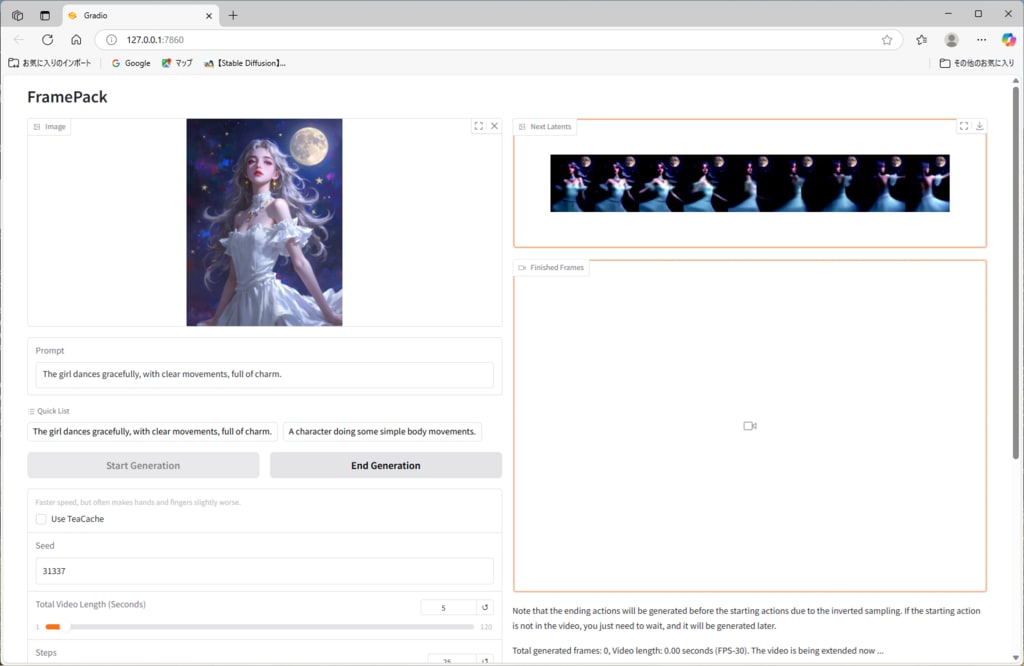
近頃話題の動画生成AIのFramePack。Tesla K80で動かせるかやってみた。
OSはWindows 11なので、githubにはお手軽な One-Click packageがある。ただし、名前(framepack_cu126_torch26.7z)が示すようにCUDA 12.6用である。
Tesla K80はCUDA 11までしかサポートされていない。run.batを走らせると、「RuntimeError: The NVIDIA driver on your system is too old (found version 11040) うんぬん」というエラーで止まってしまう。
そこでpytorchなどをcuda11で用意してみた。python 3.10.16のpython仮想環境を用意し、githubからコードを取得
git clone https://github.com/lllyasviel/FramePack.git
次のようにCUDA 11用のcuDNNやpytorchをインストール
cd FramePack
python -m pip install nvidia-cudnn-cu11
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
pip install -r requirements.txt
これで、demo_gradio.pyを走らせるとWebサーバーが立ち上がり、ブラウザで開くと(http://localhost:7860) GUI画面が開くところまでは進む。

ところが、動画生成を指示すると RuntimeError: cuDNN error: CUDNN_STATUS_NOT_SUPPORTED_ARCH_MISMATCH のエラーで止まってしまう。
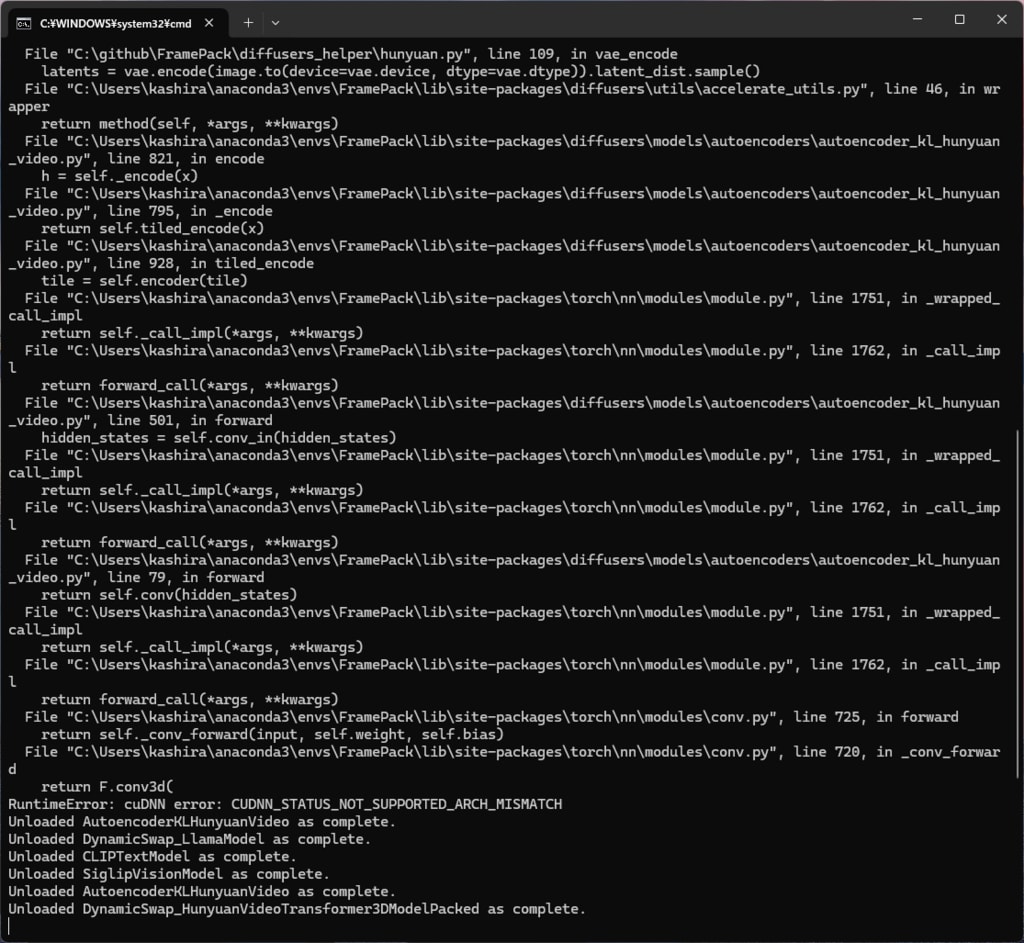
demo_gradio.pyを眺めてみると、dtype=torch.float16 のような記述がある。Keplerは半精度をサポートしていないからなと float16 -> float32 に書き換えて試してみたが、そんなことで通るほど甘くはなかった。
autoencodersのパラメータを変えればスピードやVRAM容量は犠牲になっても動作させられるのではと想像するが、そこまでの技術力がないのであきらめるとする。残念。