








今度はマシン語ダンプリストの読み取りについてテストしてみます。
マシン語のダンプリストには幾つかフォーマットがあります。前回説明したDumpFormater.exeは次の4種類のフォーマットに対応しています。
1.I/O
工学社の月刊I/Oでよく使われていた形式で、縦・横16バイトと256バイトのチェックサムがついているタイプです。

DumpListEditorでチェックするときは「横16列汎用(I/Oもこれ)」を選択します。
2.PIO
工学社の月刊PIOなどで一部の機種向けに使われた形式で、縦8バイト・横8バイトと128バイトのチェックサムがついているタイプです。PC-6001の様なビデオ出力できるパソコン向けに表示文字数を少なくしたと思われます。

DumpListEditorでチェックするときは「横8列汎用」を選択します。
3.マイコン
電波新聞社の月刊マイコンで使用された形式で、横16バイトごとにチェックサムがついているタイプです。

DumpListEditorでチェックするときは「横16列汎用(I/Oもこれ)」を選択します。
4.アスキー
アスキー出版の月刊ASCIIなどで使用された形式で、横8バイトごとにチェックサムがついているタイプです。月刊LOGiNなどはこれに256バイトごとのチェックサムをつけたものを使用していました。

DumpListEditorでチェックするときは「雑誌アスキー(ADRS加算)」を選択します。
これらの形式のダンプリストをProgramListOCRとGoogleのOCRに読み取らせてみます。
Windows搭載のOCRはプログラム作成時に読み取りテストをしたのですが、誤変換が多すぎて実用的に使えそうになかったのでやめました。そのため以前説明したBasicOcrReader.exeにもマシン語ダンプリストの読み取り機能はついていません。
読み取り対象の画像は全て前に説明した通りの加工を行っています。
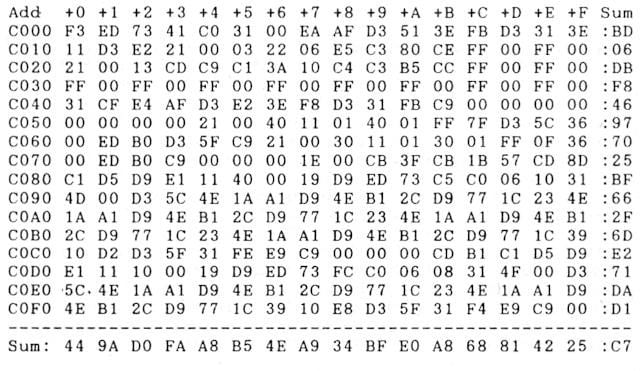



それではまずProgramListOCRです。マシン語ダンプリストを読み取るときは読み取り対象の種類を"hex"にします。
I/O

PIO
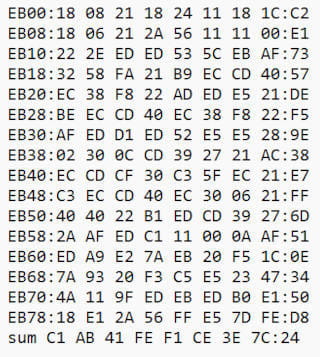
マイコン

アスキー

ProgramListOCRのマシン語ダンプリスト読み取りはかなり優秀です。元のフォーマットも崩さずそのまま読み取ってくれます。I/O形式のヘッダーが読み取れなかったり、多少の乱れもありますが簡単な修正で済むので問題ないですね。
上記の256バイトに関してデータの誤変換はありませんでした。だだし、大量のダンプリストを読み込ませるとさすがに誤変換は出てきます。読み取り画像のフォント形状によって異なってきますが、誤変換する文字がアドレスに使っている文字と重なると間違いが多く発生します。
次にGoogleのOCRを試してみます。

:
:
:
I/Oタイプのダンプリストを読み取った結果ですがフォーマットがめちゃくちゃです。手作業で修正するのもほぼ不可能な感じです。どの形式のダンプリストでも同じでした。
BASICの読み取りの時にも少し書きましたが、GoogleドライブのOCRは縦方向に同じ文字が続いたりスペースがあったりすると、そこを区切り文字として次の行を読み取ってしまう傾向にあります。そのためマシン語ダンプリストのように縦方向から見てきれいに並んでいるようなものは、この影響を受けやすくなっているみたいです。
OCRエンジンは優秀なので、まったく使えないのは残念です。
そこで読み取る画像を加工して縦方向のスペースをなくし、改行位置に印をつけて読み込ませたらうまく利用できるのではと考えました。
そのための画像加工プログラムが、以前配布したプログラムのDumpCutter.exeです。
使い方は簡単です。起動後に「OPEN」ボタンを押してGoogleOCRで読み取りたい画像を読み込みます。すると文字間のスペースが削除された画像が表示されます。

次に「SAVE」ボタンを押すと元のファイル名に"_cut"が追加された画像ファイルが保存されます。この画像をGoogleOCRにアップロードして読み取りを行います。
右下の"閾値"というのは空白部分の白色の判定に使う値で、小さくすると色のついた部分も白色とみなすようになります。ただ、最初に説明したように画像を加工していればこの値を変える必要はないでしょう。
DumpCutter.exeで修正したダンプリストをGoogleOCRに読み取らせてみるとこうなりました。
I/O

PIO

マイコン

アスキー

結構きれいに読み取ってくれました。I/Oタイプは少し乱れがありますが文字の認識は正確ですね。ただこれでは文字間が詰まったままなので、DumpListEditorでチェックできる形になっていません。そこで前回使用したDumpFormater.exeでフォーマットを整えます。
I/O DumpFormater.exeで修正後

PIO DumpFormater.exeで修正後

マイコン DumpFormater.exeで修正後

アスキー DumpFormater.exeで修正後

これらのテキストをDumpListEditorでチェックしたところ誤変換はありませんでした。GoogleドライブのOCRエンジンも優秀です。
この後、ProgramListOCRとGoogleドライブOCRの両方に様々なダンプリストを読み取らせてみましたが、どちらが優れているかは決めかねます。
とはいえGoogleのOCRは無理やり使ってる感じなので、使い勝手はProgramListOCRの方が上です。
ダンプリストのフォントによって変わってきますが、それぞれのOCRエンジンで誤変換しやすい文字は異なります。正確性を求めるなら、双方のOCRで同じダンプリストを読み込ませてみて、間違いの少ない方を採用するという使い方もありかもしれません。
面倒くさいことせずに手っ取り早く読み取りたいというなら、ProgramListOCR一択です。
DumpFormater.exeのマシン語ダンプリスト修正についてですが、ここまで長くなってしまったので次回に説明します。









※コメント投稿者のブログIDはブログ作成者のみに通知されます