syntax-caseはややこしく見える。
実際その通りだし、僕も実は良く分かってない。
そして最悪な事に、良く分かってないのは僕だけ、ではなくって、世界的にそうみたいだ。
何故なら「syntax-caseの使い方」と言うのがまず見つからないからだ。
まともなチュートリアルが無い以上、誰も手を出したがらない、ってのは当然となるし、ここでも良質なチュートリアルがあるのか否か、と言うのがユーザーとっては大問題になるんだ、って事が分かるだろう。
そもそも、元々Schemeにはマクロがない。いや、より正確な話をすると、現時点でも「権威ある仕様書」ベースで考えると(※1)・・・いまだSchemeにはマクロはない。
Schemeはその出自から、
- Smalltalk的なオブジェクト指向のキモであるメッセージ送信を研究する為に作った実験的処理系だった。
- 古のLisp1.5(※2)のようなシンプルなLispを目指し、また、ビルトイン関数の名称をそれまでのゴチャゴチャしたモノからモダンなものにする狙いがあった。
- Algolが導入したレキシカルスコープで完全にLispを実装するのが目的の1つだった(それまでのLispは全部ダイナミックスコープだった)。
と言うのが大きな作成目的で、そもそもマクロを考慮してなかったんだ。
2や3はSchemeを既に使ってればお馴染みだろう。
1が実は特にSchemeの特徴で、これが故に後に「継続」と言うツールに発展してる。メッセージ送信、レキシカルスコーピング、ラムダ式、の巧みな組み合わせがSchemeのSchemeたる所以であり、もう一回言うが、実はマクロはどーでも良かったんだ(笑・※3)。
従って、Schemeではマクロは「後付の機能」であり、お陰さんでいまだにユーザーにとってはある種鬼っ子のような厄介なブツとなっている。
外人のScheme使いもsyntax-caseの使い方に混乱を感じてるらしい。
英語でのリファレンスとして有効だと彼らが挙げてるモノは、調べてみると次の2つだ。
前者は、第4版よりも前の版だが、かつて日本で出版されていた事がある。しかし例によって出版元が桐原書店で、ピアソンレーベルからの撤退により、この日本語版は絶版となってしまった(※4)。
そして何より重要なのは、前者は詳細なリファレンスの類であり、後者は論文である。従って、これら2つを「マジメに読んでも」必ずしも自在にsyntax-caseでマクロを書けるようにはならないだろう(※5)。
他にはRacketのドキュメントが挙げられたりもしてるが、正直、これも実例がそんなに豊富ではなく、やっぱりリファレンスの範疇を出ず、チュートリアルとして見た時にそんなにデキが良い、とは思えない。
ANSI Common LispのマクロはあくまでLispの中で定義する、と言う方針だ。
一方、Schemeのマクロは一般に「健全なマクロ」と呼ばれてるが、事実上Schemeの内部にはない。要するにメタプログラミング専用の言語がSchemeとはまた別に定義されてる、と考えた方が実態には近い。
どういう事か、と言うとだ。
例えばPythonでSchemeを書いたとする。
フツーは「ちょっと構文を追加したいな」と思った場合、Pythonで書いたSchemeインタプリタなりコンパイラに「Pythonで」構文を追加する。そうしてフツーは「ヴァージョンを上げました!」となるわけだ。
一方、Schemeのマクロの場合、この「Pythonで構文を新規追加する」代わりにメタプログラミング用の「Scheme本体とは全然別の」プログラミング言語を用意して、強制的に構文を追加出来るスタイルにした、と言うわけ。
でもそれがSchemeであるか、と言うと多分違うし、じゃあ、マクロをLispスタイルにする必要が本当にあるのか?と言われても「多分違うんじゃねーの?」としか言いようがない。
LispスタイルでLispの中身でマクロを書こうとしているANSI Common Lispの方針とは(安全性の問題はさておいて)全然違ってて、ちとイビツと言えばイビツな存在となってる。うん、そうとしか言いようがねぇんだよな。
そして「実はSchemeじゃない」って事を考えてみても、特にsyntax-caseはANSI Common Lispのdefmacroに比べても記述量が桁外れに増える傾向がある。正直「一体何だこれは」と言うのが本音だ。
正直な話、Schemeでマクロを書く場合、簡単なsyntax-rulesを使っておけば良いと思う。そしてsyntax-rulesで書けないマクロは書こうとしてはいけないとまで思ってる。
基本的に、そもそもマクロは本当に必要になるまで書く必要がないものだ。そしてScheme + syntax-rulesの組み合わせで書くのなら、Schemeの仕様書で構文として定義されてるブツの拡張程度で止めておくのが幸せなんじゃないか、とか思ってる。
例えばSchemeの仕様書で定義されてる構文の主なモノは次のような感じだ。
- lambda
- if
- set!
- cond
- case
- and
- or
- when
- unless
- let
- let*
- letrec
- let-values
- let*-values
- begin
- do
- delay
- parameterize
- case-lambda
- let-syntax
- letrec-syntax
- syntax-rules
- define-values
20個ちょっとしかない(実はもうちょっとあるが、主に、R7RSで定義されててもRacketで搭載されてない、あるいは別名になってるモノは省いた)。
これら構文を組み合わせて「より便利にしたい」場合にsyntax-rulesを使えばほぼ問題は解決するんじゃないか。
まず、組み込みの基本構文を分類して見てみると、
- ラムダ系(lambda、case-lambda)
- 条件分岐(if、cond、case、and、or、when、unless)
- 定義系(set!、define-values)
- 束縛系(let、let*、letrec、let-values、let*-values、parameterize、let-syntax、letrec-syntax)
- 逐次処理(begin)
- 反復(do)
- 遅延評価(delay)
と、大雑把に7種類くらいの用途に分かれている。そして、「これら以外でこれら以上の突飛で複雑な事をしようと」まずは思わない事。そして、これら「構文の機能を模して」そしてこれらの基本構文を「組み合わせつつ」マクロを定義するのが吉、だと言う事だ。
ただ、Racketなんかじゃもう既に便利構文が別に定義されてたりするし、例えばここでのdelayなんつー構文を何らか拡張して使いたい、とかアタマを悩ますよりも、遅延評価のライブラリを使った方が色々と早いだろう。
例えばANSI Common Lispを見ると、beginの代わりにprognと言うものがあって、逐次実行の最初の値を返すprog1、逐次実行で2番目に実行された式の値を返すprog2と言うものがある。
Racketではprog1に相当するbegin0がある。しかしprog2相当のbegin1はない。こういう時がマクロの出番だ。
(define-syntax begin1
(syntax-rules ()
((_ form1 form ...)
((lambda ()
form1
(begin0 form ...))))))
「既にある構文を組み合わせて新しい構文を作る」のなら、大掛かりな飛び道具は必要がない。syntax-rulesで充分に書ける。
;;; 2番目に実行された式が全体の返り値となる。
> (begin1 1 (values 2 3 4) 5)
2
3
4
>
次のサンプルとして、条件分岐構文の変種も書いてみよう。
例えばあるデータを与えられたとして、その「型」で場合分けをしたい、とする。
マトモに書けばcondで次のように書かないとならないだろう。
(cond ((inexact? x) 'do-foo)
((null? x) 'do-bar)
((list? x) 'do-baz)
...
これはちと煩わしい。同じデータ(この場合はx)を何度も書かないとなんない。
出来ればcaseのように、対象となるデータを書く場所をたった1つに限定し、指定した述語をそれにガンガン適用して欲しい。
こういう構文を設計したい時もマクロの出番で、上にも書いた「既存の構文を利用して新しく構文を作る」原則に合っている。
そしてANSI Common Lispにtypecaseと言うマクロがあるので、それを参考にすると再帰的定義でこんなカンジになる。
(define-syntax typecase
(syntax-rules (else)
((_ test-key (else form ...))
(cond (else form ...)))
((_ test-key (type? form ...))
(when (type? test-key)
form ...))
((_ test-key (type0? form0 ...) (type1? form1 ...) ...)
(cond ((type0? test-key) form0 ...)
(else (typecase test-key (type1? form1 ...) ...))))))
このように、これもsyntax-rulesで十二分に書ける範疇だ。
> (define (what-is-it x)
(format "~s is ~a.~%"
x (typecase x
(inexact-real? "a float")
(null? "the emply list")
(list? "a list")
(integer? "an integer")
(symbol? "a symbol")
(else "what I ain't known"))))
> (map what-is-it '(() (a b) 7.0 7 box))
'("() is the emply list.\n"
"(a b) is a list.\n"
"7.0 is a float.\n"
"7 is an integer.\n"
"box is a symbol.\n")
>
ifの変種も書いてみようか。ポール・グレアムのArcのように、
(if a b c d e ...)
のように書ける事、とする。これも基本的には再帰的にcondへと展開するようにすれば簡単だ。
(define-syntax arc-if
(syntax-rules ()
((_ x)
(cond (else x)))
((_ a b)
(cond (a b)))
((_ a b c ...)
(cond (a b)
(else (arc-if c ...))))))
次は反復の例を考えてみる。
(define-syntax dotimes
(syntax-rules ()
((_ (var count-form result-form) statement ...)
(do ((var 0 (+ var 1)))
((>= var count-form) result-form)
statement ...))
((_ (var count-form) statement ...)
(dotimes (var count-form '()) statement ...))))
(define-syntax dolist
(syntax-rules ()
((_ (var list-form result-form) statement ...)
(let loop ((n-list list-form))
(if (null? n-list)
result-form
(let ((var (car n-list)))
statement ...
(loop (cdr n-list))))))
((_ (var list-form) statement ...)
(dolist (var list-form '()) statement ...))))
この2つは、実際は「構文拡張」と言うよか「構文縮小」だ(笑)。
しかし、doを用いる際の「良く使うデータ対象(つまり整数とリストだ)とそのオチ」の典型的パターンで、言い換えると汎化能力が優れたdoを用いると「大げさに見える」パターンでもある。
これら2つのまずは特徴は、第一引数がフルだと3つ必要になるんだけど、最後の1個が省略出来る辺りだ。
こういう場合、フルでまずはマクロ展開のコードを書いておいて、「付け足しで」第一引数が2つのヴァージョンを書く。
そして第一引数が2つのヴァージョンの展開型をフルの、既に定義したマクロを利用して書けば良い。
ちなみに、dolistの方は名前に反してdoを使わず、名前付きletを使ってマクロの展開型を書いている。
そっちの方がこのマクロの場合だと書きやすいから、だ。
> (dotimes (temp-one 10 temp-one))
10
> (define *temp-two* 0)
> (dotimes (temp-one 10 #t) (set! *temp-two* (+ *temp-two* 1)))
#t
> *temp-two*
10
> (set! *temp-two* '())
> (dolist (temp-one '(1 2 3 4) *temp-two*) (set! *temp-two* (cons temp-one *temp-two*)))
'(4 3 2 1)
> (set! *temp-two* 0)> (dolist (temp-one '(1 2 3 4)) (set! *temp-two* (+ *temp-two* 1)))
'()
> *temp-two*
4
> (dolist (x '(a b c d)) (display x) (display " "))
a b c d '()
>
フツーのプログラマが欲しがる繰り返し構文、forはRacketにはあるので、whileを実装してみよう。whileをsyntax-rulesで書けば次のようになる。
(define-syntax while
(syntax-rules ()
((_ test body ...)
(do ()
((not test))
body ...))))
こうすれば、Scheme/Racketでも「フツーの言語に備わってる」whileが定義出来て、フツーに使う事が可能だ。
> (let ((i 0))
(while (< i 10)
(display i)
(display " ")
(set! i (+ i 1))))
0 1 2 3 4 5 6 7 8 9
>
次は束縛系を見てみよう。
Lispだとletが大好き!って程良く使うんだけど、反面、初心者状態の時は皆すげぇ嫌ってたりする。なんせカッコが多すぎるし意味が分からない。さすがの僕も、Lispを学びはじめた最初の頃、letを見て「なんでこんなにカッコが多いの」って思ってた。
こういう場合はぶっちゃけ、マクロで改造しちまっていい(笑)。letのカッコが多すぎるのなら減らしたletを作っちゃえばいいじゃない、って事だ。マリー・アントワネット理論である(謎
またもやポール・グレアムのArcのletを真似してみよう。
ポール・グレアムはまずは「letは1つだけの値を束縛するもの」だと定義した。
(define-syntax arc-let
(syntax-rules ()
((_ variable init body ...)
(let ((variable init)) body ...))))
;;; 実行例> (arc-let x 1
(+ x (* x 2)))
3
>
Arcでは複数の値を束縛する場合、letではなくwithと言うマクロを使う。
(define-syntax with
(syntax-rules ()
((_ (variable init) body ...)
(arc-let variable init body ...))
((_ (variable0 init0 variable1 init1 ...) body ...)
(let ((variable0 init0) (variable1 init1) ...)
body ...))))
;;; 実行例> (with (x 3 y 4)
(sqrt (+ (expt x 2) (expt y 2))))
5
>
さて、上で7種類の主な組み込み構文を掲げたが、実際問題、この中で「構文拡張」が要されるのは大体のトコ、
- 条件分岐
- 束縛系
- 逐次処理
- 反復
の4種類くらいだろう。これらに対してこれらを利用して追加を試みる、と言うのが大方のケースになり、そうすればsyntax-rulesを使ってSchemeの範疇で無理なくマクロが組み立てられる。
ポイントの1つ目は、Schemeで定義されてる基本の構文類をまずは良く知っておく事。そして、「構文記述形式」はそれら「スタンダード」を良く真似る事だと思う。そうすれば無理なくマクロが記述可能だろう。
上の4つ以外だと、例えば定義系なんかは殆ど作る必要がないモノだと思ってる。
例えば、ここで、
「define-syntaxとsyntax-rulesを組み合わせたdefine-syntax-rulesを定義しよう!そうすればもっと簡易にマクロが書ける筈だ!」
とか思いついたとする。良いアイディアなんだけど、実はそのテのモノはRacketで予め準備されてたりして、大体のケースでは徒労に終わる。
せいぜい書く余地があるとしたら、往年のInterlispのdefineqみたいな「複数の関数を一気に定義出来る」マクロくらいだろうし、これが現在どれだけ役に立つのか、ってのは分かんない。
(define-syntax defineq
(syntax-rules ()
((_ (name (arg ...) body ...) ...)
(define-values (name ...)
(values (lambda (arg ...) body ...) ...)))))
set!なんかもマクロで弄ろうとするなら、SRFI-17の一般化されたset!を使うべきだと思うし、上でも書いた通り、遅延評価もdelayをマクロで直接弄ろうとするならRacketで用意されているstreamを使うか、SRFI-41を利用すべきだろう。ここでも「なるたけマクロを書かずに済むなら済ませた方が良い」の法則が生きるし、delayのような「関数的に役立ちそうなマクロ」は直接作る可能性を潰しておいた方が良いとまで思っている。
大体、仕様を参考にせずに、一から書くマクロなんざamb(※7)くらいしかないだろ。
ポイントの2つ目は、Schemeの組み込み構文を使って何か書いてる際、何度も同じような「構文の重ね合わせ」が生じた時に、それを縮小させる事だ。
例えば、ポール・グレアムが次のように書いている。
マクロのやっていることと言ったら,打ち込む文字の節約が全てだ. 似たような考え方をしたいなら, コンパイラの仕事はマシン語を打ち込む作業を省くことだと言える. ユーティリティの効果は累積していくので,その価値は見過ごせない. 単純なマクロを複数の層に重ねることで, エレガントなプログラムと理解しがたいプログラムとの違いが分かれる.ほとんどのユーティリティは埋め込まれたパターンだ. 自分のコードの中のパターンに気付いたら,それをユーティリティに変えることを考えよう. パターンとはまさにコンピュータの得意分野だ. 代わりに仕事をしてくれるプログラムが手に入るというのに, どうして頭を悩ます必要があるのだろうか?
例えばくだらない例を考えてみる。以下のコードはわざと与える値を多値にしてみたフィボナッチ数列の13番めの数を計算するコードだ。
(let-values (((x y) (values 0 1)))
(let loop ((a x) (b y) (count 12))
(if (zero? count)
a
(loop b (+ a b) (- count 1)))))
この時、let-valuesとletを重ね書きしてるのが、このコード上「字数」と「インデント」が増えてる原因だ。
ところで、名前付きletは末尾再帰を書くのにはとても良い構文だ。と言う事は、仮に名前付きlet-valuesなんつーものがあったらどうだろうか。そうすれば、たとえ多値として受け取った変数相手でももっとシンプルに書けるかもしれない。
(define-syntax nlet-values
(syntax-rules ()
((_ name (((formal ...) init) ...) body ...)
(let-values (((formal ...) init) ...)
(letrec ((name (lambda (formal ... ...)
body ...)))
(name formal ... ...))))))
これは、実際に自分が「展開型」自体を気づかずずーっと書いてきてて、それが複数回重なった時に試してみる手の代表例だろう。既に「何度も直書きしてる」以上、その展開型の構造自体はすぐさま思いつく事になると思う。
1つ気をつけるのは、ラムダ式に与える引数とletrecで作成された関数呼び出しの引数のellipsis(...の事)が多く見える辺りだ。
(lambda (formal ... ...)(name formal ... ...)
これは構文形式、つまりパターンの記述に対応している。
(((formal ...) init) ...)↑ココ
つまり、実際、これを使った時の
((formal1 ...) init1) ((formal2 ...) int2) ((formal3 ...) int3) ...
と並んでた際に、これらformalを全部繋ぎ合わせて
formal1 ... formal2 ... formal3 ...
と全formalを並べまくる為に余分(に一見見える)なellipsisを1つ追加してるんだ。これがsyntax-rulesのパターンマッチングの要請となる。
> (nlet-values loop (((a b) (values 0 1)) ((count) 12))
(if (zero? count)
a
(loop b (+ a b) (- count 1))))
144
>
基となるlet-valuesのお陰でカッコが多いカンジだが、一応、行数も減らせて、タイピング量も減り、そして計算もキチンと行われている。
ポイントの3つ目は「Schemeの仕様に書かれてる構文」を把握した後は、その構文がマクロでどう定義されてるのか知る事だと思う。概要だけでもある程度把握しておけば、マクロを書くのがかなりラクになるだろう。
例えば上のnlet-valuesのマクロもそうなんだけど、背景知識として名前付きletがどんな実装をされてるのか、と概要だけ知っていれば割にスムーズにその「構造」を応用したマクロの記述が可能となる。
;;; 名前付き let の内部的な実装例;;; 名前付き let の記述パターンを letrec での記述に変換してる(define-syntax nlet
(syntax-rules ()
((_ proc-id ((id int-expr) ...) body ...)
(letrec ((proc-id
(lambda (id ...)
body ...)))
(proc-id int-expr ...)))))
例えばSchemeの構造上、非常に重要で押さえておかなければならない事に、(名前付きじゃない素の)letはラムダ式の構文糖衣、つまりマクロだ、って事がある。
(define-syntax my-let
(syntax-rules ()
((_ ((variable init) ...) body ...)
((lambda (variable ...)
body ...) init ...))))
このように、基本的に、Schemeはletをソースコード上で見かけると、まずはラムダ式に書き換えようとする。
そしてそのラムダ式を良く見てみよう。
((lambda (variable ...)
body ...) init ...)
何か気のせいか、ラムダ式の前にmapを置いてみたくなる。
置いてみようか?
(define-syntax met
(syntax-rules ()
((_ ((variable lst) ...) body ...)
(map (lambda (variable ...)
body ...) lst ...))))
大した事はしてないんだけど、mapを多用する際、ラムダ式の中身が大きくなると、ちとイライラする事もある。そういう場合はラムダ式の中身に集中したいわけだが、その時、こういうマクロを組み立てておけばアッサリと書ける事があるかもしれない。
;;; 実行例> (met ((x '((a b) (d e) (g h))))
(cadr x))
'(b e h)
> (met ((n '(1 2 3 4 5)))
(expt n n))
'(1 4 27 256 3125)
> (met ((x '(1 2 3)) (y '(4 5 6)))
(+ x y))
'(5 7 9)
>
これもletの中身、と言うかその「構造」を知ってれば応用出来る、と言った小さな例だ。
ポイントその4は、今までの例からも見て分かるだろうが、なんかマクロのネタを探す際にはANSI Common Lispのマクロを見てみれば良い。実装の難易度の低い高いはあるだろうけど(多分ANSI Common Lispの拡張loopはANSI Common Lispを使いまくっていても書く難易度は最高だろうし、Schemeのマクロで書けるたぁ思わない・笑)、色々と参考になるはずだ。
Common Lisp HyperSpecは大変良く出来てるリファレンスだ。ハッキリ言って、SchemeやRacketのドキュメンテーションより断然良い。ここでマクロを見つけたらSchemeに移植してみる、ってのはかなり良い練習になる。
かつ、ANSI Common Lispにはmacroexpand-1と言う便利関数があり、マクロの展開形を見ることが出来るんで、アンチョコ代わりに重宝する。
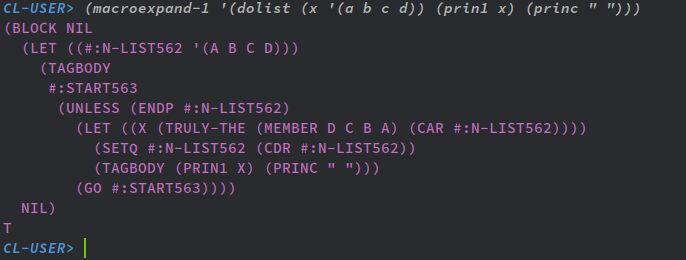
ANSI Common Lispでdolistの展開型を調べてみた例。doを使ったマクロではなく、ジャンプ構文に変換されてる事が分かる。
#:START563と書かれてるのがラベルで、#:N-LIST562に束縛されてるリストをCDRしながら破壊的変更をし、NULLになるまでジャンプしてる構造が見て取れる。
ポイントその5。あまり凝りすぎない事。
例えばANSI Common Lispのsimple-loopをマクロで実装する例を紹介したが、ハッキリ言ってあのコードは徹頭徹尾凝りすぎだ。
まぁ、call/ccの機能の一端を紹介したい、って事もあったんで複雑にしたわけだが、本来だったら、
(define-syntax loop
(syntax-rules ()
((_ body ...)
(do () (#f) body ...))))
だけ、で済むコードなんだ。
上の定義でのloopは明らかに「無限ループする」マクロだ。
でも脱出したいのなら、単に外側からcall/ccで包んでやれば済む話、だ。call/ccも含めてマクロの内側に仕込もうとするから大変な目に合うんだ。
> (define (sqrt-advisor)
(call/cc
(lambda (return)
(loop (display "Number: ")
(let ((n (read)))
(unless (integer? n) (return #f))
(display (format "\nThe squre root of ~a is ~a~%" n (sqrt n))))))))> (sqrt-advisor)
Number: 5
The squre root of 5 is 2.23606797749979
Number: 4
The squre root of 4 is 2
Number: done
#f
>
ANSI Common Lispみたいに「シンプルにreturnが使えない」辺りに歯がゆい思いをするかもしんないけど、それはそれとしてSchemeでは「call/ccを使うのが脱出の形式なんだ」と諦めよう。とにかく脱出したいコードを包むんだ。
これはマクロに限った話だけじゃない。例えば独習Scheme三週間の例を借りてくる。
数値のリストをとりそれらを掛けあわせる手続き list-productを 考えてみる。
フツーに実装すると次のようになるだろう。
(define (list-product s)
(foldl * 1 s))
しかし、もし引数s、つまり与えられたリストのどっかに0があった場合、そこで計算を止めさせなければリストの末尾までこのlisp-productは計算を止めない。「0に何掛けても0になる」以上、0が出てきた以上もう答えはあからさまに0になるんで、以降の計算は必要ないんだ。
こういう時、call/ccを仕込めば、途中で計算を止めて脱出出来る。
(define (list-product s)
(call/cc
(lambda (return)
(foldl (lambda (x y)
(if (zero? x)
(return x)
(* x y))) 1 s))))
とにかく、「call/ccの動作が良く分からない」と言う人でも脱出だけは出来るようにしよう。通常の言語のreturnとかbreakに比べるとまずは脱出したい範囲をcall/ccで包まなければならないので記述上はメンド臭い。その代わりに「もっと強力な事が出来る」のがcall/ccなわけだ。
ここで「returnやbreak自体をマクロで書けば?」って思いつく人もいるだろうが、残念ながらそれは不可能だ。と言うのも、前書いたようにcall/ccのスコープは表裏が反転してる。しかし、変数returnやbreakと言う「字面」自体に環境をキャプチャする手段がない。あくまでマクロはSchemeのルールに則って式を展開していくんで、異端のスコープを持つcall/ccを使って「単独で」returnやbreak等のマクロを書く事は不可能なんだ。
まぁ、ハッキリ言えばcall/ccは「構文並の強力な機能を持つ関数」で、SchemeのSchemeたる機能だと言っても良いんで、あまりマクロに含めなくてもイイんじゃないか、とか言う気もしてる。マクロに含めると結果、前回見せたように展開型に外部から入力された変数を捕捉させなきゃならなくなるんで、メンド臭いのだ。
さて、まとめよう。syntax-rulesを使って簡単な(に)マクロを書く指針は以下の通りだ。
- Schemeの仕様を良く読んで、どれが「構文」として定義されてるのか把握しておくこと(30個もない)。
- マクロを書こうとする一番のタイミングは「構文と構文の重ね書き」が生じた時だ。
- Schemeの仕様に定義されてる構文が「どういう風にマクロとして定義されてるのか」想像するのは良い練習で、むしろその形式を借りてくるべきだ。
- 困った時にはANSI Common Lispのマクロを参考にする事。多くの場合はsyntax-rulesの方がマクロを簡単に書ける筈なんでビビらない事。
- 凝りすぎるな。
関数は関数と構文を駆使して書くのなら構文は構文を利用して作るんだ、って事を今一度キモに銘じよう(むしろsyntax-rulesでの展開型記述の際、下手に関数を入れるとバグる元になる)。そしてもう一度、「凝り過ぎなければ」syntax-rules(※8)でマクロを書くのはさほど難しくはないのだ。
※1: Schemeには当然国際規格がない。ただし、一番権威ある仕様書が何か、と言うと通称、米国電気電子学会(IEEE)で決定されたIEEE Scheme Standardと言う事になり、これはR4RSと言う古い仕様書と互換である(ただし、2019年に消失した?)。
言い換えると、R5RS/R6RS/R7RSはR4RS程「権威がない」と言う事で、公式仕様がR4RS互換だ、と言う事を鑑みるとR5RS/R6RS/R7RSはいずれにせよ「実験仕様」の域を実は出ていない。
なお、過去に、ANSI Common Lisp宜しく、ANSI(米国国家規格協会)に同じくR4RSが公式仕様として提案された事があるが、否決された模様で、結果、ANSI Schemeと言う公式仕様は存在しない。
※2: はじめて人々の前に姿を現したLispだ。人々の・・・とは言っても大学の研究者向けにメインフレームで動作する、と言う意味だが。
これがキッカケになって日本でもメインフレームで動作する「俺様Lisp」が作られはじめ、後の80年代のPC向けLisp(今は絶滅したが・笑)のルーツとなる。
なお、いきなり1.5から登場してて、これ以前はMITの中でひっそりと作られ使われていた。
※3: だからある種、ANSI Common Lispのキモの機能がマクロだとすれば、Schemeの場合それはマクロではなく「継続」と言う事になる。
そして継続と言う機能だけ見れば、他の言語に全く存在しなく(とは言ってもRubyにはあるらしい)、そして確かに恐ろしい程強力な機能ではある。
言い換えると「継続を制す者がSchemeを制す」と言って過言ではない。
※4: 返す返すも、桐原書店のピアソンレーベルからの撤退は、日本の技術書界では大きな痛手としか言いようがない。どーでも良い出版社が生き残って重要な出版社が撤退した、って事だからだ。
※5: ちなみに、この2つの文書共に著者はR. Kent Dybvigと言うインディアナ大学の教授で、平たく言うと、この人がSchemeマクロの仕掛け人である。
英語文書が読めない、と言う場合、同じくDybvig先生が提案したSRFI-93の日本語訳を読めばある程度の事は分かるだろう。大部分が「プログラミング言語Scheme」と言う書籍のマクロの項と被っていて、これがR6RSのsyntax-caseの仕様の基となっている。
なお、この人は同時に、かつて商用Scheme処理系であり、Scheme最速コンパイラと呼ばれたChez Schemeの実装者でもある。
今はChez Schemeはオープンソースとなってるが、これに伴ってRacketはかつてのMzScheme/PLT Schemeから育ててきたバイトコードインタプリタ/コンパイラを捨て、その本体をChez Schemeとした。リスナでヴァージョン番号横に表示されてる[cs]と言う文字はChez Schemeを示している。

つまり、現行のRacketと言うプログラミング言語はChez Scheme上で動いているプログラミング言語であり、ポール・グレアム作成の新しいLisp、ArcはChez Schemeの上で動いてるRacketの上で動くLispと言う事になる。
※6: オプショナル引数、と呼んだりする。
※7: 独習Scheme三週間か紫藤のページを参考に。理論背景に於いてはSICPが詳しい。また、ポール・グレアムのOn Lispを見れば分かるが、継続が欠けているANSI Common Lispが唯一Schemeに、実装の完成度から言って敗北する例ともなっている。
※8: ちなみに、あれだけマクロマクロ言うてたポール・グレアムだが、Arcのソースコードを見ると、コア部分は1,500行程だが、一箇所しかマクロが使われてなく、そしてsyntax-rulesしか使われてない。Arcのソースコードにはsyntax-caseの出番は無かったのだ。