








引き続いて、Generative Deep Learning [1] の 8章 Diffusion Models のサンプル (ddm.ipynb)[2]を実行。
このような画像を学習するのに、fitにかかった時間は、RTX A2000 (6GB) をGPUに使って1時間38分ほどかかった。

最初はこんなところだが、

Epoch 8になるとこの様になんとなくそれっぽい画像を生成し、

Epoch 19では、ここまでの画像を生成するようになった。

Epoch 50の学習終了で、最終的にはこのようなリアルな画像が生成できるようになった。

Denoisingで画像が改善されてゆく過程の例がこちら。

また、内挿で連続的に変化する画像を生成した例がこちら。

と、ここまではサンプルをそのまま実行しただけ。
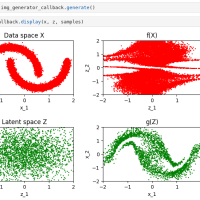
この章では、ノイズを載せるプロセスで、linear, cosine, offset cosine の三つのスケジュールが紹介されていて、前記はoffset cosine での結果。
サンプルコードには、linearやcosineのコードもあるようなので、試してみた。
まずは、linear を試してみた。最初 (Epoch 2)がこんななのは当然として、

それが、最後のEpoch 50でもこんな感じのまま。

TensorBoardでみたepoch_n_loss がこのようなので、まったく学習が働いていないわけではないはずなのだが。

次に、cosine を試してみる。
cosineの場合、Epoch 8になるとこのように何らかの画像らしきもを生成するようになるが、

そこから先は、Epoch 50になっても大して向上していない。

最終的に生成できるようになった画像がこちら


linear や cosineのスケジュールでも結果を出すにはどうすればよいだろうか。このサンプルでは64ステップだが、ステップ数を増やして細かく学習させたらどうだろうか。ということで、BATCH_SIZEを 128にして cosineで試してみたのがこちら。学習に6時間14分を費やして、最終的に生成するようになった画像だが、あまり改善した印象はない。

さてここで、n_lossの視点で比較整理してみるとこうなる。生成する画像では実感できないものの、ステップ数を増やすことでn_lossは確実に改善される。128からもっと増やせばlinearやcosineでもよい結果を出せるのだろうが.. 6GBしかメモリを積んでいないRTX A2000 ではここが限界。CPUのみの方で実行すればもっと増やせるだろうが、実行時間がねぇ...
なお、この図でX軸 (epoch数)は対数表示であることに注意。この感じからすると、10 epochもやれば結果は見えたようなもの、かな。

実際にやってみて思ったのだが、筋のよいアイディアを思いついたとしても、そこから先、実際に良い結果を出せるところまでがまた長いなと。一つすごい成果が出た後にわらわらと後追いが出てくるが、これは、実際にできたのが居るのだから私だってできるはずと頑張った、という事なのかもしれない。
[1] Generative Deep Learning, 2nd Edition by David Foster, Released May 2023, Publisher: O'Reilly Media, Inc. ISBN: 9781098134181
[2] https://github.com/davidADSP/Generative_Deep_Learning_2nd_Edition
[2] https://github.com/davidADSP/Generative_Deep_Learning_2nd_Edition












※コメント投稿者のブログIDはブログ作成者のみに通知されます