まぁ、別にstrtok関数に限った話ではなく、K&Rから始まって、実はC言語の「解説書」の類だと、そもそもC言語に含まれる「標準ライブラリ」の実際の使い方、ってのはあんま解説してない。
 | プログラミング言語C 第2版 ANSI規格準拠 B.W.カーニハン 共立出版 |
よってC言語初学者から始まって、「C言語標準装備のライブラリ」の「使い方」をキチンと学んでる人は少ない。どっちかっつーと「標準ライブラリ群にある機能」を「車輪の再発明」しかねないのがC言語ユーザーなんだ。
それだけじゃない。strtok関数の「サンプル」を見たトコで、「これは使い勝手のある関数だ!」なんてあまり思わんだろう。
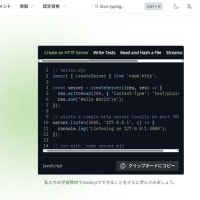
どのサイトを見ても、基本的には次のような「用例」が書かれているだけ、だ(※1)。

しかし、これを実行しても次のようになるだけ、だ。
Next line? (empty line to quit)
"My goodness," she said, "Is that right?"
That line contains these words:
"My"
"goodness"
"she"
"said"
"Is"
"that"
"right"
Next line? (empty line to quit)
う〜ん・・・嬉しいか(笑)?
いや、確かに「入力された文字列が単語毎に印字されてる」だろう。
へぇ、そりゃ凄い、と。
で?
単語毎、なんかに印字しなくても通常は構わないし、「だからどーした」って結果、って言えば結果なんだよ。
そう、ここでも「C言語はとにかくprintfしまくる」せいで、副作用で終わってる。
確かにstrtok関数の「使い方」は書かれてるんだけど、言っちゃえばこれは実用例ではないんだ。単に単語毎に分けて印字するだけ、ならクソの役にも立たない。
事実、SchemeのSRFI-13のstring-tokenizeなんかに慣れてると、あまりのショボさに開いた口が塞がらなくなるだろう。

上の写真はRacketでの例だが、string-tokenizeはデータ構造を返す。具体的には文字列を要素としたリストだが、これを入手した、と言う事は貴方がこのデータ構造を自在に解析出来る、と言う事だ。consしたりcarしたりcdrしたり・・・要は好きなように調理してよい。
これがデータ構造を返す旨味であって、C言語のprintf塗れでは得られない利点なんだ。
もっとも、C言語ユーザーの名誉のために言っておくけど、通常、こういうトーカナイズが一番何に使われるのか、と言うとプログラミング言語作成なんかでの字句解析に於いて、だ。そして、C言語ユーザーでトーカナイズ及び字句解析を行う人は、もっとシリアスなレキシカル・アナライザを用いる。lexとかflexの類、だな。彼らはCのstrtokが貧弱だ、って事は重々承知してるんで、strtokなんぞは使わんのだ。それよりもlexやflexと言うツールの使い方に習熟する。それで実用的には問題解決、となる。
とまぁ、これがstrtokなんだけど、一方、この関数は割にC言語のポインタを説明するには都合がいい関数なんじゃないか、と気づいた。
よって復習も兼ねてstrtokの動作を介してCのポインタをちと軽く説明していってみよう。
まず、モダンな言語では文字列はオブジェクトだ。このオブジェクト、って言い回しが個人的には嫌いなんだけど、とは言っても良い「訳語」が日本語にはない、ってのが実際なんだよな・・・無理矢理訳すと物体とか実体だろうか。
要は、
文字列は文字列と言うモノ(物体)であってそれ以外ではない
と言うのが「文字列はオブジェクト」と言う表現の言外での主張だ。
分かる?C言語みたいに「文字列の実際はメモリに格納された・・・」とか考えるな、っつってんだわ。
そう、オブジェクトって言い回しはまたもや抽象化、なんだよ。メモリがどーの、って考えなくて良いように設計されている。
加えると、「オブジェクト」って言い回しはさも「オブジェクト指向」に紐付けされてるような印象を与える。確かにそうだ。いや違う。
どっちなんだ?って話なんだけど(笑)、実はいわゆる「オブジェクト指向」言語、つまり、例えばクラスがあってメソッドがあって・・・ってのは実装上、プログラマにどういう「型定義」の方法論を提供するのか、と言う狭義の意味だ。
別のトコにもちらっと書いたけど、本来のオブジェクト指向の意味ってのは上で書いたようにプログラミング言語が提供するデータ型をすべてオブジェクトとする、って意味だ。メモリがどうの・・・じゃなくって、整数は整数と言うオブジェクト、浮動小数点数は浮動小数点数と言うオブジェクト、文字列は文字列と言うオブジェクト、つまり全データ型はそういう「物体」であって、それ以上の意味はない、と言う主張なんだ。
この観点から言うと、実は現代のモダンなプログラミング言語のその殆どは、クラスやメソッドと言うシステムを持たなくてもオブジェクト指向なんだわ。
この「広義の意味」でのオブジェクト指向、って概念はあまり一般的じゃないんだけど、プログラミング言語設計者は割にそう捉えている。かつ、凝った「設計」になると、このオブジェクト同士がツリー構造として設計されていて、根源的な「オブジェクト」から全部が「物体である」と言う性質を「継承」するように作られている。例えば「整数」や「浮動小数点数」と言うオブジェクトは「数値」オブジェクトの性質を継承してて・・・ってな具合だ。
いずれにせよ、「オブジェクト指向言語」とは捉えられてないプログラミング言語の解説で「✗✗はオブジェクトです」って書かれていた場合、それは上記のような意味だ。広義のオブジェクト指向で設計されてます、って意味なんだ。
ところがC言語はそういう意味でもオブジェクト指向じゃない。C言語では文字列はオブジェクトではない。つまり、C言語には文字列はない、ってのと同義だ。連続したメモリ領域に入ってる数値を文字列として解釈するだけで、それは文字列と言うオブジェクトではない。
例えば、メモリっつーものの可視化方法を考えてみると、事実上、Excelのような表計算ソフト上のセルの状態と似ている。
例えば"My goodness," she said, "Is that right?"と言う文章を考える。これはC言語なんかではそのまま表計算ソフトだと次のように「文字」が連続して配置されてるのと同じ意味だ。

縦の数値が「アドレス」を表してる。ポインタ変数が代入すべきブツはこれら数値で、文字の方じゃない。
例えば変数lineに文章"My goodness," she said, "Is that right?"が入ってると仮定する(「仮定」であって真実ではない)。
次にポインタをpと宣言するには、
char* p;
と言う宣言になるが、使用時、「アドレスを指す」には単なるp、「アドレスに書き込まれてる情報を読み取る」には*pを使う。ここがCのダメなトコで、宣言時の*の使用法と真逆に見えるんだ(※2)。
そして、C言語には文字列と言うオブジェクトが無い、と言う話をした。従って、モダンな、僕らが知ってるLispやPythonみたいな言語と違って文字列らしき情報は変数に代入出来ない。あるのは連続したメモリ領域だけ、なんだけど、このメモリをまとめて扱う手段さえC言語にはないんだ。
C言語だと次のように考えてるわけだ。取り敢えず「連続して使用された形跡がある」メモリ領域がある、と。本当は連続かどうか、ってのは関係ないんだけど(何故なら本来は「形跡」さえない)、あるアドレスを「指す」事だけは出来るわけ。上の例で言うと「1」だけは取り出せるわけだよ。
そこでポインタでは事実上、次のような事をやる。
p = アドレス1;
アドレス1以降がどうなってるかは感知せんのだけど、取り敢えず「特定のアドレス一個」だけはポインタに代入出来るわけだな。
これを実際は次のように書く。
p = line;
これで分かるのは、line自体は配列として宣言されてるんだけど、「C言語には配列なんつー高級なデータ型はない」。従って、lineが持ってる情報は「配列情報」なんつー高級なモノじゃなくってあるアドレス、ここではアドレスNo.1、と言う情報だけ、なんだ。当然、配列のケツの情報なんざ持って無く、単にアドレスNo.1をポインタ変数pに代入した、ってだけなんだ。
実際次のようなプログラムを書いて見てみる。

lineが持ってるアドレスとポインタpが持ってるアドレスが一致してる。代入してるんで当然なんだけど、いずれにせよ「配列がない」「文字列がない」C言語では「あるアドレス一個」しか受け渡しが出来ない、って事だ。
なお、書式指定子の%pはアドレスを表示するために使われる。ここでは16進数表記になってるが、その辺は実装依存だ。僕の環境では、今回は、十進数ではメモリ上では8,795,109,008,935番目のアドレスから使用されてる、と言ってる。すげぇ数だ(笑)。
まぁ、上の表計算の例だと簡単の為、「アドレス1」とか言ってたが、実際はこんな風になるし、「メモリのどこから連続して使用するのか」はOSとコンパイラが相談して「勝手に決めている」。よって実際は「どこから使われるか」はこのように、コッチ側からコントロールする事は出来ない。
もうちょっと見てみようか。

配列lineの0番目の要素とポインタpが指し示してるアドレスの「中身」は全く同じだ。引用符(")となってる。うん、"My goodness," she said, "Is that right?"の0文字目は確かに"だよな。
なお、ポインタ変数は「参照先のアドレスが保持してる」プツを「調べる」時に*を使う。上のコードの4番目のprintf文を良く見てくれ。pは「アドレスを保持」してるけど、*pはその参照先のアドレスが何を持ってるのか調べてて、それは「文字"」と言う事だ。
この辺がひっじょーに「分かりづらい」文法になっている。混乱して当然で、「ポインタが難しい」んじゃないんだ。「C言語の文法がクソ」なだけだ。
さて、C言語には文字列がないし文字もない。実際はメモリに格納されてるのは、表計算的には次のようなモノだ。

いや、これでも甘い。こうだ。

実際、メモリたぁ0と1しか取れないエクセルみてぇなモンだ(爆)。
0と1しか使えない表計算ソフトなんざ一体何の役に立つんだ、ってな話だが、実際メモリってのはそうなってんだから仕方がない。
そしてこのケースだと横軸はA〜Hの8つあるが、Cの型宣言ってのは単純に、この横軸を何個用意するか決めてるだけ、に過ぎない。charだとデファクトスタンダードでは8個用意する(※3)、ってだけだ。
ここで次の様なプログラムを書いてみる。

p++と言うのはポインタ変数pに代入されたアドレスのインクリメント(増加)だ。
そしてpが指してるアドレスの中身がヌル文字になるまでルーピングする。
これを実行すると次のようになる。
<省略>...そのアドレスの中身は'g'
現在のアドレスは0x7ffce685dba5
そのアドレスの中身は'h'
現在のアドレスは0x7ffce685dba6
そのアドレスの中身は't'
現在のアドレスは0x7ffce685dba7
そのアドレスの中身は'?'
現在のアドレスは0x7ffce685dba8
そのアドレスの中身は'"
ここで分かる事は次の2つだ。
- 1バイトが何ビットか知らないが、「メモリの塊」は1バイト管理されている。
- char型を扱う以上、char型は1バイトなんで、アドレスを一つづつ進めるとメモリの塊をまたぎながら一つづつ進んでる。
特に2番に注目する。実行を見てみると、十六進数で見づらいが、1の位を見る以上、確かにアドレスは「一個づつ」進んでる事が分かる。
「文字の格納」と「1バイト」と言うのは、少なくとも古典的な意味だと密接な関係がある、って事だ(※4)。
そしてchar型以外の場合、定義に従って、アドレスを一つ進めても「何バイトかまとめて」進む。これがCの「型」なんだ。
さて、ここでstrtok関数に戻る。
繰り返すが、C言語では文字列はオブジェクトじゃない。つまりC言語には文字列がない。
従って、strtok関数はモダンな言語のように「文字列を区切り文字で分割してる」ワケではない。
やってる事は、メモリ上で発見した「区切り文字」をヌル文字で順次置き換えていってるだけ、だ。
/* char* line[] = "My goodness," she said, "Is that right?" *//* メモリに配置された文字データ */{'"', 'M', 'y', ' ', 'g', 'o', 'o', 'd', 'n', 'e', 's', 's', ',', '"', ' ', 's', 'h', 'e', ' ', 's', 'a', 'i', 'd', ',', ' ', '"', 'I', 's', ' ', 't', 'h', 'a', 't', ' ', 'r', 'i', 'g', 'h', 't', '?', '"', '\0'}/* strtok(line, " .,?\"\n\"")を実行(1回目) *//* 最初の"をヌル文字で置き換えた後、ポインタを'M'に合わせ、次に区切り文字が出たトコロもヌル文字にする。 */{'\0', 'M', 'y', '\0', 'g', 'o', 'o', 'd', 'n', 'e', 's', 's', ',', '"', ' ', 's', 'h', 'e', ' ', 's', 'a', 'i', 'd', ',', ' ', '"', 'I', 's', ' ', 't', 'h', 'a', 't', ' ', 'r', 'i', 'g', 'h', 't', '?', '"', '\0'}/* strtok(NULL, " .,?\"\n\"")を実行(2回目) *//* ポインタをヌル文字を超えた場所(g)へと移動し、その後見つかった区切り文字をヌル文字に置き換える。*/{'\0', 'M', 'y', '\0', 'g', 'o', 'o', 'd', 'n', 'e', 's', 's', '\0', '\0', '\0', 's', 'h', 'e', ' ', 's', 'a', 'i', 'd', ',', ' ', '"', 'I', 's', ' ', 't', 'h', 'a', 't', ' ', 'r', 'i', 'g', 'h', 't', '?', '"', '\0'}/* strtok(NULL, " .,?\"\n\"")を実行(3回目) *//* ポインタをヌル文字を超えた場所(s)へと移動し、その後見つかった区切り文字をヌル文字に置き換える。*/{'\0', 'M', 'y', '\0', 'g', 'o', 'o', 'd', 'n', 'e', 's', 's', '\0', '\0', '\0', 's', 'h', 'e', '\0', 's', 'a', 'i', 'd', ',', ' ', '"', 'I', 's', ' ', 't', 'h', 'a', 't', ' ', 'r', 'i', 'g', 'h', 't', '?', '"', '\0'}/* strtok(NULL, " .,?\"\n\"")を実行(4回目) *//* ポインタをヌル文字を超えた場所(s)へと移動し、その後見つかった区切り文字をヌル文字に置き換える。*/{'\0', 'M', 'y', '\0', 'g', 'o', 'o', 'd', 'n', 'e', 's', 's', '\0', '\0', '\0', 's', 'h', 'e', '\0', 's', 'a', 'i', 'd', '\0', '\0', '\0', 'I', 's', ' ', 't', 'h', 'a', 't', ' ', 'r', 'i', 'g', 'h', 't', '?', '"', '\0'}/* strtok(NULL, " .,?\"\n\"")を実行(5回目) *//* ポインタをヌル文字を超えた場所(I)へと移動し、その後見つかった区切り文字をヌル文字に置き換える。*/{'\0', 'M', 'y', '\0', 'g', 'o', 'o', 'd', 'n', 'e', 's', 's', '\0', '\0', '\0', 's', 'h', 'e', '\0', 's', 'a', 'i', 'd', '\0', '\0', '\0', 'I', 's', '\0', 't', 'h', 'a', 't', ' ', 'r', 'i', 'g', 'h', 't', '?', '"', '\0'}/* strtok(NULL, " .,?\"\n\"")を実行(6回目) *//* ポインタをヌル文字を超えた場所(t)へと移動し、その後見つかった区切り文字をヌル文字に置き換える。*/{'\0', 'M', 'y', '\0', 'g', 'o', 'o', 'd', 'n', 'e', 's', 's', '\0', '\0', '\0', 's', 'h', 'e', '\0', 's', 'a', 'i', 'd', '\0', '\0', '\0', 'I', 's', '\0', 't', 'h', 'a', 't', '\0', 'r', 'i', 'g', 'h', 't', '?', '"', '\0'}/* strtok(NULL, " .,?\"\n\"")を実行(7回目) *//* ポインタをヌル文字を超えた場所(r)へと移動し、その後見つかった区切り文字をヌル文字に置き換える。*/{'\0', 'M', 'y', '\0', 'g', 'o', 'o', 'd', 'n', 'e', 's', 's', '\0', '\0', '\0', 's', 'h', 'e', '\0', 's', 'a', 'i', 'd', '\0', '\0', '\0', 'I', 's', '\0', 't', 'h', 'a', 't', '\0', 'r', 'i', 'g', 'h', 't', '\0', '\0', '\0'}
/* strtok(NULL, " .,?\"\n\"")を実行(8回目) *//* ポインタをヌル文字を超えた場所へと移動しようとするが、元の文字列の終端を超えるんで、NULLを指し返す。*/{'\0', 'M', 'y', '\0', 'g', 'o', 'o', 'd', 'n', 'e', 's', 's', '\0', '\0', '\0', 's', 'h', 'e', '\0', 's', 'a', 'i', 'd', '\0', '\0', '\0', 'I', 's', '\0', 't', 'h', 'a', 't', '\0', 'r', 'i', 'g', 'h', 't', '\0', '\0', '\0'}
繰り返すが、C言語のstrtokは文字列と言うオブジェクトを区切り文字で分割してるわけでも何でもなく、見つかった「指定された」区切り文字をヌル文字で破壊的変更するだけ、だ。
C言語の「文字列モドキ」は配列で、って事は剥き出しのメモリで、
- 「配列」と解釈される先頭のアドレスしか把握していない。
- 「文字列」と解釈されるには最後がヌル文字でなければならない。
と言うルールの下、あるメモリのアドレスから1バイト毎に調べていった際、ヌル文字を発見した時点で「そこで文字列としての解釈は終了」と言う単純な仕組みなわけだ。
しかし、そうすると、上で紹介したプロセスの8番はちと不思議だ。区切り文字をヌル文字で置き換えようと何だろうと、ヌル文字を「飛び越える」事をstrtokは行っている。そうすれば、指定された文字列を超えても動作し続ける可能性があるんじゃないか。
ぶっちゃけた話、仕様的には「こういう結果を返してくれ」と言ってて「実装でこうしてくれ」とは書いてない。んで、例えばgccのソースコードなんか調べてみるとある種インチキをしてて(笑)、「C言語実装内のライブラリ関数」の筈なのに、外部ライブラリのglibcの力を借りている(笑・※5)。そしてglibcはPOSIX準拠(つまり「公式」UNIXシステムの約束事)のライブラリで、要はこれ自体がUNIXと言うOSの力を借りてるんだ。
要は、他の実装がどうだか知らんが、ある意味フリーのCコンパイラの標準、って思われてるgccのstrtokは「C言語内で解決してる」実装にはなってない、って事だ。
まぁ、そんなワケで、「仕様は動作を定義しては」いるんだけど、「どう実装してんのか」は定義してないわけで、この辺突っつくと藪蛇なんでスルーしておこう(※6)。
いずれにせよ、「良くあるstrtok関数の使い方」だと全く旨味がないんで、やっぱ配列に代入したりする、ってのが「望ましい実例」になるんじゃないだろうか。

もう一度、ポインタの操作、と言うのを考慮しよう。strtok関数は区切り文字をヌル文字で置き換えた後、取り敢えず現時点での先頭のアドレスを返すわけだ。それをwordと言うポインタ変数が受け取る。そしてchar型へのポインタで構成されるwordsと言う配列にそのアドレスが渡される。
結果、wordsと言う配列は「アドレスを要素とした」配列、って事になる。
また、最初の例でも分かるように、通常、「strtok関数の使い方」で紹介される例では、strtok関数の初回起動がまずあって、その時、分割したい文字列を渡す。二回目以降はwhileでループしつつ引数にはNULLを渡す。
一方、関数型言語観点から言うと、実はこの「初回起動」と「二回目以降」を分けて書くのは無駄だ。そう、実は三項演算子の出番だと思う。
forを使ったのはそれが理由で、
word = strtok(count == 0 ? line : NULL, SEPCHARS);
と一行で、「count変数が0の時は引数にlineを与えて、それ以外ではNULLにせよ」と指定出来る。
この方がスマートだろう。
同様に、配列wordsの出力で、Pythonのリストっぽい出力を形成しているのも三項演算子の機能だ。

文字列の書式指定子として%sが3つ並んでる。真ん中はwords[count]の値が入るが、最初はcountが0の時は"["、そうじゃない時はスペースが入り、また3つ目はcountが6以下の時はカンマ、それ以外の時には"]"が入る。
そうすれば、「Pythonっぽい見かけをした配列のスタイル」で出力可能なわけだ。
Next line? (empty line to quit)
"My goodness," she said, "Is that right?"
That line contains these words:
["My", "goodness", "she", "said", "Is", "that", "right"]
C言語で「三項演算子を使うな」って人は多いが、使い方さえ間違えなければ強力な機能でシンプルに書ける。要は「三項以上になった場合」は使わないようにした方がいい。それだけ、なんだ。
三項演算子は畏れない方がいいと思う。少なくとも個人的にはそう思ってる。
上で「配列に切り分けたトークンを代入する」例を見たが、しかしながら、それでもスペック的にはLispのそれには及ばない。何故なら「配列の長さが7になる」ってのは決め打ちで、要はこれは「可変長配列が無い」C言語の欠点、とも言えるから、だ。「任意の長さを持った文字列」を自在に切り分けたモノをデータとして返す、と言う事はいまだ出来ないわけだ。
結果、やっぱリストが欲しい、となり、自分で連結リストを実装するか、あるいはGLibで提供されているGSListなんかを導入して使った方が良い、って話になるだろう(※7)。

GLibの特徴は、基本的に「GLib内で定義されている型を使う」事だ。結果、char型はgchar型にした方がいいし、char*はgchar*になる(これらは一種のエイリアスだ)。
また、関数に於いてはGLibで定義されたモノを使った方が良いようだ。結果、printfがg_printに置き換わっている。
/* GSList の宣言 */GSList* words = NULL;
これはRacketで言う
(define words '())
やPythonで言う
words = []
と言うのに近い。
そして次の段階で、strtokで分けられた単語をGStringに変換しつつリストwordsに格納していってる。

実はこの作業自体は、LispよりPythonの「望ましくない」リスト操作に近い。
# Pythonでのappendを用いたリスト操作words.append(word)
なお、ここでは、wordとして切り取られた文字列(実際はstrtokが返すアドレス内の値の型)をg_string_newと言う関数を用いてGStringと言うGLibで定義された「文字列オブジェクト」へとコピーしながら変換してる。
GStringは、これがまたクソメンド臭い事に、出力する際このままでは使えない、っつー厄介な性質があるんだけど、「素のC言語で言う(いわゆる)文字列」よか安全なように「構造体」として定義されていて、ちとパスカル文字列っぽい。
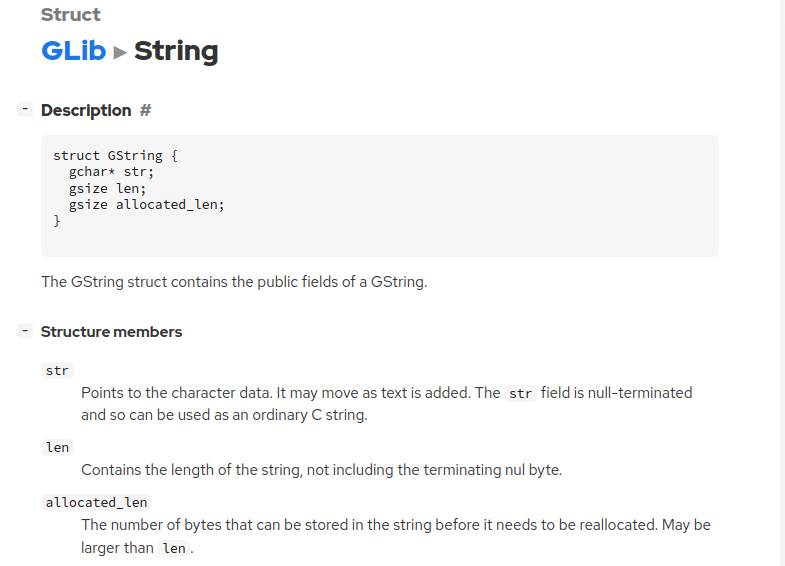
つまり、GStringと言う「型」には「文字列の長さ」と言う情報が含まれる、って事だ。プログラム側はGStringと言う構造体のlenと言うフィールドさえ見ればその文字列の「長さ」を把握出来る。
でもGStringを作る際、一々文字列の「長さ」を勘定するのもメンドいんで、C言語の素の「文字列」をg_string_newに手渡せば諸々の面倒を自動で見てくれる、ってわけだ。
これでwordsと言うリストにstrtokで切り分けた「文字列」が格納出来た。この時点で「データオブジェクト」が生成されたんで、あとは自在に調理が可能だ、ってわけだ。素のC言語のまま、より遥かに強力な機能を提供するのがGLibなんだ。
一応、取り敢えず出力はしてみている。この部分だ。

ここでは新しくGSListとしてiteratorと言う変数を作り、リストwordsをコピーしている。そしてiteratorがNULLになるまで、iterator->nextしていってる。
ちとピンとこないかもしんないけど、Lispで言うcdrダウン、あるいはPythonでのスライス操作に近い。
;; Racketで言うとこんなカンジ
(let loop ((iterator lst))
(if (null? iterator)
...
(loop (cdr iterator))))
# Pythonだとこういう操作に近いiterator = lstfor nxt in iterater:...
そして変数iteratorからフィールドdataを取り出して印字したいトコなんだけど、例によって型変換が煩わしい事になっている。
OCamlのリストなんかだと「型が何か」決まってるし、単一の型しかデータを入れられない。そういう意味だとGSListはLispやPythonのリストに近いだろう。
GSListの「要素」はdataフィールドで、そこの型は「void *」型、と言う型になってて、「何でも突っ込める」わけだが、逆に言うと「型がキチンと決定されてない」んで、解釈時に「解釈出来ません」って事になるわけだよな。
そこで、iterator->dataで取り出した「参照先」をGString型と確定させ、そしてその「中身」を参照するようにキャスティング(型変換)するわけだ。
GString型の「中身」がどうなってるのか判別されれば、そこに出力に利用したいstrと言うフィールドがある事も分かる。そしてstrの型はgchar*だ。
ここでやっとこさ、g_printに手渡せて印字出来ると言う・・・はぁ、クソメンドクセ(苦笑)。
いずれにせよ、これによってコンパイルが通って、次のように表示が出来るわけだ。

最後に生成したリストで使われたメモリを解放する。
g_slist_free(words);
この作業が、LispやPythonでの「ガベージコレクタ」が自動でやってる部分だ。Cにはガベージコレクタが無いので、こうやって手作業で解放しないといけない(※8)。
さてさて、如何だったろうか。ザーッとC言語の「文字列の仕組み」、そしてstrtokとGLIBを使いながら「メモリ」や「ポインタ」を説明して来たつもりだが。
分からなかったら分からんでエエ。高級言語は繰り返すが、本来、「ハードウェアの動作を隠蔽する」のがその役目だ。ラクなプログラミングツールがあるのに、わざわざ「ハードウェアの動作を理解しに」降りていかなくても良いと思う。
とまぁ、今回の記事はこれはこれで役目を終えたので、これで終了する。
※1: この例はCリファレンスマニュアルに依る。
 | S・P・ハービソン3世とG・L・スティール・ジュニアのCリファレンスマニュアル ハービソン,3世,サムエル・P. エスアイビーアクセス |
以前も書いたけど、2023年現在の日本に於いては、K&Rを買うんだったらこっちの本を買うべき、だ。
CリファレンスマニュアルはISO C99の頃に書かれた本だが、ISO C99と言う過去の規格に現行のJIS Cが準拠している。同じ「リファレンス代わりの本が欲しい」と言うなら、従って、いずれにしても現行仕様と食い違ってるK&Rよりこちらを優先すべきだ。
なお、これも何度か書いたが、Cリファレンスマニュアルの著者の一人、G・L・スティール・ジュニアと言う人がプログラミング言語Schemeの発明者の一人で、それだけではなく、MIT時代から「仕様書をまとめてリファレンスを作り上げる達人」として知られていて、その筋では一目おかれるハッカーとして有名だった。
また、Sun MicrosystemsでJavaの開発助力者としても働いている(Javaの言語仕様書にその名を見る事が出来る)。
※2: 繰り返すが、ポインタ変数宣言時の*とポインタ使用時の*は全く別の機能だ。後者を間接参照演算子と言う。
※3: これも繰り返すが、char型は「1バイトの量」を表すが、1バイトが何ビットなのか、と言う正確な定義はない。1バイトは環境により変わる。
ただし、工業的な理由により、現在では8ビットを1単位として作成されているメモリの方が多く、仮に「20ビットを1単位とするメモリを作ってください!」と製造会社に頼んでも「コストがかかりますよ?」と言われる羽目になるだろう。
つまり、安価で市場に溢れている「商品」を扱うのがコストレダクションでは最重要で、結果、現実問題、「1バイトが8bit」と言うのは規格ではなく、メモリ製造工場の都合で決まってる、って見た方がいい。
※4: 文字コードとバイトの関係も難しい。どの文字コードにするのか、と言うので解釈がまるで変わるから、だ。
ASCII文字は8bitと言う「量」とアルファベットをうまい具合に結びつけた。
一方、英語以外だと色々と面倒な事になる。
現時点で分かってるのは(1バイトを8ビットとして)、4バイトもあれば世界中の文字を全部表現する事が可能だ、と言われている。実用範疇で2バイトもあれば充分だろう、と。
そんな「過去の」分析により、JISのC言語、及びC99ではワイド文字、と言う型が提案されている(wchar_t)。つまり、結構な確率で処理系が上手くは処理してくれるが、厳密には「日本語を扱い表示したい」場合はwchar_tを使うべきだ、と言うのが過去の論法だった。
一方、厄介なのは、現在の「国際標準」になってるUTF-8で、これは実はデータ的には可変長文字で、文字により、使うバイト数が増えたり減ったりする仕組みだ。C言語はJIS仕様上、この「可変長形式の文字」には対応していない。
※6: 単純な発想ではstrtok関数の内部に複数のポインタがあり、初回起動の際に元々の文字列の最後のヌル文字があるアドレスを記憶しておいて、別の「文字列の先頭を表す」ポインタが保持するアドレスが、そのアドレスを超えた際にNULLを送出する、と言う仕組みが考えられる。
ただ、この辺はやっぱり「実装次第」なんで、「共通の結果を返す」のなら内情は不明だ、ってのはあり得るだろう。
※7: やっとこさ、辛うじてGLibの使い方が分かってきた。そのうち記事を書くかもしんない。書かないかもしんないが(笑)。
いずれにせよ、GLib リファレンスマニュアルがホントクソで(笑)、検索はしづらいわ用例は書いてないわ、ってぇんでてんてこ舞いだ。書いたやつが眼の前にいたら「ぶっ殺すぞ」って言うレベルだ。
※8: 過去にはGLibとガベージコレクタライブラリ、boehmGCの組み合わせテクニック、ってのがあったが、あまり上手く動かなかったようでGLibでは非推奨になった(残念!)。
なお、GaucheのGCがこのboehmGCだ。