








Generative Deep Learning [1] の 4章 deep convolutional GANのサンプル (dcgan.ipynb)[2]を試してみたところ、DCGANで思うような結果を出すのが難しいと実感できた。
このサンプルでは、下記のようなレゴブロックのモノクロ画像(64x64 dot)を教師データとしてレゴブロックの画像生成を行う。

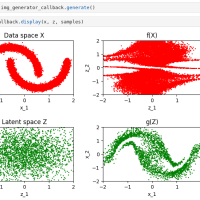
生成器と識別器がだまし/だまされないように互いに切磋琢磨(?)するのが、敵対的生成ネットワーク (Generative adversarial networks: GAN) で、生成器と識別器が畳み込みニューラルネットワークでできたGANが deep convolutional GAN: DCGAN.

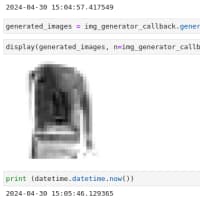
で、上手く訓練ができれば、このように画像が生成できる。出来がいまいちだって? DCGANの規模が小さいからかな。でも、これは4回目にやっとできた上出来の結果なんだ。

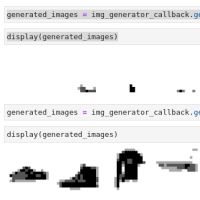
一回目だと、最初は良い感じに訓練できていたものの途中でこんな風に偏ってしまい、

結果としてこういう画像を生成するようになってしまった。

二回目もやっぱり、途中までは良いものの突然このように道を踏み外して、

結果はこれ。

三回目もやっぱり、途中で偏ってしまってこの結果。


識別器が、画像の特定の特徴のみを見て真偽判定するように訓練され、生成器もそれに合わせてその特徴のみを模倣するように訓練されてしまったという事なのだろう。
教科書では、「GANは生成モデルにブレークスルーをもたらしたが、GANはとても訓練が難しい」とさらっと書いてある。が、実際にコードを動かしてみると長々待ってできたのが使えない生成器という繰り返しは結構しんどい。
このサンプルは、VRAM 6GBの RTX A2000で動かしている。一つのstepに二十数秒かかっていてそれを300回繰り返しているから、トータルで1時間以上かかる。それだけ時間をかけて出てきた結果が使えない生成器だとがっかり。
何事もやってみないと分からない。
[1] Generative Deep Learning, 2nd Edition by David Foster, Released May 2023, Publisher: O'Reilly Media, Inc. ISBN: 9781098134181
[2] https://github.com/davidADSP/Generative_Deep_Learning_2nd_Edition
このサンプルでは、下記のようなレゴブロックのモノクロ画像(64x64 dot)を教師データとしてレゴブロックの画像生成を行う。
生成器と識別器がだまし/だまされないように互いに切磋琢磨(?)するのが、敵対的生成ネットワーク (Generative adversarial networks: GAN) で、生成器と識別器が畳み込みニューラルネットワークでできたGANが deep convolutional GAN: DCGAN.
で、上手く訓練ができれば、このように画像が生成できる。出来がいまいちだって? DCGANの規模が小さいからかな。でも、これは4回目にやっとできた上出来の結果なんだ。
一回目だと、最初は良い感じに訓練できていたものの途中でこんな風に偏ってしまい、
結果としてこういう画像を生成するようになってしまった。
二回目もやっぱり、途中までは良いものの突然このように道を踏み外して、
結果はこれ。
三回目もやっぱり、途中で偏ってしまってこの結果。
識別器が、画像の特定の特徴のみを見て真偽判定するように訓練され、生成器もそれに合わせてその特徴のみを模倣するように訓練されてしまったという事なのだろう。
教科書では、「GANは生成モデルにブレークスルーをもたらしたが、GANはとても訓練が難しい」とさらっと書いてある。が、実際にコードを動かしてみると長々待ってできたのが使えない生成器という繰り返しは結構しんどい。
このサンプルは、VRAM 6GBの RTX A2000で動かしている。一つのstepに二十数秒かかっていてそれを300回繰り返しているから、トータルで1時間以上かかる。それだけ時間をかけて出てきた結果が使えない生成器だとがっかり。
何事もやってみないと分からない。
[1] Generative Deep Learning, 2nd Edition by David Foster, Released May 2023, Publisher: O'Reilly Media, Inc. ISBN: 9781098134181
[2] https://github.com/davidADSP/Generative_Deep_Learning_2nd_Edition












※コメント投稿者のブログIDはブログ作成者のみに通知されます