使ってマイコン雑誌のプログラムリストを読み取ってみることにしました。
EasyOCRはPyTorchというPythonベースのディープラーニング・ライブラリを利用しています。そのためEasyOCRを動作させるためにはPythonをインストールする必要があります。また、NVIDIAのGPUを使った並列演算処理を行うためのCUDAも利用します。したがってEasyOCRを使うための環境構築はちょっと面倒です。
Linuxならば比較的簡単に構築できるのですが、前回までWindows11環境で検証してきたので今回も頑張ってWindowsで構築してみます。
今使用しているPCにはNVIDIAのビデオカードが搭載されているので、まずはCUDAのインストールから始めます。ただしPyTorchはCUDAなしでも動作させることはできるので、必要ないと思うならこの作業は行わなくてもかまいません。
それではまずビデオカードのドライバをアップデートしておきます。
NVIDIAのサイトから最新のドライバをダウンロードしてインストールしました。
続いてCUDAのインストールです。NVIDIAのここによると今使っているNVIDIA TuringアーキテクチャのビデオカードはCUDA12.0に対応しているようなので、リンク先から最新のCUDA Toolkit 12.1.0をダウンロードしてインストールしてみました。
PyTorchはCUDA11.8までの対応のようなのですが、どこかのサイトにCUDA12.0でも動いたという記事があったのでたぶん大丈夫でしょう。
特に必要なことではないのですが、せっかくCUDAをインストールしたのでサンプルプログラムを動かして動作確認してみます。サンプルプログラムはgithubにあるのでgitのインストールとコンパイルするためのVisual Studioが必要です。まあ、gitは無くてもサンプルプログラムはダウンロードできるのですが、今後使うこともあるかもしれないのでインストールしておくことにしました。
gitはこちらのサイトを参考にインストールしました。Visual Studioの方は2022をすでにインストールしていましたので何もする必要はありませんでした。
gitのインストールが終わったらコマンドプロンプトでつぎのコマンドを入力します。
git clone https://github.com/NVIDIA/cuda-samples.git
クローンしたcuda-samplesフォルダの中にあるSamples_VS2022.slnをVisual Studio 2022で開きます。(2017と2019もあります)
グラフィカルなサンプルを動かしたいので、ソリューションエクスプローラーから"4_CUDA_Libraries"の下の"oceanFFT"を右クリックして「デバッグ」→「新しいインスタンスの開始」でコンパイルします。すると水面が波打つアニメーションのサンプルを見ることができます。
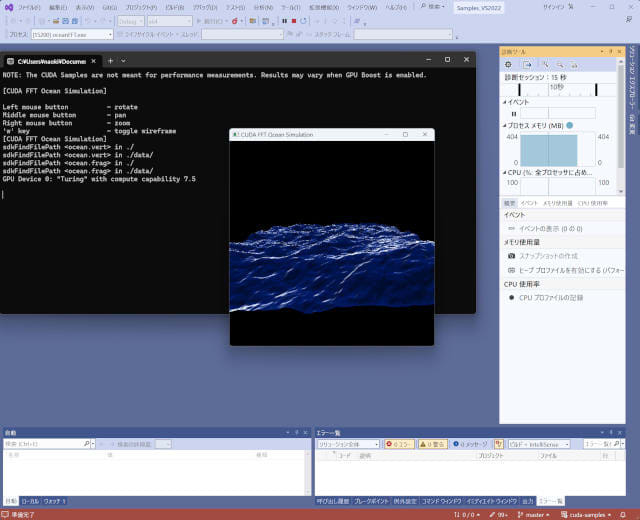
CUDAについてはこれで動作確認できました。
次はPythonのインストールです。カスタムインストールする場合はpipを外さないようにします。
Pythonのインストールが終わったらPyTorch(パイトーチ)のインストールです。こちらのサイトでインストール環境を指定します。

今回CUDAは12.1.0-531.14というバージョンをインストールしてしまいましたが、ここではCUDA 11.8を選んでおきます。
CUDAを使用しない場合は、"Compute Platform"の項目で"CPU"を選択します。
項目すべてを選択し終えたら、一番下にpipのコマンドが表示されますのでコマンドプロンプトから入力するとPyTorchがインストールされます。
ここの下の方ににある"Verification"の欄を参考に、PyTorchの動作確認とCUDAが有効になっているかどうかの確認をしました。
これでやっとEasyOCRをインストールすることができます。インストールはEasyOCRのサイトにあるように、コマンドプロンプトから、
pip install easyocr
と入力するだけです。ソースから最新の開発版をインストールする場合はこのサイトに記述されているコマンドではエラーになるので、
pip install git+https://github.com/JaidedAI/EasyOCR.git
と入力します。
このあとEasyOCRを利用するためにはPythonでプログラムを組む必要があるのですが、ここまでかなり手間がかかってしまったのでまた後で作業します。









※コメント投稿者のブログIDはブログ作成者のみに通知されます