お待たせ、今回のお題はみんな大好きハッシュテーブルだ。
ところで、ハッシュテーブルってのはプログラミング言語実装に「載るようになった」のは割に最近の方(ここ30年くらい)なんで「比較的新しい抽象データ型」と思われてるが、実は登場自体は結構古い。1950年代初頭にはIBMによって実装されてたらしいんで、最古の抽象データ型の1つ、って言って良いくらいだ。
いや、下手すれば二分木の研究・発展より早いくらいなんだよ。
つまり、ある意味、「コンピュータサイエンス上の秘技」っぽい扱いで長い間(それこそ30年くらい)秘匿されてたようなカンジだ。
そんな中で、「言語仕様にハッシュテーブルが含まれた」のは1980年代の、ANSI制定以前のCommon Lispが恐らく最初の、あるいは最初の1つだったんじゃなかろうか。Common Lispは当時の「研究室では当たり前だった」抽象データ型を「全部入りでマシマシ」するような勢いがあった言語仕様だったんだ。
いずれにせよ、その辺が皮切りとなって90年代登場の、Python、Ruby、JavaScript、Java辺りに搭載されるようになった(※1)。この4つの言語は割にLispの影響力が高い言語群だ。「Javaは違うんじゃね?」ってのは言語仕様上はそうなんだけど、少なくとも開発者陣はLisp関連を良くやってた連中だったわけだ。
ところで、これら、Common Lispを含んだ5つの言語を見ると、一番使いやすいハッシュテーブルを提供してるのはやっぱりANSI Common Lispだ。
何故ならLispにはシンボル型があるんで、キーに文字列リテラルを使う必要がない、と言う記述上の強力さがある。
次点がRuby/JavaScriptで、キーに配列を使ってもいい、と言うおおらかさ、がある。一方、Pythonの辞書型では、キーにリストは使えない。
ここまでは動的型付け言語で、数値、文字列等、キーの型の混在が可能だ。
一方、Javaは厳しく、静的型付け言語なんで、ハッシュテーブル生成時に「キーの型」も「返り値の型」も最初に決定し、「型の混在」は不可能だ。
そう、「言語仕様上ハッシュテーブルを搭載した」順を考えると、実はハッシュテーブル自体は「動的型付け言語」の方が相性が良さそうに思う。静的型付け言語だと「型が決まってないといけない」んで、どんな型のキーでも、どんな型のデータでも格納出来る、とはいかない。
結果、利便性が落ちるわけだ。
GLibが提供するGHashTableはJavaよりは若干緩いが、基本的にはJavaのように「キーの型」を最初に決め、動的型付け言語のそれらよりは利便性が落ちる、って事が前提となる(※2)。
GHashTableは次のようにして使う。
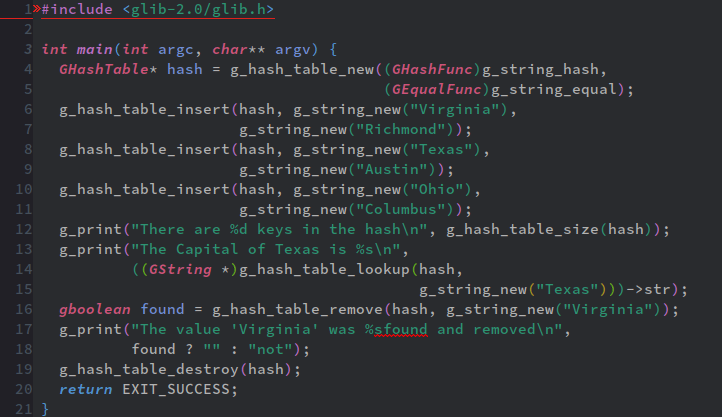
まずハッシュテーブルを生成する関数はg_hash_table_newだ。
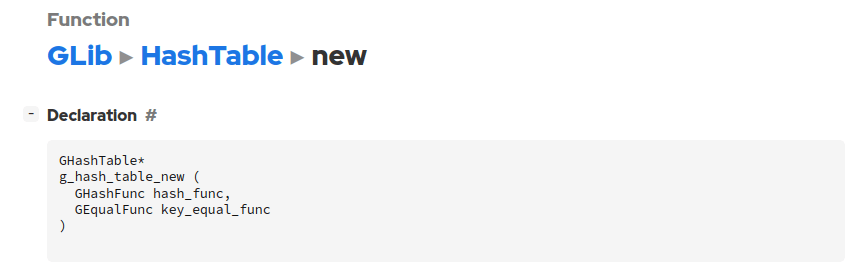
g_hash_table_newは二引数関数で高階関数だ。引数に与える関数はハッシュ生成関数と等価判定関数だ。
「ハッシュテーブル生成関数」が「ハッシュ生成関数」を要するのはヘンな気がするが、g_hash_table_newはあくまで「ハッシュテーブルとしてのガワ」を生成するのに対し、例えばg_string_hashはあくまでGString用のキーを生成する「ハッシュ関数」となる(つまり、事実上「ハッシュ関数のルールに従って」キーとなるgint型の整数を生成する)。
等価関数はそのまま、キーが指定されたキーと一致するかどうか調べる関数だ。上のコード例だとGString同士を比較する為にg_string_equalを使っている。
さて、g_string_hashはgint型を返すし、g_string_equalは真偽値であるgbooleanを返す。このままだとg_hash_table_newは受け取れないんで、前者をGHashFunc型、後者をGEqualFunc型へとキャスティングしないとならない。両者とも高階関数(モドキ)用のcallbacksで定義されている。
やれやれ、メンド臭いね(笑)。
g_hash_table_insertはGHashTableにkeyとvalueのペアを挿入する。第一引数には対象のハッシュテーブル、第二引数と第三引数それぞれにkeyとvalueが入るが、型はgpointer、つまり実質的にはvoid*型なんで、どんなデータ型でも受け渡せる。
んで、ここがANSI Common LispやJavaと似てるんだけど、例えばPythonのように
hash = {"Virginia" : "Richmond",
"Texas" : "Austin",
"Ohio" : "Columbus"}
と初期化と複数のkeyとvalueのペアを一気に設定する事は出来ない(※3)。
残りは、
- g_hash_table_size(GHashTable* hash_table): hash_tableに含まれるデータ個数を返す。返り値は符号なし整数であるguint型。
- g_hash_table_lookup(GHashTable* hash_table, gconstpointer key): hash_tableからkeyに対応したvalueを返す。ただし、返り値はgpointer型で、型はプログラマが指定しなければならない。見つからなかっった場合はNULLアドレスを返す。
- g_hash_table_remove(GHashTable* hash_table, gconstpointer key): hash_tableからkeyとそれに対応したvalueを削除する。返り値はgboolean型(真偽値)で、削除が
性交成功したらTRUE、keyとvalueのペアが発見出来なかったらFALSEを返す。 - g_hash_table_destroy(GHashTable* hash_table): hash_tableを破棄する。単純にはGHashTable用のfree関数だ。
だ。

なお、ハッシュ関数と同値判定関数のコンビは整数用のg_int_hash /g_int_equalやgpointerを使う(つまり、自分で型を確定しなきゃならない)g_direct_hash/g_direct_equal等がある。
続けていこう。
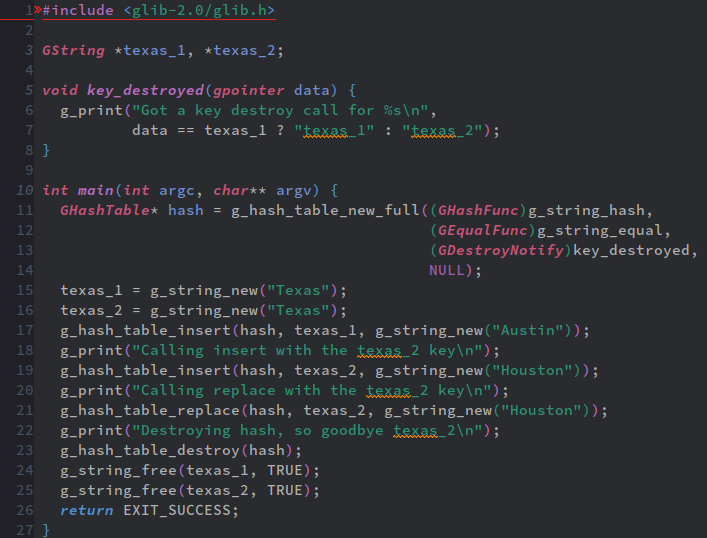
なお、3行目だが、C言語にあまり詳しくない人に説明しておこう。ここではポインタ変数を2つ宣言している。
実はC言語ではポインタ変数を複数宣言する場合、こうは書けないんだ。
GString* texas_1, texas_2;
こう書くと、texas_1はポインタ変数になるが、texas_2は単なるGString型の変数となる(そして、GStringの性質により、それじゃ意味がない)。
ハッキリ言うと、これがC言語設計のミスの1つだ。
これが故に一貫した書き方をしたい、って人はポインタ変数を1つ宣言するにせよ
GString *texas;
と変数側にアスタリスク(*)を付ける宣言にするわけ。
ところが、こうすると、実際使う際の間接参照演算子と紛らわしくなるわけだな。
いずれにせよ、個人的には、ポインタ変数宣言時には
GString* texas;
と書く方が好みだが、複数ポインタ変数を宣言する際には「形式を変えな」アカンくなるわけだ。
なお、Pascalだったら、
vartexas_1, texas_2 : ^GString
のように「複数の変数を一気にポインタ変数として宣言可能」で、この辺でもPascalの方が一貫した表記が可能となっている。そして何度か指摘してるが、実はコンピュータサイエンス上はPascalのように型は変数を後方から修飾するのが正しい。
C言語方式は間違ってるんだ(RustはC言語系だけどここが直されている)。
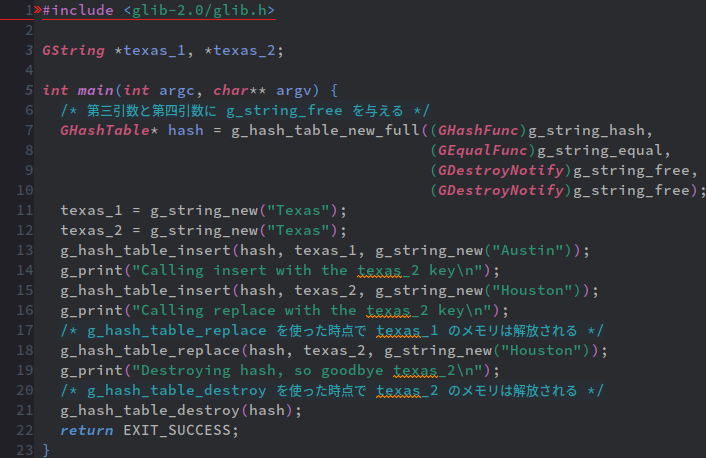
さて、g_hash_table_new_fullだが、これはg_hash_table_newと基本的には同じだが、4引数関数になっている。で、第三引数と第四引数はそれぞれ、keyとvalue用のfree関数を指定できる。
何故こんな機能があるのか、と言うと、そもそもハッシュテーブルと言うのは破壊的変更前提のデータ型だ。
ところが、C言語だと、この例のように外部的に変数を設定して、それをハッシュテーブルに食わせて破壊的変更しまくるとハッシュテーブル側は問題ないが、例によってメモリがどんどん食いつぶされていく。ハッシュテーブルが肥大化するわけじゃないが、ハッシュテーブルから削除した筈のデータは相変わらずメモリ領域を専有したまんま、なんだ。
つまり、ハッシュテーブルからデータを削除した時点でメモリを解放したい、と言う用途に応える為、g_hash_table_new_fullがあるわけだ。
また、上の例だと変数hashはハッシュ生成関数としてg_string_hash、等価判定関数としてg_string_equalを使ってる。
g_string_equalはオブジェクトが違っても、表示される文字列が同じな場合TRUEを返す。
ここでtexas_1とtexas_2と言う変数2つは文字列としては同じだが、違うオブジェクトだ(と言う事は専有してるメモリの位置が違う)。
g_hash_table_insertはあくまでg_hash_table_equalに従ってkeyとvalueを挿入する。つまり、texas_1とtexas_2の見分けは付かないので"Austin"は"Houston"と交換されるが、ハッシュテーブルとしての束縛先(key)はtexas_1となるわけだ。
一方、g_hash_table_replaceはkeyも含めてオブジェクトを丸ごと取り替える。つまり、「文字列としては同じな」texas_1をtexas_2と入れ替える、と言う事だ。
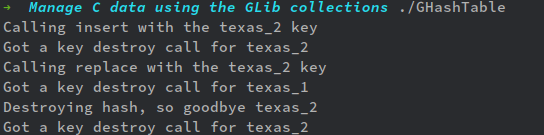
上のコードだと、key_destroyed関数は単なる出力関数だが、結果、本当だったら次のようなコードになるだろう。
次は、GHashTable用の副作用目的のマッピング関数、g_hash_table_foreachだ。
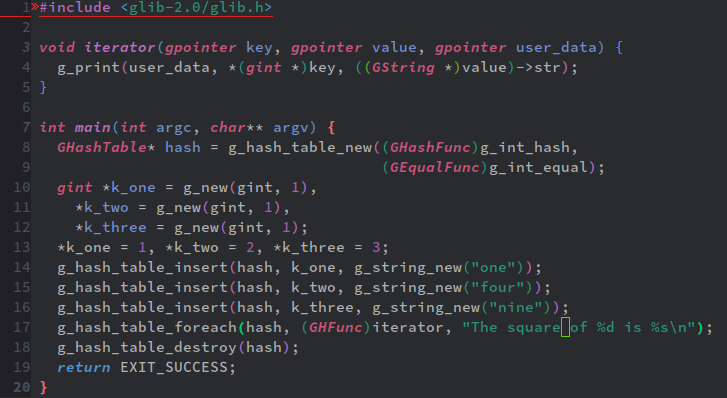
これはいいだろう。g_slist_foreachやg_list_foreachのハッシュテーブル版だ。コールバック関数としてはGHFuncへキャスティングする、って事だけが特徴となる。

次は、GHashTableから条件を満たすkeyとvalueの組を探すg_hash_table_findだ。
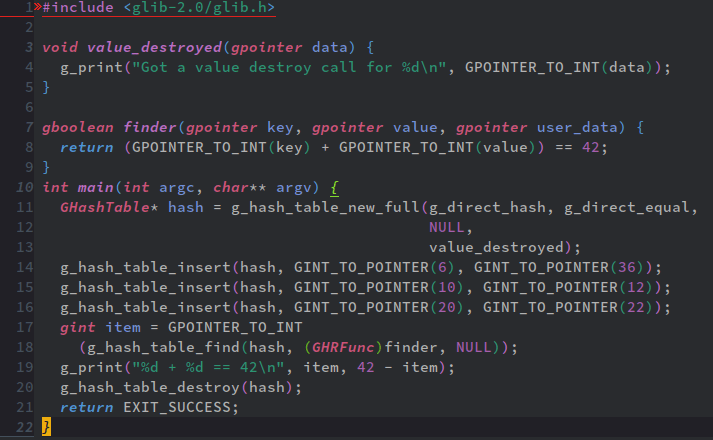
これもいいだろう。このコード上、GHashTableにはkeyが整数、valueも整数、と言うペアで、足して42になるペアを探しているだけ、だ。
ただ、g_hash_table_findの返り値はgpointerなんで、適切な型(この場合はgint型)にする為、型変換(GPOINTER_TO_INTマクロ)を要する。

次は、GHashTableから要素(keyとvalue)を削除する際のg_hash_table_removeの亜種を紹介する。g_hash_table_stealだ。
これは端的に言うと、GHashTableから要素を削除する際に、その要素をfreeしたくない時に使う。返り値はgboolean(真偽値)になる。
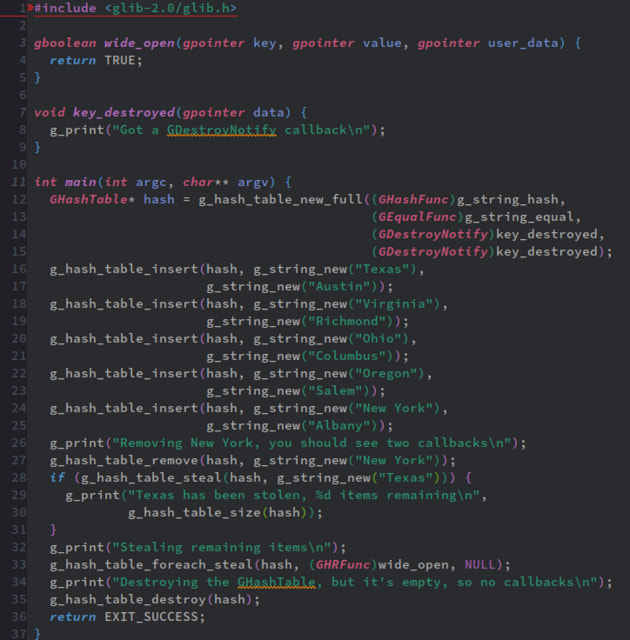
このコード例だと、キー"New York"をg_hash_table_removeで削除すると、keyとvalueに対してそれぞれコールバック関数として設定された出力関数key_destroyedが呼び出されて、2回メッセージが表示される(実用上はg_hash_table_fullの第三引数、第四引数にg_free系の関数を与えるトコだが)。
一方、キー"Texas"をg_hash_table_stealで削除するとコールバック関数が呼び出されない。つまり、実用的には、g_hash_table_fullの第三引数と第四引数にg_free系の関数を与えてもメモリの解放が行われない、と言う事だ。
GHashTableの外側で変数を定義し、それを利用したハッシュテーブルを作成し、その変数を使いまわししたい、と言う場合、メモリの解放は邪魔なので、それを避ける事が出来る、と言う事だ。
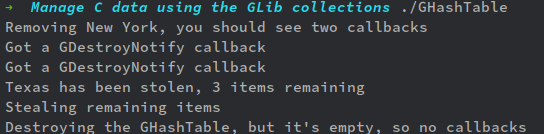
なお、g_hash_table_foreach_stealはGHashTableの全key & valueのペアに対して順次stealしていく高階関数だが、一種のフィルターで、第二引数に与えるコールバック関数がTRUEを返した時のみstealしていく。
つまり、第二引数に「stealしたいkeyとvalueの条件」を設定出来る、と言う事だ。
また、第二引数へ与えるコールバック関数は最大で二引数関数をやはり想定していて、そのコールバック関数の第二引数にg_hash_table_foreach_stealの第三引数が手渡される。
コールバック関数が一引数関数の場合は、g_hash_table_foreach_stealの第三引数にはNULLを与える。
そしてコールバック用にはGHRFuncと言う関数ポインタが用意されている。

次はg_hash_table_lookupの拡張版、g_hash_table_lookup_extendedについて、だ。

これはLispみたいな多値を返せるプログラミング言語の視点からすると何をやってんだかサッパリ分からんコードだ。
g_hash_table_lookup_extendedの返り値自体は真偽値(gboolean)なんだけど、Lispなら
(values key value)
と多値を返せるトコを、ポインタ変数を用意してそれらを破壊的変更した上で二値を返すように見せかける、と言うC言語ならではのトリッキーな解を行ってるわけだ。
結果、これはハッシュテーブルじゃないが、Lispで言うトコの連想リストに対するassocのような結果を出してるわけだ。
次は、keyに対して複数のvalueを与える、つまり、valueにGSListを用いたコード例だ。

まあ、これは「valueにGSListを使う事が辛うじて出来る」例、に見える。なんせ、GHashTableに「特定のvalueを与え」た後、それを探し、無理矢理g_slist_appendで別のvalueをくっつけてる」ようにしか見えない。
実は、実質的には、例えばPythonで言うと、
hash = {"Texas" : ["Austin", "Houston"], "Virginia" : ["Richmond", "Keysville"]}
と一行で済むのを何行にも渡り書かねばならないのがC言語様式だ、と言う言い方が出来る。
結局、これはやっぱ自分でユーティリティを書いて、圧縮出来るトコはした方がいい、って事かもしんない。
例えば次のようなユーティリティを書いてみる。

そうすれば、前に書いたユーティリティ、g_slistと合わせれば、

と、本体の記述量を若干減らす事が可能となる。

※1: 厳密に言うと、Ruby及びJavaScriptでは、「ハッシュテーブル」ではなく、「連想配列」と呼んでいる。
仕様書そのものを見たわけではないが、一般に、「連想配列」と言った場合、keyとvalueのペアを保持する配列、と言う意味で、keyを指定したら特定のvalueを返せ、と言うのが仕様上の定義だろう。
結果、「公式仕様が存在する」この2つの言語の場合、その「実装」をハッシュテーブルにするかどうか、と言うのは実装側の決定になる、と言う事だと思う。
そのせいで、JavaScriptやRubyの「連想配列」をハッシュテーブルとする、しない、と言うのは解説書によってマチマチだったりするわけだ。
(その辺、逆に「実装方法を指定している」Common Lisp/ANSI Common Lispの方が珍しいかもしんない)
※2: どのみち結果的には、Javaのように「値の型」も一致してなければならないが。
と言うのも、値も結果的にvoid*型になっていて、建前上は「どんな値も格納出来る(指せる)」んだけど、プログラミング上、「どの型か」確定させるのはプログラマ側の仕事になるんで、プログラム実行中に「void*が指してるアドレス」がどんな型を想定してるのか、リアルタイムでプログラマが指定する事が出来ない以上、「ハッシュテーブルの値の型は全部同じだ」とした方が良い事になる。
また、ハッシュテーブルを関数に仕込んで使うにせよ、関数側が「型の一致」を要求する、と言う理由もある。
※3: そういう意味で言うと、Scheme実装ではないRacketが非破壊的なハッシュテーブル、なぞ備えてるのは珍しいかもしんない。