C言語を学んでもプログラムは書けない。
悪口じゃない。マジでそうなんだ。
多分素人さんが想像するに、
「プログラミング言語を覚えたらプログラムが書けるんだ!」
とか思ってるかもしんないけど、C言語に於いては違うんだ。
大学なんかでは「C言語の使い方を学んだ」あと、大体「データ構造とアルゴリズム」なる授業を受ける筈だ。
実は「C言語入門」と「データ構造とアルゴリズム」は合わせてワンセットだ。
「機能が貧弱な」C言語だけではどうしようもないんで、自分で「データ構造」を作れるトコまで行かないといけないんだ。
独習でC言語を学ぶ人が躓くのがここだ。「C言語の教科書」だけじゃなく、「C言語を使ったデータ構造の作り方」を学ばなアカン、って事を知らん。もう一冊教科書が必要になる。それを終えないと「マトモなプログラム」は書けない。だから「せっかくC言語を勉強したのに何も書けない」って人があとを絶たないわけだ。
「データ構造とアルゴリズム」では言っちゃえば、「自作ライブラリの作り方」をまずは学ぶわけなんだけど、結果、そればっかやってても「ソフトウェアの作り方」にはなかなか到達しない。
そりゃそうだ。ライブラリは「作りたいソフトウェアを実装する為に」使うわけで、ライブラリだけあってもどうしようもない。
結果、C言語と「データ構造とアルゴリズム」を学んでもエロゲ1本でさえ作れりゃしねぇ。
それが「学校のカリキュラム」の実態らしい。
Why I hate Cと言う文書がある。
Cでは基本が欠けているCが登場した70年代初期でさえ、アプリケーションにはテキスト処理、コマンドライン、ユーザー入力、設定ファイル諸々のニーズがあった。しかしながら、それらに対する基本さえ欠けているか、全くない。開発者に何度も何度も車輪の再発明を強要し、現実の問題解決の為のサポートルーチンを書かせる事に貴重な時間を費やさせる。
- 文字列
- 配列(メモリとポインタ、及びインデックスに対する構文糖衣は含まない)
- ハッシュテーブル
一体何度連結リストを実装したのか、何回動的配列やリストの類を作ったのか、ちょっとでも考えてみたら酷いだろ?
ホントの事を言うと、Pascalも全く同じと言えば同じだ。
ただし、Pascalは元々「教育目的で作られた」言語だ。実際のエンジニアリングは考慮してなかった。大体、「Pascalに何でもあったら」学生に出す宿題が無くなってしまう(笑)。
そしてヴィルト先生自ら書いた本が売れなくなってしまう(笑)。
 | アルゴリズム+データ構造=プログラム <コンピュータ・サイエンス研究書シリーズ 40> 片山卓也 訳 日本コンピュータ協会 |
と言うのは冗談だが(笑)。
しかし、件の文書は「現実的なエンジニアリング言語である」C言語に文句を言ってるわけだ。「現実的なエンジニアリング言語」とすれば「中身が無さ過ぎ」だと。
しかし、通常、「外部ライブラリ」があれば何とかなる事が多い。
ところが、Cにはそのテの外部ライブラリが無い。どこまで言ってもDIYが基本だ。
CにはPerlのCPAN、Rubyのgem、Pythonのpip、Racketのpackageがない(※1)。
いや、本当は外部ライブラリはある。GLIBと言うのは「存在だけは」有名だ(※2)。
GLIBはハッシュテーブル、文字列、連結リスト、2分探索木等を提供する。僕らがプログラミングに於いて「喉から手が出るほど」欲しかったモノだ。
なんだ、キチンとあるじゃない。
ところが、以前見たが、GLIBにはマトモなチュートリアルが存在しない。チュートリアルが無いようなライブラリは使いようがない。なんつー敷居の高さだ、となる。
Pythonを初めて見た人とか、データ型の数の多さに面食らったと思う。
しかし、あれだけのデータ型があるのはプログラミングに必要だから、だ(※3)。
いや、実際は「多くない」んだ。確実に必要になるデータ型の集合をPythonは提供している。
また、「Lispは実用的ではない」と言われるが、素のC言語とANSI Common Lispを比べると「冗談だろ?」とか思う。ANSI Common Lispには「何でもある」。PythonなんかもANSI Common Lispに標準装備されているデータ型群を参考にしてライブラリを作ったんじゃねーの?って程ANSI Common Lispは「エンジニアリング目的の言語」としては完璧だ。Schemeはともかくとして、「Lispは実用的ではない」と言った人はあまりANSI Common Lispを知らんのだろう(※4)。
いずれにせよ、C言語を使って「マトモなプログラムを書けるようになる」にはメチャクチャ時間がかかるわけだ。Lisp辺りの「すぐ関数を作れちゃって、すぐ実用に耐えるプログラムを作れるようになる」、と言うのとは大違いだ(※5)。
従って、「C言語入門」辺りで出されるような練習問題、あるいは宿題なんぞはハッキリ言って「クソの役にも立たない」稚拙な、プログラムとは呼べないようなプログラムばっか、となる。
繰り返すが、原因は「C言語にはデータ型がない」からだ。極端に言うとC言語には数値とポインタしか無いんだ。だから「マトモなプログラムを書く」にはDIYでデータ構造をまずは作らないとならない。言い換えると、C言語は「データ型を作成する材料しか提供していない」。
つまり、C言語入門時点だと「データ型がない」以上、「再利用可能なプログラムは作れない」と言う事だ。ユーティリティやライブラリが作れない。「書き捨てのスクリプト」しか作れないんだ。
一方、Lispや(マトモな入門書があれば)Pythonなんかだと速攻で「データ型を弄ってデータ型を返す」プログラムが書ける。と言う事はどんな小さなプログラムだろうと「再利用が出来る」可能性がいつでも存在する。
この辺が決定的に違う。
この辺りの話も以前書いた。C言語はそのままじゃ何も出来ない言語なんで、とにかく「出力しろ」と結んで終わる宿題が多い。そして「出力する」以上、単純には再利用は出来ない。再利用出来ない割にはコーディングはメンド臭い。そして「出力する為だけに」苦労する、と。
これほど、プログラミング初心者に「無駄な事」ばっかやらせる言語はそうそうないだろう。だってそうだろ?書くのがメンドい割には出力「だけ」で終わるんだ。何の役にも立ちゃあしない。
「データ構造とアルゴリズム」を学ぶまでは。
さて、最近のネタでは「C言語はプログラミングの基礎」と言う妄言を徹底的に攻撃しているが。
LispやPythonでの「プログラミングの考え方」の方が基礎にふさわしいのでは、と言うのが今回のネタだ。
ちょっと教えて!gooの方で適したネタがあったんで、それを紹介しよう。



さて、これを一体どうやって解くのか。ちょっと考えてみて欲しい。
なお、ラテン方陣に付いてはWikipediaを参照して欲しいが、単純には
1 2 32 3 13 1 2
とか
1 2 33 1 22 3 1
みたいに、行と列に於いて「重複した数値(ないしは文字)」がない方陣だ。ある意味「数独でお馴染み」だよな。
また、同じ数値のパターン「1、2、3」を使ってる場合、上で見たように「2パターン」のラテン方陣が考えられる。故に
これは答えは何通りもある
と訊かれれば答えは「YES」にはなる。
しかし、出題が曖昧な以上、Wikipediaで書かれてた「標準形」を採用していいと思う。すなわち、
第1行および第1列が自然な順序で並んでいる
前提としよう。つまり、上の2例だと1つ目のパターンを採用する。少なくともそれに準じるカタチ、にしてみようか(と言うのも、入力が「自然な順序」か分からないし、ソーティングするのも面倒なんで省く)。
さて、暫く問題を眺めて、「自分ならこうやって実装する」ってのを考えてみて欲しい。
思いついた?
まだ思いつかない人の為にヒントをあげよう。
3×3のラテン方陣をつくるプログラム
って書いてるが「本当に"つくる"のか?」ってのがヒントだ。
LispやPythonのようなモダンなプログラミング言語だと、いっつも言ってる通り、「ラテン方陣を表すデータを作り」それを返すべきだ。そうすれば、「ラテン方陣を作る」ユーティリティなりライブラリを作った事になり、それを再利用出来る。
ただし、「C言語の問題」は上に書いてきたように「違う」んだ。ラテン方陣と言う「データ」を作りたいんじゃない、「表示さえすれば」O.K.なんだよ。
すなわち、ラテン方陣と言うデータを作成する必要はない、んだ。
あくまで表示だけ、だ。表示を何とかしたい、と言う事だけ考えよう。
では考えてみてくれ。
さて、思いついただろうか。
ちなみに、僕はこのテのC言語脳臭い問題を見る度に、毎回毎回、「どーやって手抜きしてやろうか」って考えるんだ。
で、ハッキリ言っちゃうと、恐らくC言語のエキスパート、Cハッカー達も似たような回答を作るんじゃないかな、って思ってる。
何も僕がCハッカー並にアタマがいい、って言ってるわけじゃない。凡百のC言語脳は単なる頑迷なイカレポンチだが、Cハッカーはマジでアタマがいい。要は僕程度が思いつく事は簡単に思いつくだろう、って言ってるんだ。
言い換えると、凡人のワタクシでも、LispやPythonを経由すればC言語エキスパートに掠る程度のアイディアを得る事が出来る、って言ってるわけだ。
それが「モダンな言語を思考のツールとする」利点だ。
ポイントは「ラテン方陣の形式」に騙されてバカ正直に二元配列の類を作らん事。二元配列を作ればループも二重ループにせなアカンくなる。
そんな事をすればコーディングが煩わしくなる。
質問者のコードを見てみよう。「出力だけする」のに二重ループを使ってる。
そっちに行けば「面倒なだけ」なんでダメなんだ。
さて。例えばここで1, 2, 3と入力されたとする。何らかの処理を行ってリストを生成する。PythonとRacketだったら次のようなカンジになるよな。
# Python['1', '2', '3'];;; Racket'("1" "2" "3")
このリストを次のようにするんだ。
# Python['1', '2', '3', '1', '2', '3'];;; Racket'("1" "2" "3" "1" "2" "3")
入力から生成したリストを2つにして繋げる。
そして|が出力範囲を表すとしたら、
# Python[|'1', '2', '3'|, '1', '2', '3']↓['1', |'2', '3', '1'|, '2', '3']↓['1', '2', |'3', '1', '2'|, '3'];;; Racket'(|"1" "2" "3"| "1" "2" "3")↓'("1" |"2" "3" "1"|"2" "3")↓'("1" "2" |"3" "1" "2"| "3")
と、ルーピングで表示範囲をズラシていくだけで「ラテン方陣」として出力が成り立つ。
言われてみれば簡単だろ?
そしてこの形式で書けば別に二重ループなんぞ使う必要がない。要は「面倒なコード」なんぞ書かないで済むんだ。
さて、C言語だとどう書くか。
いや、発想は簡単なんだけど、例によって「C言語特有のめんどくささ」がある。
取り敢えず、C言語のコードを書く際の雛形は必ずこうなる、って事を覚えよう。

- 必ずstdio.hとstdlib.hの2つは#includeする。前者は標準入出力のライブラリ、後者は標準ライブラリで、この2つは絶対に必要だ。
- main関数の返り値の型はintだ。これも必ず付けるように。
- main関数を無引数で呼び出すのなら引数にはvoidを設定する。なお、main関数以外の関数でも無引数で呼び出せるモノには必ずvoidを設定する。()と空カッコではいけない。
- そしてmain関数の最後は必ずreturn EXIT_SUCCESS;とする。これも意味を明解にする為で、決してreturn 0;等にしてはいけない(マトモなIDEなら#include stdlib.hした時点で補完してくれる筈だ)。
まずこの4つを覚えよう。
なお、main関数だが、ある種これはC言語特有の言い回しなんだけど、ここだけ名前が決まっていて役割が決まってる。
C言語のプログラムはすべて「main関数を経由して」実行される。他の、例えばPythonやRacketで作るような関数はすべて「サブ」なんだ。
アセンブリ言語では「ここからプログラムが始まります」と言う一種タグを「エントリポイント」と言って、そこで主に使われる「名前」がmainだ。これは要は「メインルーチン」を意図してる。そしてフツーの「関数」はすべて「サブルーチン」だ(※6)。
Cはそういう「アセンブリ言語でのお約束」を引き継いでいるわけだ。
さて、次はユーザー入力なんだけど、Cの場合マトモな入力関数が存在しない。
通常、端末から入力を読み取る際、それは文字列になっている。文字列は「実行できない」ので、安全性が高いからだ。Pythonのinput関数はユーザーからの入力を文字列として返す。Lispでは通常、readではS式を読み取り返すが、Racketのread-lineはPythonのinput関数同様にユーザーからの入力を文字列として返す。
一方、C言語の場合、「ユーザー入力をメモリに書き込む関数」しか存在しない。
従って、まずは「ユーザー入力を書き込む」メモリを用意しないとならない。
char buffer[2048] ;
これで2048個のchar型の要素を持った「配列」を宣言出来た。っつーか、C言語では「配列は配列を意味しない」事を思い出そう。単にメモリを使う、って宣言しただけだ。
この後、3つ程方針がある。
この順番でオススメだ。
1番はぶっちゃけ、配列を用意する必要さえない。readlineを使えばPythonのinput関数よろしく、プロンプトを与えてユーザー入力を文字列で返してくれる。
実際、UNIX系プログラムではこのreadlineの類を使って書かれたプログラムは数多い。
そう、今「UNIX系プログラム」と書いた。実はこれが最大の弱点で、Windowsで使える保証がないんだ。何故ならreadlineはUNIX系OSが提供してるユーティリティ、だからだ。
言い換えると、UNIX系OSを使ってるなり、あるいはWindowsでWSLを使ってプログラミングするなら、これがベストチョイスだろう。
2番は比較的安全なC言語の「読み込み」機能だ。今回はこれは使わないんで、使い方は紹介しない。検索すれば多分たくさん引っかかる。それくらいこれの愛用者は多いと思う。
この中で一番ダメなのがscanfだ。極めて危険な関数で、Cの歴史上、クッソ面倒を引き起こしている。
ところがこれを初心者に使わせよう、っちゅうバカがあとを絶たないんだ。何故に危険なブツを初心者に使わせようとするのか。
scanfは入力から文字や数値を受取り、与えられたメモリに書き込もうとする。これだけだと大した問題に見えないだろう。連続した入力があれば連続したメモリに書き込もうとする。
ところがだ。C言語の「配列」は単なるメモリだ。上のchar型の変数bufferは、2048個のchar型のデータを詰められるように宣言されている。しかし実際問題、C言語がやってるのは「どこからメモリを使うか」を指定してるだけで「どこを終端とするのか」は全く指定してないんだ(笑)。
つまり、char型のデータを2048個まで詰められる事は保証されてるが、2049個目を詰めようとした時、「それを止める手段」が「配列側」に存在しないんだ(笑)。言っただろ?C言語には高級言語で言う「配列」がねぇんだって(笑)。
そしてscanf。「自らの終端がどこにあるか分からない」配列に対して、こっちはこっちで、素のままだと「読み込みの長さ」が指定できない。従ってこの2つのコンビは「想定した長さのメモリ領域」を飛び越えて、ユーザーの入力を延々と受け付けてしまう。・・・仮にそれが「悪意のあるプログラムからの入力だったら?」と。おっそろしい事になるのは間違いない。
この「想定した長さ」以降のメモリの中身まで書き換えてしまう事をバッファオーバーフローなぞと呼ぶ。C言語で書いたプログラム上のバグではもっとも恐ろしいバグの1つだ。そういうバッファオーバーフローを起こすプログラムの書き方を初心者相手に教えてるわけだ。バッカじゃねぇの?だ。
実は、scanfの第一引数は文字列なんだけど、性器正規表現を駆使した文字列を指定する事で、後ろの穴への挿入想定したメモリの長さを超えた部分への挿入を阻止する事が出来る。 => 参考: [迷信] scanfではバッファオーバーランを防げない
今回のように、空白文字で区切られた3つのデータ(例えば1と2と3)をまとめて1つの文字列として受け取る場合は、第一引数を性器正規表現を用いて
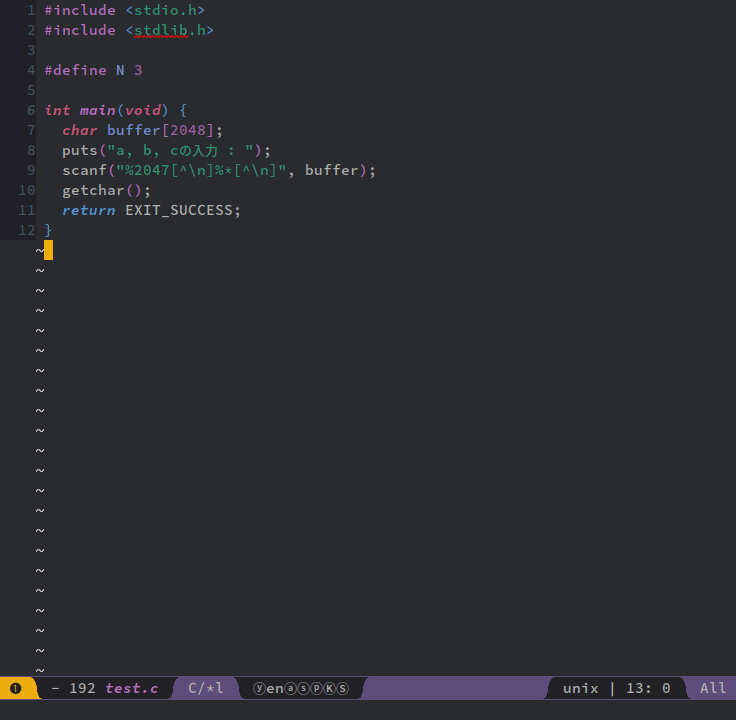
scanf("%2047[^\n]%*[^\n]", buffer);
と記述する。
1つ気をつけるのは、変数bufferは2048個分のchar型のデータを格納出来るが、scanf側ではそれより1つ少ない数を指定する事だ。と言うのも、配列(メモリ)には終端情報が無いが、いわゆる「文字列」には終端情報がある、ってのがC言語の特徴で、その「文字列のケツ」にはヌル文字、と呼ばれる文字を付け足す必要がある(※7)。

Null フフフ・・・(違
その一文字分を入力情報とはまた別に確保しとかなきゃなんない。
そして、scanfに纏わる作法はこれだけでは終わりではない。scanfは文字や数値(実質的には両者とも数値だが)を読み込むが、「改行を叩くことで」読み込みを終了する。
するが、以前Racketでも見たが、文字を入力する関数では、「改行を叩くと」ハードウェアの入力バッファに「改行文字が残る」と言う現象が起きる。よってそれを消費せねばならない。
そのため、最後は必ず
getchar();
する。これで入力部分は終了、だ(※8)。
さて、どうだ?
「C言語はメモリを意識してプログラミング出来る素晴らしい言語」だろうか(笑)。
いや、「C言語はプログラムを書く側がメモリの面倒を一から全部見なアカン言語」、ってのが実態に近い(笑)。ウッカリすると「バッファオーバラン」と言う極悪なバグが入力時に生じる、と言うトンデモ仕様なんだ。
ぶっちゃけた話、ユーザー入力なんざさせず、まずはコマンドライン引数を使うようなプログラムを書かせた方が初心者には優しい筈なんだが、C言語脳はそういうカリキュラムを組みもしない。
最悪の言語に最悪の教え手、そして最悪のカリキュラム、って言っていいだろう。
さて、入力機構を使って、例えば「1, 2, 3」と言う入力を受けたとする。
この時点で変数bufferは次のような状態になってる。
"1, 2, 3"
実際はC言語には文字列がないので、
{'1', ',', ' ', '2', ',', ' ', '3' '\0'}
と言うchar型のデータが詰まった配列だ(最後の'\0'は文字列の終端を示すヌル文字)。
これから"1"、"2"、"3"と言う数値の文字を切り分けたい。そうだな、トーカナイズだ。C言語ではstring.hに含まれるstrtok関数を用いる。当然意味はstring tokenizeだ。
しかし、この関数こそが使いづらい。クセがあって、C言語ユーザーにさえ嫌われてる程だ。
例えばほぼ同名称の、SchemeのSRFI-13に含まれるstring-tokenizeは、SRFI-14の文字セットを利用して次のように使え、結果もシンプルだ。
> (string-tokenize "1, 2, 3"
(char-set-difference char-set:graphic
char-set:punctuation))
'("1" "2" "3")
>
文字列を指定した区切り文字(セット)を利用して分割する。結果は「分割された要素を持った」リストだ。
これが大方の人の望む結果だろう。
ところが、素のC言語にはリストがない。よって「トーカナイズ」と言うにはあまりにもアレ、っつー事をやる。
単純に言うと、C言語のstrtok関数は次のような事を行う。
先程の「char型の配列」を見てみよう。
{'1', ',', ' ', '2', ',', ' ', '3' '\0'}
C言語で「文字列」と認識される為には
- char型の配列である事
- 文字列、と認識される要素群のケツはヌル文字である事
の2つが条件になる。
それで、strtok関数が行うのは、単純に言うと、「区切り文字」で指定された場所をヌル文字で置き換えていってるだけ、なんだ。
// 最初{'1', ',', ' ', '2', ',', ' ', '3' '\0'}↓// strtok関数適用1回目{'1', '\0', '\0', '2', ',', ' ', '3' '\0'}
上のように、strtok関数を一回適用すると、カンマや空白文字が区切り文字指定されてたとしたらカンマや空白をヌル文字で破壊的変更する。結果、C言語のシステムだと、「1」と言う文字があり、次がヌル文字なら"1"と言う文字列に解釈されるわけだな。
これを「自分で」ルーピングで回す、ってのがC言語のショボいstrtok関数だ。
唯一C言語のstrtok関数の優秀なトコは、区切り文字を複数指定出来る辺りで、その辺はPythonのsplitメソッドなんかよりよっぽど賢い(結果、Pythonで複数の区切り文字で文字列をトーカナイズしたかったら、性器正規表現に頼らざるを得ない)。
いずれにせよ、strtok関数は
// strtok関数適用2回目{'1', '\0', '\0', '2', '\0', '\0', '3' '\0'}
このように、区切り文字で指定された場所を、区切り文字「じゃない」文字が出てくるまで順次ヌル文字で置き換えていく。
いや、ちと待てよ、C言語の「文字列」のシステムだとヌル文字「以降」の文字は感知せんのじゃないか?って思うだろう。
正解だ。
ところが、C言語にはポインタがある。最初は開始地点として'1'を指し示してるわけだが、「ヌル文字より後ろにあるデータを開始地点にしろ」とズラせば'2'を発見、そしてそこから次に出てくる「ヌル文字」までを「文字列」って解釈するわけだ。
以下同文。
なかなかエゲつない仕組みだろ(笑)?
まず、次のように書く。
char* delim = ", ";
char* token = strtok(buffer, delim);
char* row[N * 2] = {NULL};
row[0] = row[N] = token;
ここで思考のショートカット、だ。C言語には文字列がない。しかし、char*と言う宣言は事実上文字列と考えていい。他の言語だとStringやstrと言う宣言にあたるのがchar*だ。
実際はchar*ってのは「char型データへのポインタ型」を意味するんだけど、それは忘れていい。数値なんかへのポインタと違ってcharへのポインタはちょっとだけ扱いがラクだ。ソースコード上で「文字列リテラル」を使うと自動でメモリを確保するし末端が自動でヌル文字になる・・・要は「文字列までメモリ操作塗れ」だとさすがに出力が扱いづらい、ってぇんでこうなってんだろう。
一行目はデリミタ、つまり区切り文字を指定する。strtok関数で使うんだが、ここでは「複数文字」を指定出来る。単純に文字列として複数の文字を並べときゃいい。ここではカンマとスペースを指定してる。
二行目で「初回のトーカナイズ」を行う。これがstrtok関数のややこしい辺りで、初回だけは独立して、第一引数にトーカナイズ対象とする文字列、第二引数にデリミタを指定する。そして返り値が「最初にトーカナイズされた」部分文字列(事実上、与えられた文字列の先頭のメモリの番地)となる(strtok関数を起動した時点で最初に見つかる区切り文字がヌル文字に置き換えられてる事を思い出そう)。それを文字列としてtoken変数に代入してる(と言うかそう解釈する)んだ。
三行目、で「文字列の配列」row変数を宣言してる。長さは3の2倍、つまり6を想定する。この辺はPythonやLispで見た通りだ。そして配列宣言時には初期化しておいた方が良いだろう。この例では「配列の全要素」をNULL(つまり何も指さない)で初期化している(※9)。
そして四行目で切り取ったtokenを配列の0番目と3番目の要素に同時に代入してる。これもPythonやLispで見た通りだ。入力の配列を2つくっつけたような配列を生成したい為にこのようにしてる。

次にstrtok関数をループして回す。
良くあるstrtok関数の例では、切り出すトークンがNULLになるまで、与えられた文字列を「完全に」トーカナイズする、が、この例題の場合は最大で3個のトークンを切り出すだけでいい。要するにループで回すのは結果2回分だけ、だ。

この程度だとベタ書きしてもいいんだけど、取り敢えず律儀にforでループを回す。
初回のトーカナイズは既に終了してるので、ループカウンタは(必然性はないけど利便性により)1からスタートする。
非常に不思議なのはstrtok関数での2回目からのトーカナイズだ。初回の書式は「切り分けたい文字列」を指定するんだけど、2回目以降はNULLを指定する。
これは、次に切り出すトークンの先頭のアドレスをstrtok自体が保持してるから、だ。そのために、第一引数で新しく文字列を指定すると次に読み出す為のアドレス情報がおかしくなってしまう。
言い換えると、他の高級言語だったらオプショナル引数で済むべきトコで、CはショボいからユーザーがみっともなくNULLを指定せなアカン話なだけだ(しかも自動でルーピングするわけでもなく、ユーザーにとことん手間をかけさせる)。
いずれにせよ、2つ目のトークンを変数tokenに代入(と言うよりstrtok関数が返す2つ目の文字列の先頭のアドレス)し、その後、文字列の配列rowの2つ目と5つ目の要素に同時に代入する。
それを3つ目のトークンを切り出すまで繰り返すわけだ。
これでPython/Racketで見た通り、変数rowは、例えば1, 2, 3と言う入力に対して
{"1", "2", "3", "1", "2", "3"}
と言う文字列の配列になる。

残りは基本的には簡単だろう。作成した文字列の配列、rowに対して範囲指定してprintfをぶちかませばいい。

要は
- rowの0番目、1番目、2番目を出力
- rowの1番目、2番目、3番目を出力
- rowの2番目、3番目、4番目を出力
すれば、3行3列のラテン方陣の出力が完了、だ。繰り返すが二重ループを作る、なんつーまだるっこしい事をする必要はない。
あとは、入力が全くない、とか3つのデータ以下だったらどう対処するか、ってぇのを考えるだけ、だ。
LispやPythonの場合、入力文字列をトーカナイズした段階で、生成されたリストの「長さ」が3なのかどうなのか、でラテン方陣の出力処理へ移るかどうか決められる。
一方、今まで見てきた通り、C言語にはリストがない、んで、トーカナイズの「完成品」がどうなのか、ってののチェックのしようがない。
また、文字列の配列rowを用意したが、長さは6だと決まっていて、可変長ではないわけだ。ここでも「配列の状況を見て処理を継続するかどうかを決める」と言うわけにはいかない。
結果、strtok関数が「これ以上トークンを切り出せない」時に投げてくるアドレス、NULLを頼って、NULLを返して来た際に、以降の処理を全部スキップして、main関数を終了してしまうのが一番簡単なやり方、となる。
トーカナイズ処理の際に、tokenがNULLの時に関数終了(return EXIT_SUCCESS;)直前にジャンプする。それをするのが悪名高きgotoだ。

ENDはreturn EXIT_SUCCESS;の直前にタグとして設定する。タグはコロンを引き連れるだけ、で設定出来る。
END: /* これでジャンプ先のタグ設定となり、ジャンプしてきたら以下の文が実行される */
return EXIT_SUCCESS;
これで終わり、だ。これでデータが3つ以下だった場合は、strtok関数はNULLを返すんで、そこで引っかかった時にはジャンプし、出力の部分をスキップし、いきなりreturn EXIT_SUCCESS;して、プログラムを終了する。
どうだろうか。「C言語だけで考える」よりはPythonやLispでまずは考えて「C言語にその思考プロセスで移植する」方が実際は簡単だ。
また、特にLispなんだけど、長い歴史の中では「Lispでまずはモックアップを作り」後にC言語で実装しなおす、ってのは重要なテクニックだったんだ。
実際それで試作されて現在ポピュラーになったツールとしてリレーショナル・データベースがある。これのオリジナル(※10)を作った人たちは「C言語で考え」なかった。最初はLispで考えてLispで作ったんだ。「モックアップが理論通りに上手く動く」事を確認してからCで実装しなおした。
このように、「最初からCを使って」「Cで考えて」「Cで実装する」よりはまずはLispでモックアップを作った方が色々と早いんだ。
Lispは手っ取り早く「試作品」を書くにはいい言語だ。また、Lispを使えば「問題のプログラムはどういうデータ型を利用するのか」把握するのも簡単だろう。
今回はそのテの話の実例だ。
なお、Cの全ソースはここに置いておく。
※1: PerlのCPANに影響を受けてCCANと言うのが成立したが、結果あまり流行ってない。
※3: Rubyも同様だ。1990年代初頭から中頃にかけて登場したこの2つの言語は、当時としては革命的に「豊富なデータ型」を提供してた。それまでの「C言語やPascalに遠慮して」(笑)な雰囲気は微塵もない。
なお、ANSI Common Lispの制定は1994年なんで、仮に参考にしてたとしたらANSI規格化する以前のCommon Lispを参考にしたんじゃないか、と思われる。
※4: ANSI Common Lispはアメリカ国内のローカル仕様だけど、Cの実装と同様に、商用・フリー合わせて数多くの実装がある。特にネイティヴコード(つまりアセンブリ/機械語だ)にコンパイルする処理系ではCに匹敵する程の実行形式を生成する。
また、「GUIに弱い」と言うのは一般的にはその通りだが、その「弱い」が弱点になるのなら、単に「C言語と同程度に」苦手だ、と言う事に過ぎない(Cも別にGUIが得意な言語ではない)。
※5: そのせいで、「かったるい事は何もない」Lisp学習だが、学習曲線が急勾配だ、と言う欠点がある。人間の記憶の定着には時間がかかるんだが、Lispの場合は「扱いが簡単な」せいで、あれよあれよと「詰め込まれる」危険性がいっつもある、って事だ。
※6: こういう説明は、昔のBASICを知ってる人の方がピンと来るだろう。
「昔のBASICを学んだ」人は、実は構文的にアセンブリ言語を学べる「下地」が付いてたんだ。
※7: これはポピュラーな「文字列解釈」の仕組みなんだけど、「唯一」と言うわけではない。他の言語だと他の「解釈」のシステムを採用している事は充分あり得る。
有名なトコではPascal文字列と言う仕組みがあり、これはC言語の「文字列解釈」と違って利点もあれば欠点もある(もちろんC言語風文字列も、だが)。
いずれにせよ、「配列に配置された数値」を「文字」として解釈し、その配列を「文字列」として解釈するのはなかなか悩ましい問題を抱えているんだ。
なお、char型のcharはCharacter(文字)から来てるが、事実上、char型は別に文字を意味していない。仕様上は1byte分の塊をchar型として定義していて、これも以前書いた事があるが、1byteが何ビットなのかは正式な定義はない。
現在デファクトスタンダードだと、1byte = 8bitになってるが、あくまでそれはデファクトスタンダードであって、実際は1byteが何ビットになるか、は使ってるシステムに依る。
要はC言語は「1byte」が何ビットになるか、は動いてるシステムに任していて、いずれにせよ「システムで定義されてる1byte」の量をchar型としてるんだ。
※8: 「何でもかんでもprintfする」C言語だが、書式指定子を含まない文字列を単に出力するだけならputs関数を使った方が良い。改行文字付きで出力してくれる。
なお、putsとはput stringの略だ。
Rubyで良く使われる出力関数(と言うか、Ruby用語ではメソッド)もputsで、これも名称はC言語から来ている。
また、ファイルの冒頭に付けられた #define 部分をマクロと言い、ソースコード上で記述されたブツを指定されたブツで置き換える。
この問題は3行3列のラテン方陣を扱う為、3と言う数値が良く現れる。よって大文字のNを見かけたら3に置換しろ、と指定してるのがこのマクロだ。
※9: NULLは特殊なアドレスで、「何もない」事を意味してる。変数rowは「文字列の配列」だが、その「文字列」はchar*と言うポインタだ。ポインタが「何もない」事を示すアドレスを指せば、それは単純に「今ここには文字列はない」と言う意味になる。
また、アドレスとしてのNULLと、文字としてのヌル文字は、紛らわしい事に「同じモノではない」。混乱しないように。
※10: 一番最初に実装されたリレーショナル・データベースはPostgreSQLで、モックアップはLispで書かれた。