









引き続いて、Generative Deep Learning [1] の 4章 Wasserstein GAN with Gradient Penalty (WGAN-GP)のサンプル (wgan_gp.ipynb)[2]を試し、学習の安定性が向上していることは見て取れた。一方で、Gradient Penalty のためにInterpolated imageを使うことによってアーティファクトが発生していた。実用的には単純なinterpolationではなくもっと工夫が必要なことが見て取れた。
このサンプルは、VRAM 6GBのRTX A2000では メモリ不足で実行できなかったが、GPU無し用のdocker imageを使いCPUのみを使って実行した。
このサンプルでは、下記のような64x64のカラー画像の画像セットで学習する。

学習は、1epochあたり判別機の学習をCRITIC_STEPS 回 行って 200 epoch 行う。
まずは、サンプルそのままに CRITIC_STEPS = 3 で実行。
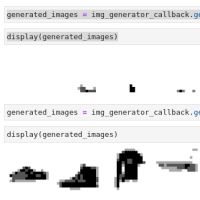
その学習の進捗を50 epochごとに示すと、
1/200
.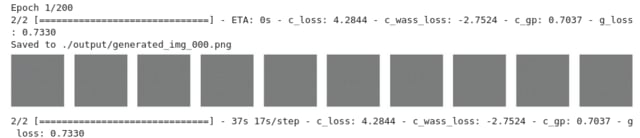
50/200

100/200

150/200

199/200

となる。
最終的に生成される画像の例がこちら。
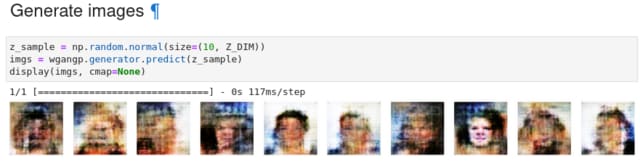
教科書figure 4-14の生成例と比べるといまいち。WGAN-GPの学習の安定性を見るために学習と生成を3回行い、その結果を並べてみるとこの通りで、DCGANを試した時と比べるとずっと学習が安定している。しかし、教科書にあるほど良い結果にはなってない。あれは良い画像だけを選んだものかな?


ちなみに、学習にかかった時間は約120分。 マシンは、メモリが16GBでCPUが Core i5 10600 (3.3GHz) 6 コア 12 Thread.
結果がいまいちに思えたので、CRITIC_STEPSを変えて試してみた。CRITIC_STEPSが 2, 3, 5, 7 で最終的な生成画像を並べてみるとこうなる。この結果で言うとサンプルのCRITIC_STEPSはちょっと少なかったかな。ただ回数を増やせば学習の所要時間も増して、それに見合うほどの画質向上が得られるかというところがある。
CRITIC_STEPS=2 使用時間 85分

CRITIC_STEPS=3 所要時間 118分
CRITIIC_STEPS=5 所要時間 186分

CRITIC_STEPS=7 所要時間 253分
下記は生成された画像の一つだが、二重写しのように見える。思うに、Gradient Penalty のためにオリジナルと生成物の二つをミックスしてほどほどの評価点の物として学習させているため、二重写しもそれなりに受け入れられる画像として学習してしまっているのかと推測した。

[1] Generative Deep Learning, 2nd Edition by David Foster, Released May 2023, Publisher: O'Reilly Media, Inc. ISBN: 9781098134181
[2] https://github.com/davidADSP/Generative_Deep_Learning_2nd_Edition
このサンプルは、VRAM 6GBのRTX A2000では メモリ不足で実行できなかったが、GPU無し用のdocker imageを使いCPUのみを使って実行した。
このサンプルでは、下記のような64x64のカラー画像の画像セットで学習する。
学習は、1epochあたり判別機の学習をCRITIC_STEPS 回 行って 200 epoch 行う。
まずは、サンプルそのままに CRITIC_STEPS = 3 で実行。
その学習の進捗を50 epochごとに示すと、
1/200
.
50/200
100/200
150/200
199/200
となる。
最終的に生成される画像の例がこちら。
教科書figure 4-14の生成例と比べるといまいち。WGAN-GPの学習の安定性を見るために学習と生成を3回行い、その結果を並べてみるとこの通りで、DCGANを試した時と比べるとずっと学習が安定している。しかし、教科書にあるほど良い結果にはなってない。あれは良い画像だけを選んだものかな?
ちなみに、学習にかかった時間は約120分。 マシンは、メモリが16GBでCPUが Core i5 10600 (3.3GHz) 6 コア 12 Thread.
結果がいまいちに思えたので、CRITIC_STEPSを変えて試してみた。CRITIC_STEPSが 2, 3, 5, 7 で最終的な生成画像を並べてみるとこうなる。この結果で言うとサンプルのCRITIC_STEPSはちょっと少なかったかな。ただ回数を増やせば学習の所要時間も増して、それに見合うほどの画質向上が得られるかというところがある。
CRITIC_STEPS=2 使用時間 85分
CRITIC_STEPS=3 所要時間 118分
CRITIIC_STEPS=5 所要時間 186分
CRITIC_STEPS=7 所要時間 253分
下記は生成された画像の一つだが、二重写しのように見える。思うに、Gradient Penalty のためにオリジナルと生成物の二つをミックスしてほどほどの評価点の物として学習させているため、二重写しもそれなりに受け入れられる画像として学習してしまっているのかと推測した。
[1] Generative Deep Learning, 2nd Edition by David Foster, Released May 2023, Publisher: O'Reilly Media, Inc. ISBN: 9781098134181
[2] https://github.com/davidADSP/Generative_Deep_Learning_2nd_Edition












※コメント投稿者のブログIDはブログ作成者のみに通知されます